论文:Designing Interactive Transfer Learning Tools for ML Non-Experts
作者:Swati Mishra, Jefrey M Rzeszotarski
发表:Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. ACM, 2021
文章主要实现了面向非专家的支持迁移学习的交互式环境原型,通过用户研究非专家在使用过程中的信息搜索行为,结果揭示了一系列数据和感知驱动的策略,并从经验数据中提取的概念模型。
介绍
背景介绍
在除计算机领域外的医疗、金融、制造业有很多采用了机器学习,这推动了越来越多的交互式机器学习的研究,能够让不同的用户使用。交互式机器学习可以帮助用户把他们的知识整合到构建复杂的机器学习模型的流程中。目前的iML系统针对不同的任务,比如提高输入数据的质量,构建和分析模型、解释模型结果和评估模型的表现。然而大部分的研究都是面向专家用户,很少有iML工具帮助非专家用户将ML集成到他们自己的工作环境中。比如,app设计人员可能希望在用户上传内容后使用分类模型来识别其中敏感部分。对他们来说,学习和理解ML开发可能过于繁重。
→ 本文工作:构建探索交互式的环境,通过迁移学习重新利用现有的专家策划的模型组件来帮助非专家构建模型
迁移学习是通过相关模型特征的迁移,使在一项任务上训练的模型适应另一项使用更小的训练数据集的相关的任务的技术。但是迁移学习通常是一个专家工具因为它涉及到很多相互依赖的子任务,比如确认迁移的候选项、如何迁移、评估表现和确认后续步骤。举个例子,app设计人员需要在帖子提交前识别敏感内容,可以凭借他们对自己用户群独特的理解来选择和调整文本分类模型中的部件构建新的模型。
→ 本文工作:研究了支持迁移学习的交互式环境的设计,专注于CNN
贡献点
收集和研究用户行为,原型可在无专家监督的情况下构建和评估CNN模型。
研究检查非专家在迁移学习中的信息搜索行为,结果揭示了一系列数据和感知驱动的策略。
从经验数据中提取的概念模型,它指向系统的特定设计维度。
挑战
通过对6位专家的半结构访谈和文献分析,文章总结了迁移学习工作流中各个阶段所面临的挑战。在整个流程中,专家有三个共享的核心模式:选择,组装和诊断。还根据任务的性质对他们进行了编码。
- Functional—用户在执行任务时面临的挑战
- Conceptual—用户在解释候选和结果时面临的挑战
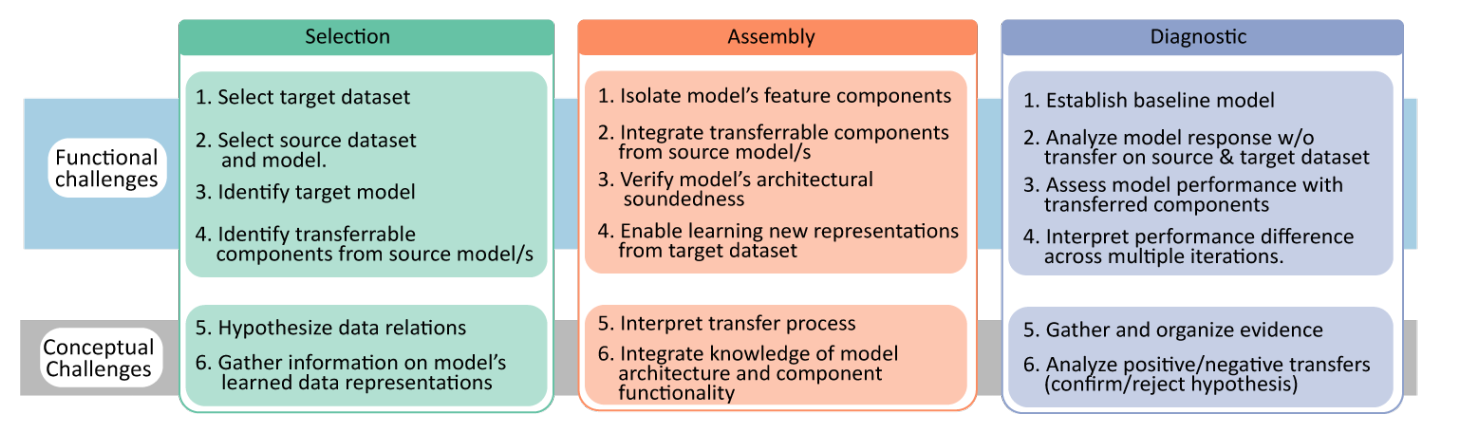
Selection选择
- 迁移学习工作流的第一步是识别高级(数据集和模型)和低级(模型组件)迁移候选对象。
- Functional—这需要克服选择可能与目标数据集 (S2) 相似的源数据集 (S1)、从“model-zoo”中选择模型 (S3) 作为源模型候选以及识别可以重新用于目标任务源模型组件 (S4)。
- Conceptual—此外,用户还需要解决生成潜在假设迁移机制 (S5) 和正确解释模型的学习表示 (S6) 。
Assembly组装
