教程引用自 https://www.runoob.com/regexp/regexp-tutorial.html 菜鸟教程-正则表达式
推荐的教程:https://deerchao.cn/tutorials/regex/regex.htm 正则表达式30分钟入门教程
推荐的测试网站:https://regexr.com/
背景
正则表达式(Regular Expression, Regex)是一种复杂但强大的字符串匹配机制。虽然没有系统的学习过,但我们可能很早以前就试过使用 ? 和 * 通配符来查找硬盘上的文件,这就是正则表达式的基础版本。
? 通配符匹配文件名中的 0 个或 1 个字符,而 * 通配符匹配零个或多个字符。 像 data?.dat 这样的模式将查找下列文件:
- data.dat
- data1.dat
- data2.dat
- datax.dat
- dataN.dat

使用 * 字符代替 \? 字符扩大了找到的文件的数量。data*.dat 匹配下列所有文件:
- data.dat
- data1.dat
- data2.dat
- data12.dat
- datax.dat
- dataXYZ.dat

尽管这种搜索方法很有用,但它还是有限的。通过理解 * 通配符的工作原理,引入了正则表达式所依赖的概念,但正则表达式功能更强大,而且更加灵活。正则表达式的使用,可以通过简单的办法来实现强大的功能。下面先给出一个简单的示例:搜索以数字开头,abc结尾的字符串(或者文件名)。
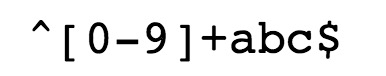
^为匹配输入字符串的开始位置。
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
方括号代表一个字符的集合,匹配括号里面的任意一个字符。
abc$$$ 匹配字母 abc 并以 abc 结尾,$$$为匹配输入字符串的结束位置。
测试网站:
https://regexr.com/
测试表达式:
\^[0-9]+abc$
测试文本:
123abc
123ab
1bc
bcd
123abcd
请打开测试网站https://regexr.com/,将“测试表达式”复制在上方表达式区域,将“测试文本”复制在下方的文本区域,并在右侧打开多行(multiline)开关。
结果例子如下:
为什么使用正则表达式?
典型的搜索和替换操作要求您提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。
通过使用正则表达式,可以:
- 测试字符串内的模式。例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。
例子:如果你的数据是txt形式存放的,里面有100w条数据,但是可能里面有些数据的格式是无效的。你可以写一个正则表达式来读取每一行,只有和你的模式匹配的数据才会被使用,其他的可以丢弃,而不用担心程序崩溃。
- 替换文本。可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
例子:如果你想把文档里所有“xxxx年x月x日”改为”x.x.xxxx”, 你准备怎么替换呢?正则表达式可以帮你。
- 基于模式匹配从字符串中提取子字符串。可以查找文档内或输入域内特定的文本。
例如,您可能需要搜索整个网站,删除过时的材料,以及替换某些 HTML 格式标记。在这种情况下,可以使用正则表达式来确定在每个文件中是否出现该材料或该 HTML 格式标记。此过程将受影响的文件列表缩小到包含需要删除或更改的材料的那些文件。然后可以使用正则表达式来删除过时的材料。最后,可以使用正则表达式来搜索和替换标记。例子如下图


