论文:DataShot: Automatic Generation of Fact Sheet from Tabular data
作者:Yun Wang, Zhida Sun, Haidong Zhang, Weiwei Cui, Ke Xu, Xiaojuan Ma, and Dongmei Zhang
发表:VIS 2019
fact sheet 的设计者不仅要深刻理解地数据,还要制作出引人注目的图形表达,这一工作通常是耗时繁琐的,本文提出了一种从表格数据中自动生成 fact sheet 的方法,从而简化用户的操作。
介绍
Fact sheet 是什么:
- Fact sheet is a presentation of data in a format which emphasizes key points concisely, usually using tables, bullet points and/or headings, on a single printed page.
- Fact sheets often contain product information, technical data, lists, statistics, answers to common questions (e.g. FAQs), educational material, or how-to, “do it yourself” advice. They are sometimes a summary of a longer document.
Example:

优点:
- 使得观众高效地理解数据相关的事实
- 留下深刻的印象
生成 Fact Sheet 的挑战:
第一个挑战是从数据表中提取数据事实,并将事实组织到有意义的主题中。
第二个挑战是,选择合适的可视化方法来展示数据事实。
文章贡献:
- 调查研究了一个优质的 infographic 数据库,用来分析 fact sheet 的实际设计。
- 使用新颖的技术来描述 DataShot 框架,以将数据事实组织为主题,并将数据事实转换为 fact sheet。为了验证这一技术,实现了一个概念验证系统来从表格数据自动地产生 fact sheet。
- 使用真实的数据来演示系统的使用,并在实验室进行用户研究,以揭示 DataShot 的潜在的好处
Fact Sheet 设计的调研
数据来源: Kantar Information is Beautiful Awards 选择 2012-2018 年,298 个信息图表类型的作品。去除了 53 个包含 特殊设计的艺术图像或符号 的例子,保留了 245 个由常见的单一视觉效果或复合视觉效果组成的 fact sheet
定性分析阶段 :整体设计(Sheet-Level Design)、视觉元素级设计(Element-Level Design)
整体设计
内容结构:random,sequence, multiple plots
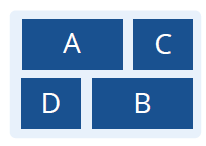
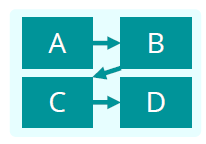
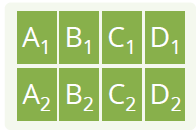
页面布局:编码了八种布局方式:

在 245 个例子中的分布情况:

