论文:RELIC: Investigating Large Language Model Responses using Self-Consistency
作者:FURUI CHENG, VILéM ZOUHAR, SIMRAN ARORA, MRINMAYA SACHAN, HENDRIK STROBELT, MENNATALLAH EL-ASSADY
发表:arXiv 2023.11
大型语言模型(LLMs)因其将事实与虚构内容混合生成虚假的信息,即所谓的幻觉问题而臭名昭著。在此之前有许多工作基于Token级别的概率,以及模型内部可视化来解释幻觉问题并引导解决幻觉问题。但文章作者认为仅从Token级别理解和解决幻觉问题是不合适的,因为一些语义相近或者相同的语句其表述方式可能是完全不同的。为了解决语义级别上的幻觉鉴定问题,作者提出了一种新的互动系统RELIC,使用户能够检查和验证多个长篇回复中的语义级别变化并做出干预。并且RELIC使用一致性检验来判断模型对生成内容的“信心”,以求解决模型生成虚构内容的问题。最后,通过对十名参与者进行的用户研究,作者证明了RELIC系统有助于用户更好地验证生成文本的可靠性。
背景介绍
LLMs以将事实与虚构混合并生成非事实内容而臭名昭著,这被称为幻觉。尽管内容是虚假的或没有充分的来源支持,但它通常以一种令人信服和流利的方式呈现。这些看似真实和有说服力的陈述可能会误导用户,并引发法律和道德问题。防止用户被幻觉所误导已经成为研究人员和模型开发者面临的最紧迫问题之一。
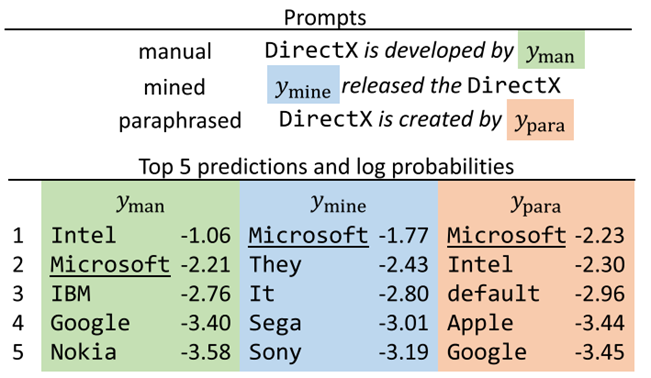
先前的人机交互研究发现,显示模型的置信水平(通常用分数或分数区间表示)是帮助用户做出正确决定的有效方式。这个想法可以扩展到自然语言生成(NLG)任务。直观地说,如果语言模型对相同提示或问题提供不一致或矛盾的响应,这表明缺乏可靠性。在这种情况下,用户应该忽略生成的内容,因为它不太可能是真实的如下图模型生成。

为了帮助理解和解决幻觉问题,作者提出了RELIC,一个交互式系统,建立在一种新颖的自一致性检查算法之上,它可以帮助LLM用户通过理解多个响应之间的一致性来识别和引导生成文本中的不可靠信息。
相关工作
语言生成过程中的事实验证
- 用从外部知识库中检索的证据来验证模型的输出(外部资源,不总是准确且及时更新)
- 大量先前工作集中在衡量和校准模型在生成过程中的置信度