发展历史(百度百科)
正则表达式的“鼻祖”或许可一直追溯到科学家对人类神经系统工作原理的早期研究。美国新泽西州的Warren McCulloch和出生在美国底特律的Walter Pitts这两位神经生理方面的科学家,研究出了一种用数学方式来描述神经网络的新方法,他们创造性地将神经系统中的神经元描述成了小而简单的自动控制元,从而作出了一项伟大的工作革新。
在1951 年,一位名叫Stephen Kleene的数学科学家,他在Warren McCulloch和Walter Pitts早期工作的基础之上,发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来描述此模型,引入了正则表达式的概念。正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式,因而采用了“正则表达式”这个术语。
之后一段时间,人们发现可以将这一工作成果应用于其他方面。Ken Thompson就把这一成果应用于计算搜索算法的一些早期研究,Ken Thompson是 Unix的主要发明人,也就是大名鼎鼎的Unix之父。Unix之父将此符号系统引入编辑器QED,然后是Unix上的编辑器ed,并最终引入grep。
grep [regex] [filename]
自此以后,正则表达式被广泛地应用到各种UNIX或类似于UNIX的工具中,如大家熟知的Perl。
正则表达式语法
注:下面的语法其实是一个一个的小测试。
请打开测试网站https://regexr.com/,将“测试表达式”复制在上方表达式区域,将“测试文本”复制在下方的文本区域,并在右侧打开多行(multiline)开关。
01
^ 表示字符串的开头, $表示字符串的结尾
测试表达式:
^once
测试文本:
once upon a time
There once was a man from NewYork
测试表达式:
bucket$
测试文本:
Who kept all of this cash in a bucket
buckets
测试表达式:
^bucket$
测试文本:
Who kept all of this cash in a bucket
buckets
bucket
测试表达式:
bucket
测试文本:
Who kept all of this cash in a bucket
buckets
bucket
02
方括号代表一个字符的集合,匹配括号里面的任意一个字符, 如[a-z], [a-zA-Z]
测试表达式:
[AaEeIiOoUu]
注:所有元音字母
测试文本:
Who kept all of this cash in a bucket
buckets
测试表达式:
[a-zA-Z]
注:所有大小写英文字母
测试文本:
hello123World
测试表达式:
[XYZabcde0-9]
注:所有大写XYZ,小写abcde和数字0-9
测试文本:
hello123World
测试表达式:
[a-z][0-9][a-z]
注:一个小写字母,一个数字和另一个小写字母紧挨着
测试文本:
hello123World
hello1wor2l3d
测试表达式:
[A-Za-z0-9_] / [\w]
注:一个字符,数字或者下划线。\w为任意数字或字母的通配符,相当于a-zA-Z0-9_。
与此相对,\d为数字的通配符,相当于0-9。
测试文本:
hello123_World
hello1wor2??l3d
03
如果方括号内部首位出现了一个^符号,代表取除了这个字符集合外的其他元素(取反)
测试表达式:
AaEeIiOoUu
注:除了所有元音字母以外的所有字符
测试文本:
Who kept all of this cash in a bucket ???
buckets
04
花括号用于选择某个字符或者某个串出现的次数,比如:{2}(两次),{0,3} (0次到3次), {4,} (4次或以上)
测试表达式:
^a{4}$
注:仅匹配aaaa
测试文本:
aaa
aaaa
aaaaa
测试表达式:
^a{1,3}$
注:a,aa,或aaa
测试文本:
aa
aaa
aaaa
aaaaa
测试表达式:
^a{2,}
注:以至少两个a开头的文本
测试文本:
a123
aaa123
123aa123
a1a23
测试表达式:
^.{3,5}$
注:.为所有字符的通配符,表示长度为3-5的任意串
测试文本:
a123
aaa123
123aa123
a1a23
05
* 代表出现0次或多次, +代表出现1次或多次,? 代表出现0次或1次
测试表达式:
^a{1,}$
测试表达式2:
^a+$
注:+ 和{1,} 作用完全相同
测试文本:
aa
aaa
aaaa
aaaaa
测试表达式:
da{0,1}ddy
测试表达式2:
da?ddy
注:? 和{0,1} 作用完全相同
测试文本:
daddy
dddy
ddday
06
圆括号可以把表达式分组成为一个整体
测试表达式:
^(ab)+$
测试文本:
abababab
aaabbb
Yabab
测试表达式:
^(ab)+(cd)*$
测试文本:
abababab
cdcdcd
abc
abcd
ab
07
综合测试
所有正整数:
[1-9][0-9]*
所有整数:
[-]?[0-9][0-9]*
[-]?[0-9]+
所有浮点数:
[-]?[0-9]+(\.[0-9]+)?
注:一个可选的负号,一定有的小数点前面的若干位,不一定有的小数点后面的若干位
用户密码设置:
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符 -,并设置用户名的长度,我们就可以使用以下正则表达式来设定。
方括号代表一个字符的集合,匹配括号里面的任意一个字符。
花括号用于选择某个字符或者某个串出现的次数,比如:{0,3} (0次到3次), {4,} (4次或以上)
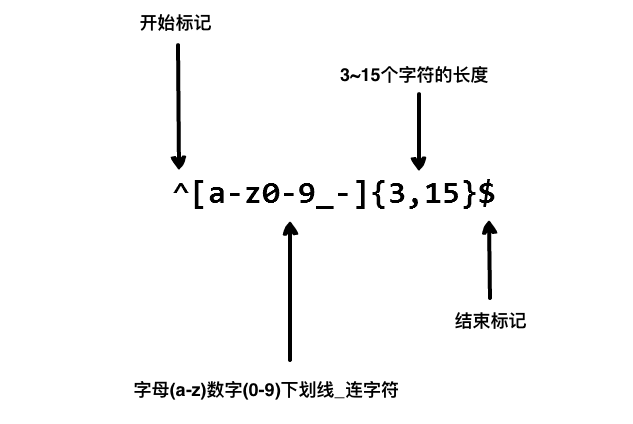
以上的正则表达式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因为它包含的字母太短了,小于 3 个无法匹配。也不匹配 runoob$$$, 因为它包含特殊字符。
测试表达式:
\^[a-z0-9_-]{3,15}$
测试文本:
runoob
runoob1
run-oob
ru
runoob$
1 |
进阶
01
断言:提前预设某个位置之前或者之后会出现某种模式。
(?<=exp1)exp2
注:找一个exp2,他的左侧必须是exp1
exp2(?=exp1)
注:找一个exp2,他的右侧必须是exp1
注:在某一个 > 右侧, 另一个 < 左侧,找至少一个不属于< >的字符。这样就找到了html所有标签外侧的值。
注:在某一个 < 右侧, 另一个> 左侧,找至少一个不属于< >的字符。这样就找到了html所有标签内侧的值。
断言匹配的是某些位置间隔,而不是字符本身。“位置”指的是字符串的开头、结尾,或者任意两个字符中间的间隔(没有宽度)。由于这些间隔没有宽度,也被称为零宽断言。
正向(positive)先行(lookahead)断言:
exp2(?=exp1)
实际表示:寻找一个位置,这个位置右侧是exp1。在此之上,让exp2处在这个位置左侧。如图,(?=gular)表示gular之前的间隔, expression中的re并未被匹配。

