作者

单位:加州大学圣地亚哥分校 Department of Cognitive Science,微软PROSE组。
一作是博士生,三作是其导师
二作是研究员,四作是首席研究员,五作是PROSE组的leader
背景
Data wrangling
- 前期数据准备
- 消耗大量时间
Computational notebook,数据科学家经常需要使用的环境
一系列的“cell”用于input,output
Jupyter notebook
D3 Observable
挑战
微软专家的正式访谈中进行总结,现有的工具和数据分析师现实中的工作环境的gap
- 现有的data wrangling工具需要专家切换使用环境(notebook)
- 现有的工具不能整合进专家的工作环境,来完成监控检测转换过程。
现有的data wrangling 工具 需要专家切换使用环境 到其它的使用环境中
专家不希望其它的工具以一种黑盒的形式来处理自己的数据,他们希望可以检测转换过程,同时希望可以使用自己更熟悉的Python or R。同时希望结合这些工具到自己的工作环境中,可以保留数据转换的代码,又可以容易复现。
贡献
- 混合交互模型
- programming-by-example with readable code synthesis
- within the cell-based workflow of computational notebooks
- 程序合成
- 数据子集上进行代码合成,并应用到数据全局上
- 合成的程序可以合并在现有的数据处理中
- User Study
- 减少了用户数据转化函数使用中的查阅和回顾