- 通常设计用于具体的分类或自然语言推理任务,其中输出只包含单个标记
- 语言模型在多项选择和判断对错问题上的校准性较好,当涉及到长文本时,复杂度增加
- 用户对评估模型对语义含义的置信度更感兴趣,而不仅仅是标记
- 语义不确定性度量
- 使用一个离线自然语言推理模型来表征给定相同提示的多个生成响应之间的变化。语义不确定性度量已被证明在问答任务中有效
- 无法支持逻辑关系更为复杂的长篇生成
- 将生成的文本分解为原子主张并对其进行逐个验证的评估框架
自然语言生成应用中的人-LLM交互
先前的研究表明,可控性和透明度是构建负责任人工智能系统的两个重要支柱
大多数现有研究通过提供解释来实现透明度目标
一种常见的方法是允许用户(主要是专业模型开发者)查看模型内部并了解模型的机制(当语言模型大小和复杂性增加时,通过内部视图理解模型机制变得困难)
另一种方法是使用不同的提示来探索语言模型的输入-输出关联(与模型无关的方法主要设计用于分类任务,比如情感分析。将这些方法扩展到解释长篇文本生成仍然是一个未决问题)
本文的研究针对一个不同的问题,作者旨在帮助用户获得更权威的回答和可控性,以理解和引导LLM可能产生的幻觉性响应
形成性研究
人员
招募了五名参与者(年龄25-33岁、在日常生活中使用LLM)
- 一名记者
- 两名攻读商业博士学位的博士生
- 两名自然语言处理研究人员
形式
形成性研究包括三个会话,每个参与者总共持续一个小时
- 第一个会话收集了人口统计信息,并提供了背景和研究目的。
- 第二个会话包括三个问答任务,侧重于不同的主题。
- 主题和问题是从Wiki-Bio数据集中选择和形成的,比如一个名人的传记或一个组织的历史,展示了GPT-3在生成信息方面不同的准确性水平。
- 参与者被告知模型可能会生成不忠实的信息,并被鼓励验证多次生成的答案。之后,他们被要求指出他们对自己回答的信心水平
- 在最后一个会话中,作者对用户进行了半结构化访谈,以了解他们在研究过程中面临的挑战以及其理由。此外,作者询问了用户对更高效系统的期望功能
结果
Token 概率视图的不足
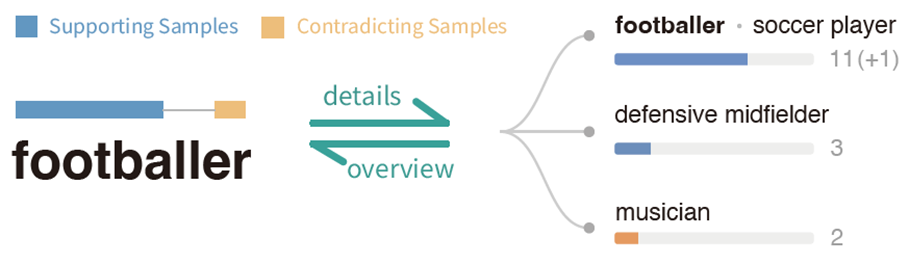
- 仅凭对数概率就无法证明模型在语义上的信心。低对数概率的令牌并不一定意味着在语义上缺乏信心。有时候,可能只是措辞上的问题。同样的语义可以不同的表达方式(如足球球员、足球运动员)