将表达式改为 re(?=gular). (后面多了个.通配符),那么匹配到reg,其中.匹配g

正向(positive)后行(lookbehind)断言:
(?<=exp1)exp2
实际表示:寻找一个位置,这个位置左侧是exp1。在此之上,让exp2处在这个位置右侧。
负向断言
即把正向断言中的 = 等号变为 ! 叹号。表示查找某些位置,这个位置不满足某些规则。
负向(negative)先行(lookahead)断言:
exp2(?!exp1)
实际表示:寻找一个位置,这个位置右侧不是exp1。在此之上,让exp2处在这个位置左侧。
负向(negative)后行(lookbehind)断言:
(?<!exp1)exp2
实际表示:寻找一个位置,这个位置左侧不是exp1。在此之上,让exp2处在这个位置右侧。
例子:下面的例子匹配了所有不在单词开头的re。(?<=\w) 表示某个字符(a-zA-Z0-9)之后的间隔。

例子:下面的例子匹配了所有在单词开头的re。(?<!\w) 表示某个非字符之后的间隔。

匹配包含数字、字母和特殊符号,长度至少为8位的密码

测试表达式:
\^(?=.\d)(?=.\[a-zA-Z])(?=.*[~!@#$%\^\&*])[\da-zA-Z~!\@#$\%\^\&*]{8,}$
或者复制以下表达式:1
^(?=.*\d)(?=.*[a-zA-Z])(?=.*[~!@#$%^&*])[\da-zA-Z~!@#$%^&*]{8,}$
测试文本:
runoob
runoob1
run-oob
ru
helloworld!
helloworld43!
解释:至少使用断言,找到一个后面至少有一个数字,一个字母,一个特殊符号的空白。在这个空白之后,有8位字符,字符可选范围为数字、字母或特殊符号。
02
元组捕获:通过小括号括起来的表达式成为一个组,会从左到右依次保存在缓冲区中:之后,可以使用 \1, \2.. 来表示。
测试表达式:
\b([a-z]+) \1\b
测试文本:
Is is the cost of of gasoline going up up
注:\b表示单词的边界,如同 ^表示整个串的头部,$表示整个串的尾部一样。 \b在最前面表示单词的开始,\b在后面表示单词的结束。
本串的作用是捕获某个重复的单词。前面的([a-z]+)表示单词, 并且捕获成为组1; 后面再次使用它,表示连续的重复单词。