- 合成的代码可以验证是否符合他们的预期,增加可信度
- 插入cell的形式很自然
使用场景
用户:专业的数据分析师
数据:911报警(经纬度,时间,标题等)
任务:开放式探索
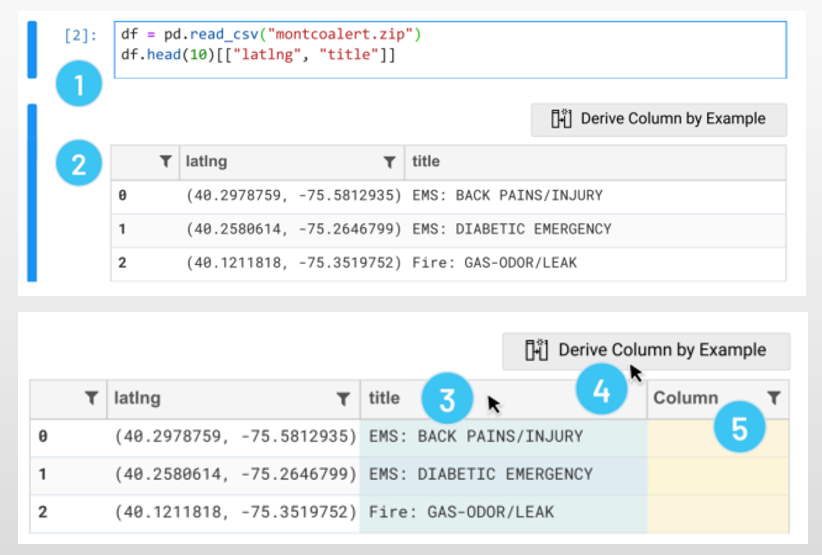
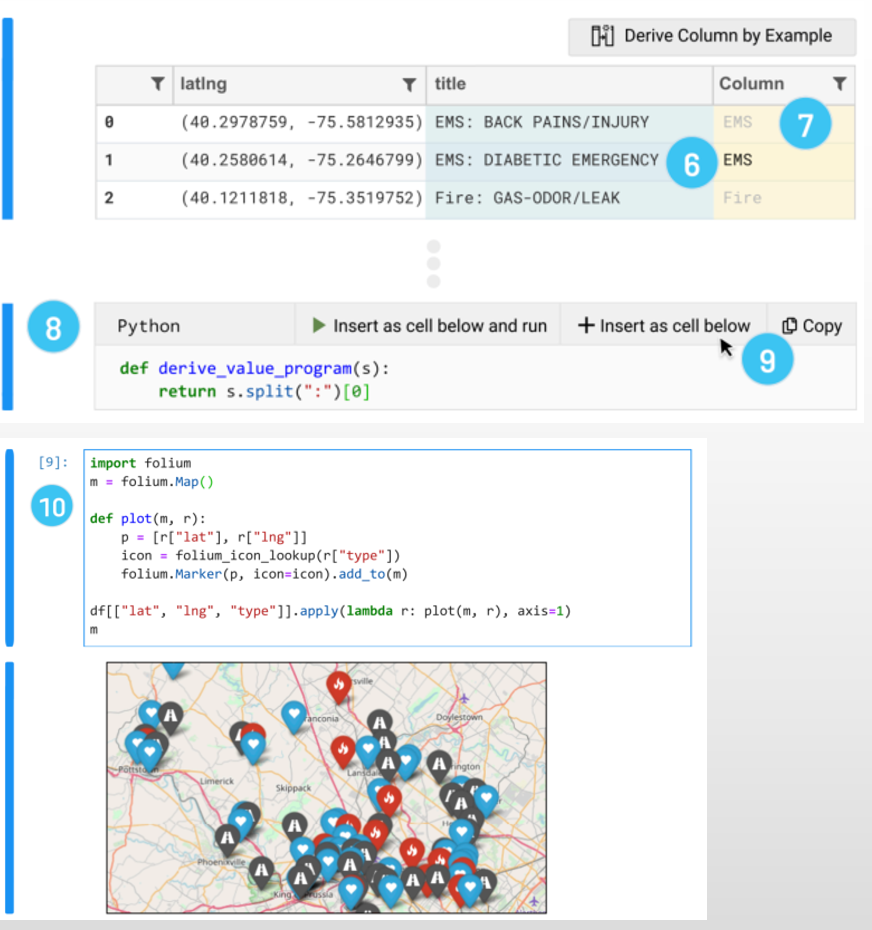
在6,7中,用户可以指定要转换成的结果当做example,然后8中生成代码,并可以任意插入到cell中
采访和设计目标
- 7 位数据科学家,在微软频繁使用notebooks
- Design goal
- 过渡过多,数据来回切换->
数据清洗工具应该集成在数据科学家的工作中(notebooks) - 黑盒不透明,缺少自定义,不满足格式,需要额外学习,希望使用更熟悉的语言->
数据清洗工具应该可以生成数据科学家熟悉的代码,来进行监测和修订。
- 过渡过多,数据来回切换->
实施
- 前端:Qgrid+修改
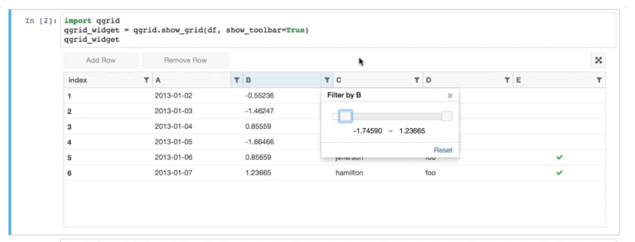
- 后端:pandas
可读性代码合成算法
FlashFill toolkit (开源工具,最多的转换函数有30多行)
domain specifc languages:提供字符串转换,数值转换,日期转换,查阅转换,相互组合
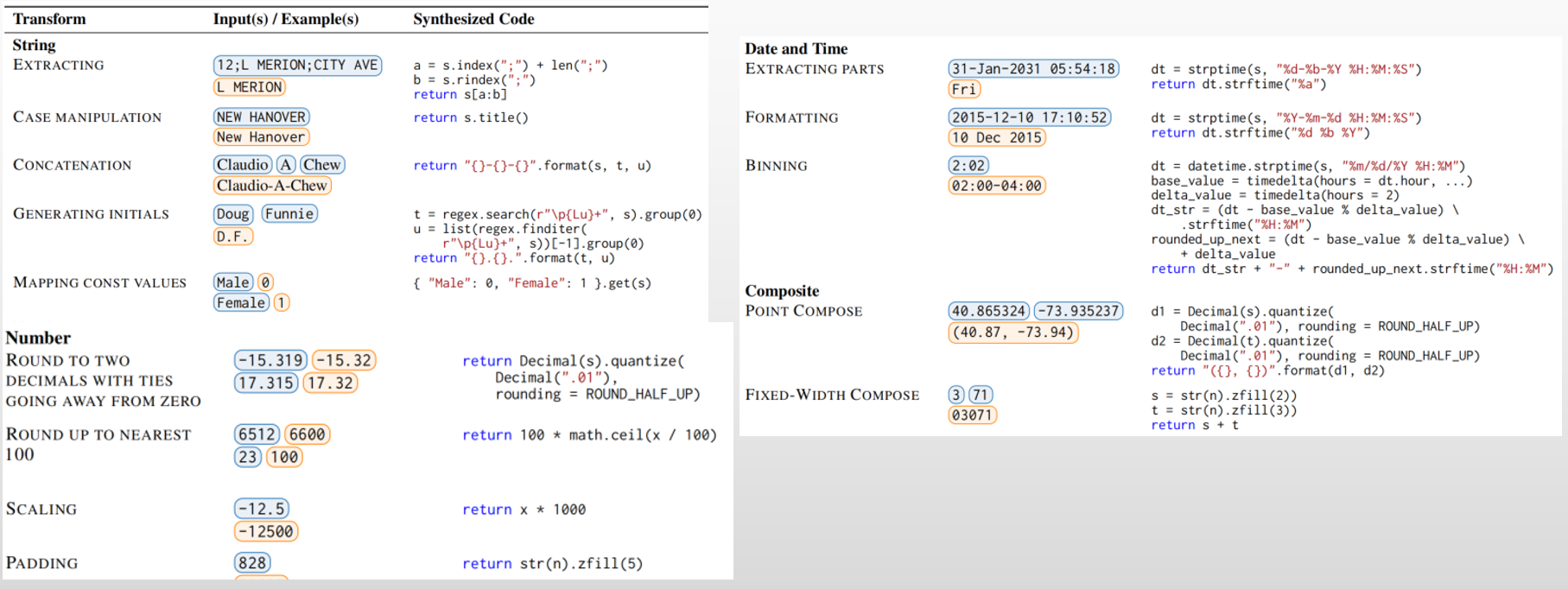
- Standard Program:使用FlashFIll ranker来生成多可能的Program(代码片段)
- Readable Program:使用readability_ranker来挑选可读性强的Program