- 仅从概率角度出发,对于低概率的关键词没有给出替代选项作为对比

- 对比多个文本比较有挑战
- 用户表示比较多个样本并不容易,即使给了十个样本也只会随机选择三个进行检查
- 上下文信息帮助用户证明可靠性
- 用户对上下文信息敏感,当用户看到模型对关键信息(如:职业)没有信心,则对模型生成的其他文本也会产生怀疑
- 参与者不仅验证相应的句子,还阅读上下文并双重验证相关声明的可靠性,比如用户表示如果模型对电影名称有信心,就更加确信模型对职业描述是正确的
- 用户对不同程度的不一致性容忍程度不同
- 一些用户比较敏感,P1拒绝了只偶尔出现在样本中的声明,即使他们没有找到相矛盾证据
- 一些用户容忍程度比较高,P4和P5选择在找到更多支持证据而非相矛盾证据时,在一定程度上相信模型。
设计要求
- 在语义层面上测量置信度(Token不足)
- 在文本中注释置信度以便上下文理解(多文本对比困难)
- 灵活的交互以选择主张(多文本对比困难)
- 将置信度分数与证据相链接(上下文验证可靠性)
实现上面的设计需求,就需要一个自洽性评估算法生成证据分类
自洽性算法
Pipeline
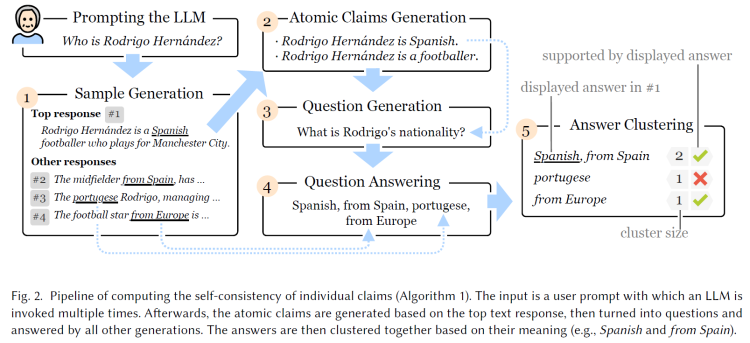
整个流程可以分为三个大部分
- 语义置信度设计(1)
- 长文本拓展设计(2)
- 证据连接设计(3,4,5)
语义置信度
Finding
从语言学角度来看,具有不同标记和语法结构的句子仍然可以表达相同的含义(例如,football player和soccer player)。因此,仅仅通过计算接下来几个词的概率来衡量语言模型的置信度是不够的
从语言模型解码是一个具有许多可用策略的随机过程(例如top-p、top-k、温度缩放等)。所有这些策略通常使用一些变体的束搜索,试图找到在上述添加的随机性下最大化概率的输出。因此,多次调用语言模型可能会产生不同的输出。
解决方案
作者参考前人工作 中的语义不确定性概念,使用相同提示使用语言模型生成多个样本,并将它们与焦点文本(主要用于分析的文本)生成进行比较
长文本拓展
Finding
- 上述方法的主要局限性是在处理长篇或语义丰富的自然语言生成时缺乏可扩展性。当生成的文本变得更加复杂时,很少会出现两个生成的文本传达完全相同的含义
- 对于长篇文本来说,单一状态无法充分描述它们的逻辑关系
- 即使一个看似不复杂的句子也可能由许多原子主张组成