- 一旦确定了源模型和目标模型之间的潜在潜在机制场景,用户就需要实施转移。
- Functional—这包括从构建块构建功能有效的模型 (A3),识别源模型 (A1) 的不同部分,将部分正确地拟合到目标模型 (A2) 中,对目标数据集进行训练 (A4) 和控制迁移的组件是否也应该从目标任务中学习。
- Conceptual—用户还需要解决与解释迁移过程 (A5) 相关的挑战,并了解模型 (A6) 的任务执行过程,以便评估对目标模型的影响。
Diagnostic诊断
诊断迁移机制的成功和失败是迁移学习工作流程迭代性质的核心。
Functional—在这个阶段,用户建立模型性能的baseline (D1) 并单独评估模型的响应 (D2) 并与baseline进行比较 (D4) 。使用适当的指标检查实例级和类级性能 (D3) 也是用户在诊断过程中面临的挑战。
Conceptual—通常使用一种以上的技术来评估性能,因此从不同的诊断方法中组织证据对决策很重要 (D5)。在目标任务的上下文中为模型定义可接受的性能并相应地分析性能 (D6) 也是用户在此阶段面临的挑战。
原型系统
文章实现了一个原型系统InteracTL,针对的是单个简单的案例——英文笔迹分类。因为当前专家构建的英文手写字符分类模型已经有很高的准确性,这种“已解决”的案例能够保证为用户提供有效的功能单元来迁移。而且这个任务在视觉和文本分类的交叉点,是非专家的两个常见应用。用的数据是EMNIST 数据集,包含大小写英文字符和数字,尺寸很小使用浅层的CNN模型训练很快。

构建/调整模型
界面为用户提供了 3 种用于手写大写和小写英文字符和阿拉伯数字的预训练模型。用户可以拖放预训练模型中的任意部分作为building blocks构建新模型,后端自动设置需要的参数,允许用户控制过滤器大小、学习率和样本大小。同时验证用户创建的模型的架构和功能正确性,出错就会发出通知。
训练模型
用户可以根据需要配置他们训练数据集,也可以是特定的类别比如只在字母z上进行训练,用户也可以使用按钮阻止某些计算单元的学习。虽然在实践中训练工具应该允许更深层次的配置(例如允许用户选择损失函数、batch size等),原型的这些特征的选择过程是自动化,来帮助用户专注于高级任务。
模型测试
用户可以从测试数据集中选择特定类别的样本来测试模型性能,右侧的bar会实时显示当前图片预测的结果,这对发现模型的错误很有用。下方会显示整体的准确率。
检查输入
用户可以选择训练或测试数据集的样例进行分析,也允许用户自己绘制草图,或者是用遮挡工具隐藏样本的某些部分,观察特定场景下的模型性能。
检查模型
用户可以可视化选中层的过滤器,每个3*3的方格代表一个过滤器,颜色编码的是训练前后权重的变化的z-score,颜色越深代表学习到的越多。右边的每个方块代表过滤器对输入手写样本的响应。
检查输出
通过聚类视图和混淆矩阵呈现模型性能。集群视图使用 t-SNE显示类级集群。 混淆矩阵可以突出显示每个样本的小错误,可能表明模型中存在普遍问题。
用户研究
任务:设计小写英文字母分类模型
参与者:15位大学生(7男8女),年龄18-25岁,来自各领域背景,无机器学习经验,无编程经验