- Rewriting: 使用自定义规则来生成更容易理解的Program
- Translation to the Target Language:生成指定的语言,通过抽取语法树和DSL-Program,用映射及定制的format funtion,最后用autopep8来格式化代码

算法限制
- 错误处理
- 指定复杂的约束:Traffic-> TR, 尾随空格
- 合成引擎不能识别
- 有些任务不适合
- 自然语言:“S.F.” to “San Francisco”
- 求平均值等任务
- 采样问题
- 基于小样本数据做example,在全样本数据可能会有问题
- 实例提供
- 用户需要一直检查来确定是期望的清洗过程,有时更喜欢排名低的规则
- 有些用户就是喜欢在Excel,Tableau,等工具中切换。集成在单应用中不一定是必要的
评估-实验
- 用户:12名数据科学家
- 数据集A:紧急呼救数据,包括日期,时间,经纬度,地理位置等
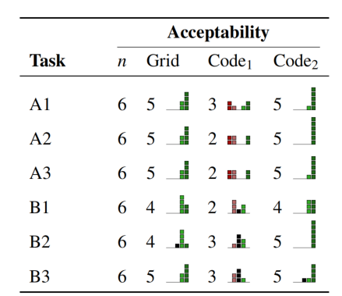
- A1:使用位置信息,提取城市名字,首字母大写 (Horsham)
- A2:使用日期和时间,格式化为12小时制,并增加@分隔符符 (Friday@1pm)
- A3:使用经纬度,格式化为数组并四舍五入 [39.15,42.15]
- 数据集B:纽约城市噪音投诉数据,包括各种时间,各种位置
- B1:创建日期列,并提取为2小时的时间区间(00:00-02:00)
- B2:使用地点类型和城市,组合成新的格式的title (Store/Commercial in New York, Manhattan).