解决方案
将文本分解为原子主张(InstructGPT实现)
Prompt:

证据连接
Finding
仅凭置信度分数可能并不总是直观或易于理解给用户
应该使用户能够轻松地访问其他样本中包含支持或相互矛盾信息的句子。特别是当一个原子主张缺乏大多数样本的支持时,应该提出替代可能性
解决方案
- 生成原子主张对应的问题
- 使用InstructGPT模型从每个主张生成(例如What和When)自然语言问题
- 使用这些问题来检索有关每个信息片段(即原子主张)的所有可能答案
- 使用离线问答(QA)模型验证问题的可回答性
prompt:

- 答案查询
- 利用上述QA模型从不同样本中获取多个答案
- 根据QA模型提供的答案和文本位置确定包含相关信息的句子
- 比较答案
- 使用自然语言推理(NLI)模型测量每对答案之间的蕴涵关系

自洽性算法伪代码

视图设计
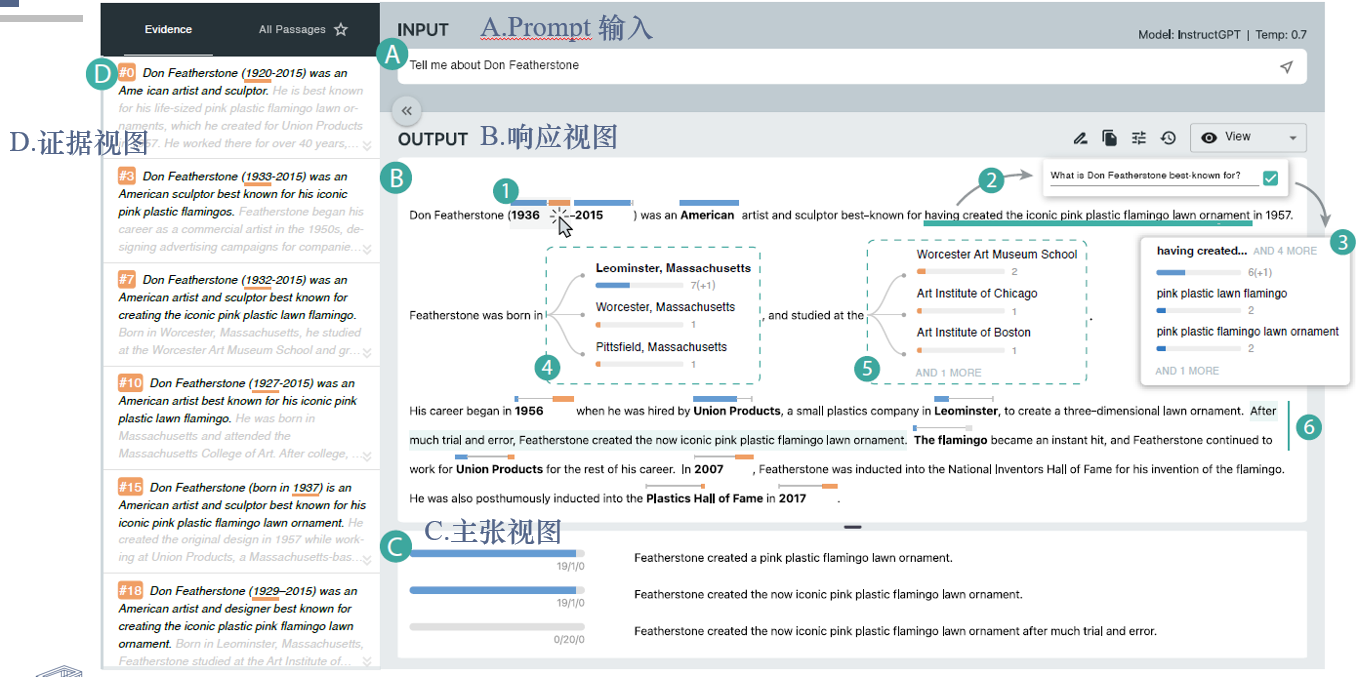
响应视图
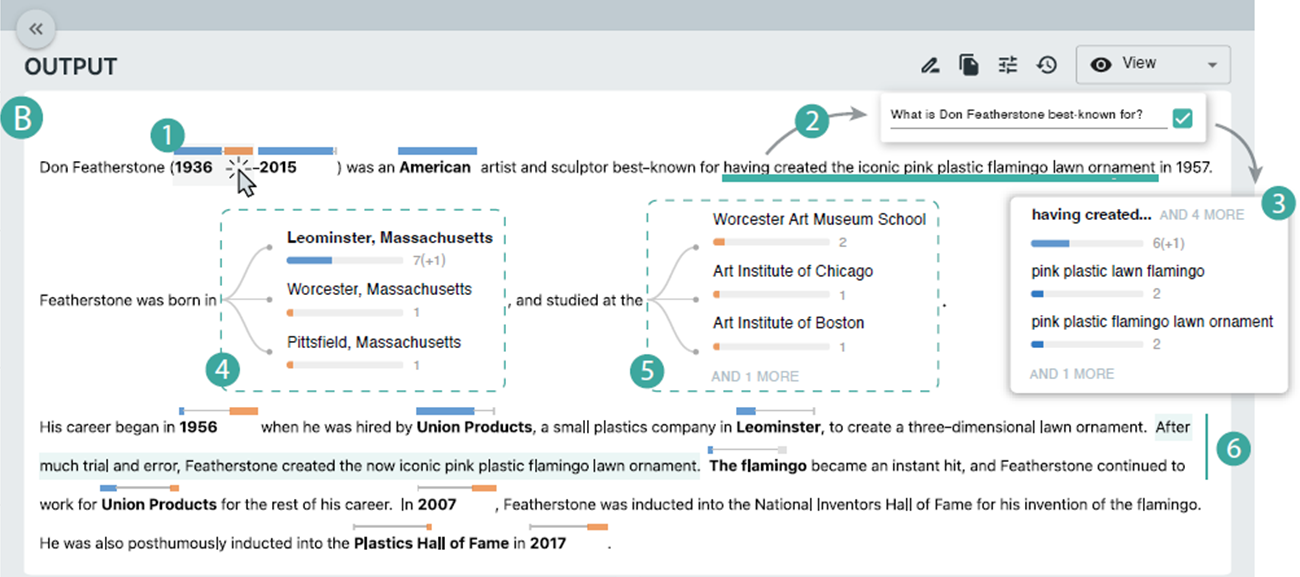
关键词注释(1,4,5)
条的长度体现支持(蓝)、相互矛盾(橙)和中立替(灰)代方案的样本比例(1)
单机注释可以检查替代方案的详细内容(4,5)
提问刷选(2,3)
用户可以自己刷选感兴趣的信息,系统根据刷选提出问题建议(2)
使用该问题在所有样本中搜索答案,并根据结果创建一个新的关键词注释(3)
编辑问题(6)
- 用户可以编辑文本生成新的验证(6)
主张视图

从生成的文本中得出的基本主张,作为参考帮助用户修改生成内容
对于每个单独的主张,呈现了支持、反对和中立样本的数量和对应视图
- 蓝色-支持、灰色-中立、橙色-反对
长文本包含大量主张
- 支持与响应视图联动,可以点击句子来过滤所有该句子派生的主张
证据视图
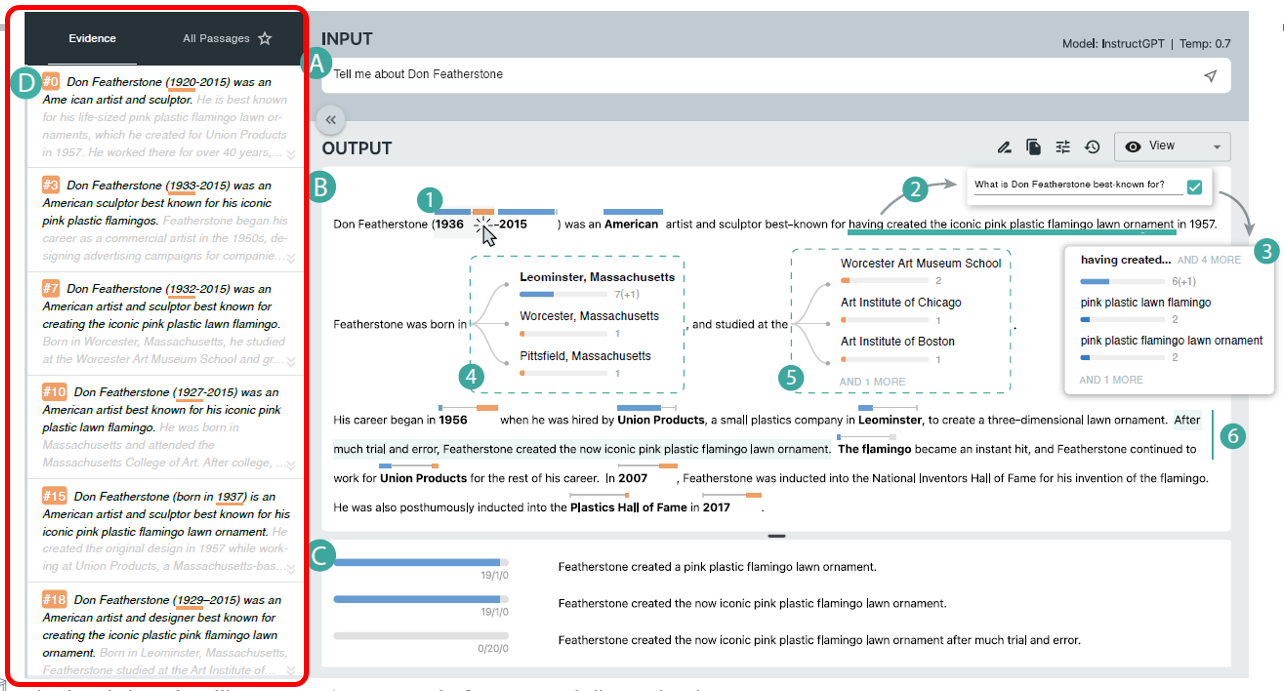
- 段落模式
- 用户可以查看所有样本的完整内容。用户可以选择关键词选项和主张来查询证据。
证据模式
- 系统仅保留相关的样本。例如,当用户选择“足球运动员”选项时,证据视图将只显示隐含包含“足球运动员”或语义上等价的词语的样本。
系统会突出显示支持或者反驳焦点句子或关键词的句子或词语
Case Study
假设场景
- 大卫正在写一篇关于“有趣的雕塑” 的文章,并正在搜索相关的报道和故事。在他的研究过程中,他遇到了一个他不熟悉的名字 - Don Featherstone。