正则表达式的局限性
没有判断大小这种功能
如:表示-32768~+32767
(?:^|0-9-)(?:-[1-9]|-3276[0-8]|-?[1-9][0-9]{1,3}|-?[12][0-9]{4}|-?3[01][0-9]{3}|-?32[0-6][0-9]{2}|-?327[0-5][0-9]|[0-9]|3276[0-7])\b
需要把1位、2位、3位、4位、5位的数字全部拆开来写
各个语言的辅助功能
大部分语言,都可以直接分组捕获正则表达式内容,并且直接赋值给变量,非常方便。
例子:身份证 1102231990xxxxxxxx
1 | import re |
{'province': '110', 'city': '223', 'born_year': '1990'}
可以直接转为字典形式。
或者,直接在匹配时给出某个函数进行替换。
1 | import re |
A46G8HFD1134
附录:正则表达式语法检查表(需要的时候看一下就好)
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。 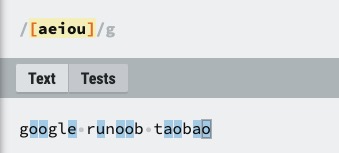
|
| [^ABC] | 匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母。 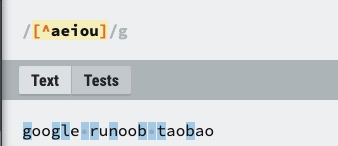
|
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。 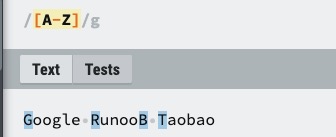
|
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。 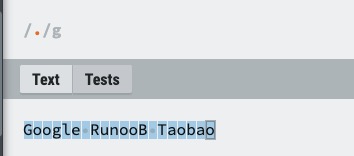
|
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。 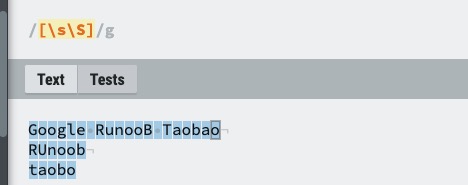
|
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] 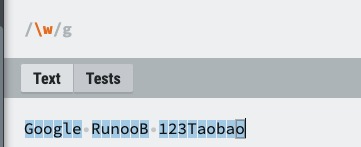
|
非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 *,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 \,runo\*ob 匹配字符串 runo*ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
| 特别字符 | 描述 |
|---|---|
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
修饰符
正则表达式的标记用于指定额外的匹配策略。标记不写在正则表达式里,标记位于表达式之外
正则表达式的修饰符有:
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
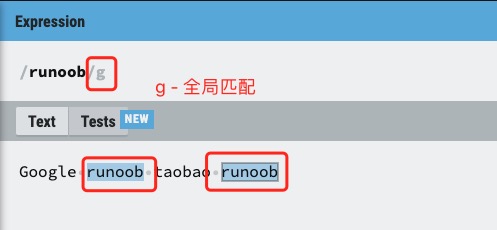
g 修饰符
g 修饰符可以查找字符串中所有的匹配项:
</div>
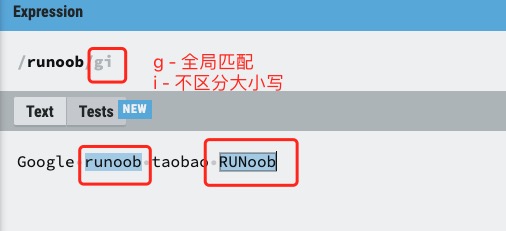
i 修饰符
i 修饰符为不区分大小写匹配,实例如下:
m 修饰符
m 修饰符可以使 ^ 和 $ 匹配一段文本中每行的开始和结束位置。
g 只匹配第一行,添加 m 之后实现多行。

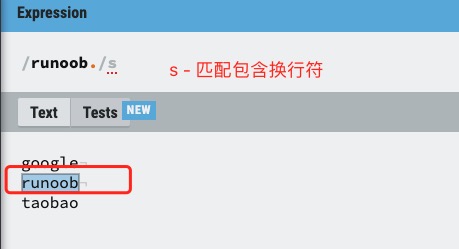
s 修饰符
默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 之后, . 中包含换行符 \n。
✉️ zjuvis@cad.zju.edu.cn