- B3:使用经纬度,格式化为数组并五舍 [39.15,42.15]
过程
- A和B被均分,任务打乱,参与者在Jupyter notebook手写代码(也可以查阅网站)
- 完成后做5-point Likert scale评估这些任务的使用频率,并讨论难点
- 之后介绍Wrex,然后做另一个数据集
- 完成后做5-point Likert scale打分以及代码可接受度、是否可能被用于生产环境
- 讨论反馈
后续
- 根据建议直接修订合成的代码
- 去掉类,使用轻量级函数
- 变量命名_0,_1替换为 s t 等简单的助记名
- 删除了异常处理逻辑
- 更改后让参与者重新评估
量化结果
- 手写代码完成任务(12/36)
- Wrex完成任务(36/36)
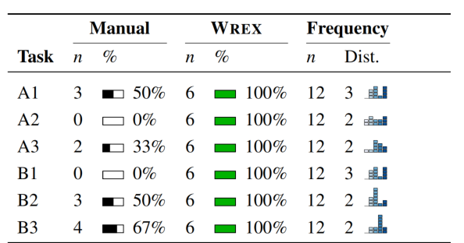
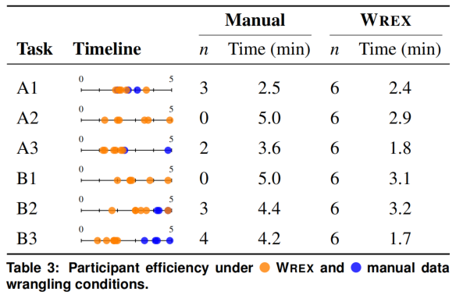
反馈
减少了数据清洗的障碍
- 回顾函数和语法
- 问题:现在用太多的语法和函数,很难记得其中的细微差别,尽管有内嵌的文档,和自动补全等功能,但是还是不能直接帮助专家理解,需要哪些操作,以及如何使用它们。
- 解决:programming-by-example,让专家更专注于要对数据的操作来生成代码
- 解决方案的搜索
- 问题:通常需要的解决方案只是众多网页上代码片段中的一小块,而有的时候这个问题的领域很小,没有人遇见,那么很难找到正确的解决方案
- 解决:Wrex可以基于对数据的预期的输出来寻找到正确的解决方案。这可以让专家专注到自己的分析过程中,而不是网站上搜索或者代码存储库。
- 回顾函数和语法
适配数据科学家的工作流
- 熟悉的交互,减少了学习成本
- 专家对其交互反馈很积极,只有些轻微的增强建议,右击上下文菜单和水平滚动
- 赞成在工作流中集成此工具,可以在notebook中使用,而别的工具中,需要在结果之后重写代码,并需要往返迭代,而wrex很容易嵌入
- 数据科学家对合成代码的期望
- 可读性:可以分享,可以修改,而且和自己期望的差不多就行,短变量名就可以接受
- 可信性:最显著的方法就是读代码,有的人希望可以有边界情况,简单的输出总结,代码注释和数据可视化。最重要的不是机制和框架,而是输出,如果wrex的代码可读性差,他们将不信任它
讨论
- 数据科学家需要场内(In-situ)工具在他们的工作流中
- 数据清洗是数据分析的一部分,也会强化用户的分析任务
- 不用离开工作流(notebook)去寻找解决方法
- 不用导出数据到其它的工具,并重新导回数据
- 减少挫败感,因为要来回搜索方法,复制粘贴
- 生成的小代码片段和notebook cell很相似
- 用户与代码的交互,通过不断的增加example来修正歧义
- 可读性的合成代码对于数据科学家的优先级
- 不应该是看起来像人类写的,而是专注于具有数据科学家需要的高优先级特性
- 代码与数据间替换交互
- Excel查看数据是flexibility,Python IDES是usability, Wrex合并了两者。
- 可以生成多种转换和交互方案,来进行比较和选择
- 合成的代码使数据科学更容易访问
- 不同编程水平的人都可以进行数据科学,他们直接可以用清洗后的数据去完成分析
- 不用时刻跟上API的更新,可以利用wrex来使用和学习这些代码。未来适合教学
Questions & Discussion:
✉️ dongminghan@zju.edu.cn