- 他去了IntructGPT并输入了问题:“Tell me about Don Featherstone”
- 大卫阅读了整段文字。基于模型生成的第一印象,他评论道:“内容似乎连贯而且合理。” 然后他意识到生成的信息可能不准确
- 他通过查看带有注释的文本开始了调查。在检查时,他发现特定关键词,主要是来自段落前部分的关键词,比如“2015”、“美国”和“Union Products”,被标记为蓝色条,表明模型对这些信息的准确性非常确定。
- 其他关键词的注释要么有一个显著的橙色条,要么几乎没有支持。然后大卫决定逐个检查没有支持的关键词。
- 检查证据。他首先检查了Featherstone的出生年份,根据顶部回复是“1936”。 “看起来这个信息是有争议的。让我们看看其他样本怎么说。” 点击注释中的橙色条后,大卫在证据视图中查看了其他样本对这个人出生年份的相互矛盾的陈述
- 他注意到关于这个人出生年份的其他陈述是多样的,从1920年到1933年不等。大卫评论道:“如果我必须选择,我会选择1936,因为超过一半的样本支持这个数字”,并决定相信顶部回复。
- 然后大卫检查了剩下的句子。他发现句子提到了这个人的成就的重要信息(“以…最著名”),但系统没有自动突出显示。他记得有刷选问功能,并使用此功能选择了感兴趣的文本段(“创作标志性的粉红色塑料火烈鸟草坪装饰品”)。
- 两秒后,他看到推荐的问题,“Don Featherstone以什么著名?”(图中2)并确认了它。几秒钟后,他收到了其他样本提供的替代答案
- 他注意到答案都是关于Featherstone创作的粉红色塑料火烈鸟,尽管它们有不同的语法结构。大卫评论道:“我对这个陈述非常确定”,并确认了这个句子。
- 大卫继续检查第二个句子。在这个句子中,他发现有关Featherstone出生地和教育经历的信息被突出显示。“出生地和学校是相关信息,[所以我一起检查]”,大卫说。他点击并展开了两个关键词(图中4和图中5)
- 他首先注意到模型在某种程度上自信地预测这个人出生在“马萨诸塞州的Leominster”,但对这个人的学校则不确定。经过进一步检查,大卫注意到“Worcester”既出现在Featherstone出生地的选项中,也是一个学校名称。他说:“这加强了Featherstone出生在Worcester的可能性”