方法:访谈,交互日志(定量数据),Think-Aloud(定性数据)
结果
通过分析用户的交互日志,文章总结了三种模式及其状态流程图。状体流程图的六个圈代表之前提到的六个阶段,之间的连线代表用户在两个阶段之间切换的频率,线越粗代表切换的越频繁。
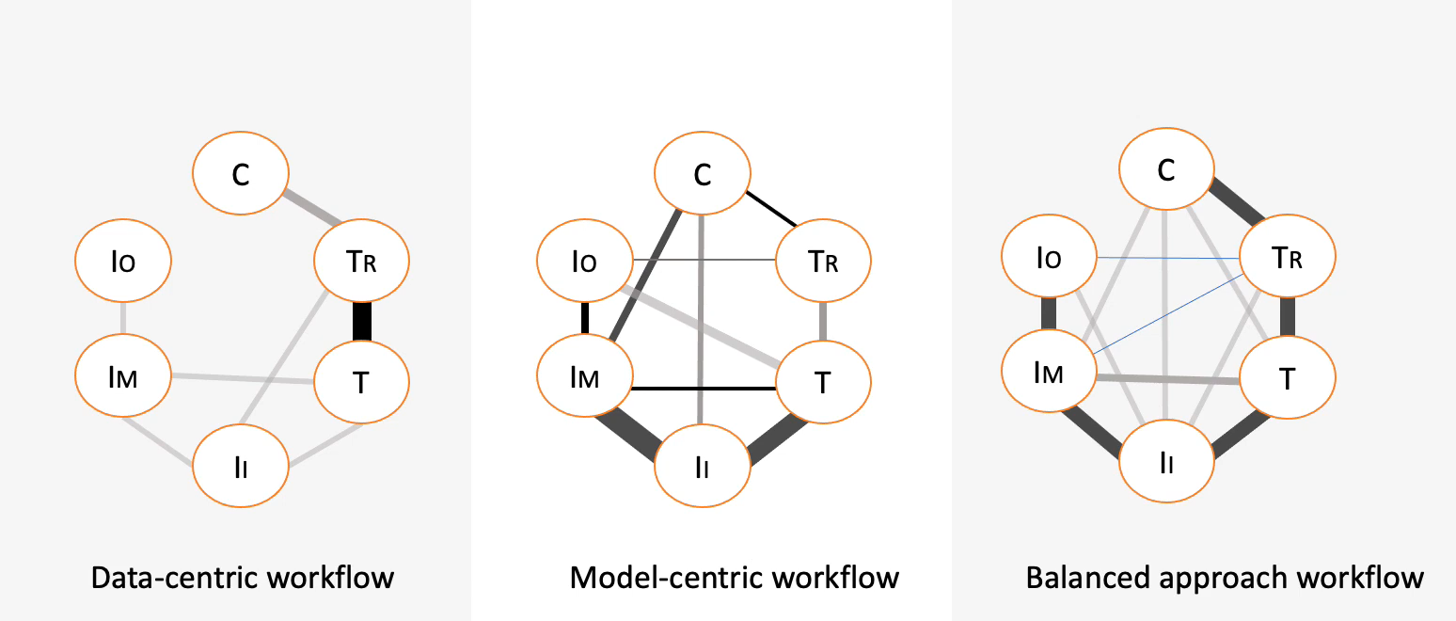
- Data-centric workflow:关注数据,模型不怎么变化;
- Model-centric workflow:更关注模型,在相同的数据上测试不同的模型;
- Balanced approach workflow:也有在这中间取得平衡的用户;
Observation1-参与者使用以模型为中心的假设分析来收集有关模型架构的信息。
对于专注于模型的参与者,他们的领域知识和任务之间的相似行决定了他们的迁移策略。比如任务是分类小写英文字母,他们大概率会选择识别大写字母的预训练模型的某个组件来构建自己的模型。然后他们使用假设分析来研究模型的当前状态,测试不同数据下模型的表现,多次迭代模型。
Implication1-对于 iML 系统的设计者来说,他需要去考虑如何提供工具来降低探索成本,并提供模型架构的准确含义。
Observation2-对学习过程的特定看法严重影响如何训练模型。
另外也观察到参与者对统计学习过程的特定看法在他们的决策中发挥了关键作用。像“我想看看它是否记得上次的事情”这样的评论表明参与者认为机器学习过程和人类学习过程相似的。他们认为模型训练是一种增量活动,即使用新数据重新训练,也会保留先前迭代的学习。虽然界面中有按钮来控制学习率但是很少人使用。如果模型每次训练迭代都删除了先前学习的权重,那么界面上应该有一些视觉的表现来告诉用户这种行为。
Implication2-需要仔细叠加模型的声明性知识的可视化与过程知识。
所以对于交互系统设计者来说,需要结合可视化和能够传递给用户系统实际行为的描述,来减轻这些误解,避免用户认为的和实际的之间的不符。
Observation3-过度依赖准确率,想通过模型的结果找到模式。
另我们的观察还表明,参与者过度依赖准确率数字,并且努力在正确和不正确的模型结果中找到模式。参与者认为准确率的 1-2% 变化足以证明迁移成功或失败,调试检查的工具通常都是在准确率率下降的时候使用的。整个过程是高度迭代的,准确率的变化随着时间的推移很难追踪的。会出现用户重建过去的模型或者是测试的情况。
Implication3-需要考虑如何更好地向用户展示历史数据和过程数据。
总结
不足
- 界面只适用于CNN模型的迁移学习
- 超参数硬编码,后端能处理的模型层数有限
- 图像/自然语言数据集类型比较直观,但纯数字的数据就会存在问题
- 样本都来自大学环境
- 任务的持续时间不够
未来工作
- 研究更复杂情况下的迁移学习
- 利用扩展的模型库
- 探索其他界面是如何偏离所观察到的流程模型
讨论
这篇文章与迁移学习相关的比较少,最后的用户研究的结论写的比较详细,总结的六步流程比较普适。
✉️ zjuvis@cad.zju.edu.cn