- 大卫决定对这个句子中提到的信息保持怀疑,并评论道:“我唯一确定的是这个人出生在马萨诸塞州。” 他简化了句子为“Featherstone出生在马萨诸塞州”。根据上下文做判断。大卫继续审阅和编辑剩下生成的内容。
- 由于缺乏其他样本的支持,他删除了第三个句子中的“在1956年”。对于接下来的句子(“经过多次尝试和错误…”,图中6),大卫注意到没有任何关键词被突出显示。所以他决定调查并点击了这个句子,这带来了声明列表(图中D)
- 经过审查,大卫发现这个句子中三个声明中有两个得到了大多数样本(20个中有19个)的支持。第三个声明是第二个声明的延伸,包括短语“经过多次尝试和错误”。
- ”【第三个声明】有道理。我相信它是真实的[尽管没有支持样本]”,大卫说,并确认了这个句子。在剩下的时间里,大卫验证了最后三个句子。由于缺乏支持,他删除了提到Featherstone被引入国家发明家名人堂的“2007年”这个短语以及最后一个句子。
User Study
人员
十名LLM用户
结果
验证和纠正生成文本
所有参与者都认为支持样本的数量是他们做出论证的最重要的视觉线索
用户经常使用上下文信息来判断某些信息的真实性
与传统LLM界面的比较
更易获得的替代性回应
允许用户与生成的文本进行交互
可用性和实用性
所有参与者都发现系统易于使用(5.70±1.00)、易于学习(5.70±1.27)和使用愉快(5.90±0.94)
不过对使用系统的信心表达不同意见(4.60±1.36)
关键词标注和替代选项比较关键
主张视图和证据视图比较不实用
总结
贡献
- 形成性研究,阐明了当前LLM界面在指示生成文本可靠性水平方面的不足,并帮助制定了设计以用户为中心的自然语言生成验证系统的要求。
- RELIC,一个交互式系统,帮助用户通过调查多个样本的事实一致性来验证和引导语言模型生成的自然语言生成。
- 与十名参与者进行的用户评估,展示了所提出方法的有效性,并为未来的人机交互研究带来了见解。
局限性
增加技术复杂性,使得使用费用增加生成速度降低
只有在模型训练数据中有ground truth使用这个系统才有意义(原创睡前故事用该系统无意义)
依赖自洽性来衡量真实性,对个别声明的真实性无法保证
未来工作
量化验证该系统帮助对用户的帮助
引入外部数据,对外部数据有意的错误和脱离上下文信息的数据进行检测
多模型和多提示扩展
✉️ zjuvis@cad.zju.edu.cn