发现最多使用的是:随机事实这种内容结构方式,平铺的页面布局。因此决定,从这两个配置开始,开发 Fact-Sheet 的自动生成方法。
视觉元素级设计
可视化风格:从 245 个 fact sheet 中提取出 793 个视觉元素,分布情况如下图所示
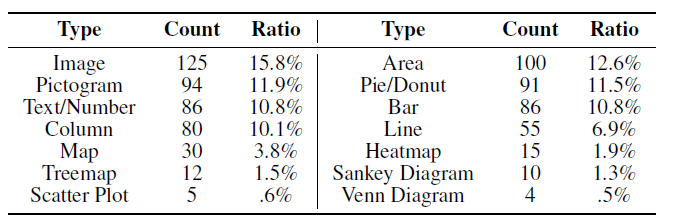
常用的事实类型:总结出 11 类事实类型
数值、比例、差异、分布、趋势、排名、聚合、相关性、极端案例、类别、异常情况
由统计的数据表明:设计者更愿意选用饼图来展示比例;更愿意用折线图来表示趋势……
DataShot
设计目标:
- G1 确保数据事实的准确和可靠
- G2 支持有效的数据事实提取。
- G3 将数据事实组织到对应的主题中
- G4 呈现的内容 简明、让人印象深刻
- G5 支持简单的用户交互
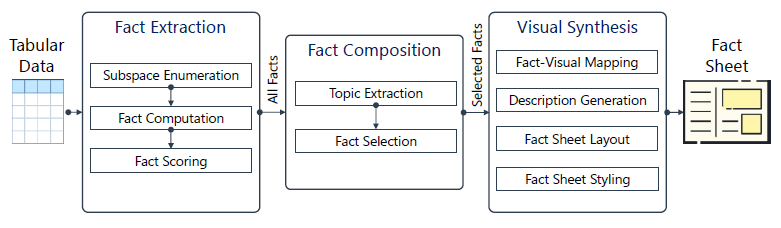
系统 Pipeline:
Fact Formulation:
将 fact 定义为如下形式:$fact = {type, parameters, measures,subject,score}$
Fact Extraction:
子空间枚举(Subspace Enumeration):
$subspace = \left\{\left\{f[1]:v[1]\right\}, \ldots, \left\{f[n]:v[n]\right\}\right\}$ 使用 BUC 算法,按 top-down 顺序枚举数据子空间。限制数据立方的格点深度为 3,因为经过超过 3 维过滤的数据子空间对用户来说通常是无趣的。
事实计算(Fact Computation)
在枚举数据子空间的过程中,DataShot 进行计算以搜索不同类型的事实。目前,DataShot 在一次计算中只支持一个度量.
计算事实分数(Fact Scoring)
$score = W_s·score_{significance} + W_f·score_{focus} + W_c·score_{context}$ 参数分别为 0.6/0.2/0.2
Fact Composition:
主题提取(Topic Extraction):
$sheet_{topic} (t)=\{fact[1],fact[2],…,fact[d]\}$ $where fact[i].subject.context=t or fact[i].subject.focus=t$
事实选取(Fact Selection):
根据事实分数,选择 top-N 个数据事实,然而,在许多情况下,最重要的事实在语义上可能非常相似,因为它们共享在统计上非常重要的属性,支配着最终的得分。因此需要平衡事实的重要性和差异性。具体过程是:
- 计算事实之间的距离。
- 从上到下选择,选择最重要的事实,同时排除和它最接近的。如果几个事实的分数相同,那么选择最“离群的”
Visual Synthesis:
事实-视觉映射(Fact-Visual Mapping):
- 使用 793 个视觉元素以及他的事实类型,训练一棵决策树。
- 还考虑了 Inter-consistency 和 Intra-diversity。比如:事实类型相同,主题及度量也相同,应采用相同的视觉映射来保持一致性;相同的事实类型,主题或者度量不一样,就尽量采用不同的可视化方法。
事实描述的生成(Fact Description Generation)
- 采用基于模板的方法来为每种类型的数据事实生成相应的描述。 构建了包含主题、度量、维度和事实细节的文本模板。
Fact Sheet 布局:
- 由上面的调查结果,采取平铺、随机事实的布局方式
风格(Fact Sheet Styling):
- 支持三种风格,七种配色方案
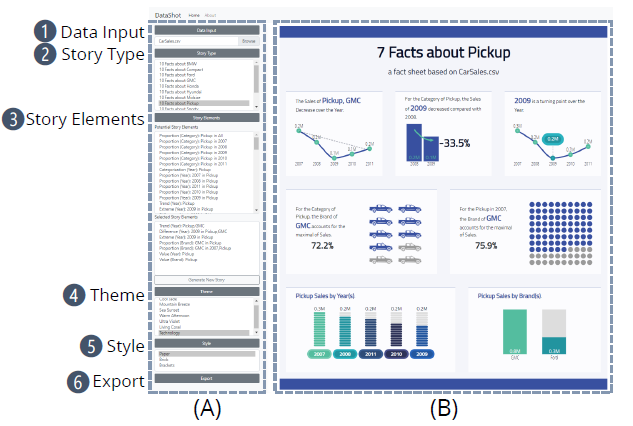
UI 界面:
评估以及讨论
Use Cases: 搜集一些网络数据制作了如下结果:

User Study
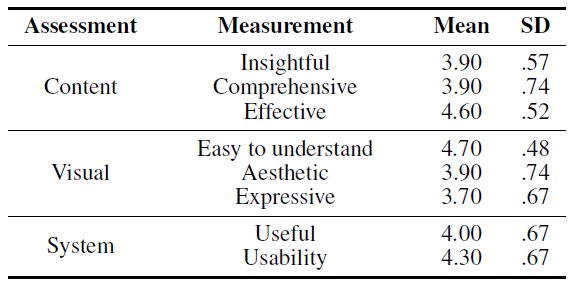
由于 DataShot 是提出的第一个直接从表格数据生成事实表的系统,因此没有理想的工具或技术可供比较。因此,设计了一个用户研究,要求参与者首先使用问卷对 DataShot 进行评价,然后通过研究后的访谈,根据他们使用 DataShot 的经验收集他们的反馈。
Limitation:
把每个数据列独立看待,没有考虑它们之间的相关性。比如:国家 地区
图表和视觉效果主要来自于预定义的库,受库大小的限制;只支持平铺式的 layout。
视觉元素只来自于调查中的 fact sheet 样例。不够丰富
Inter-consistency 有待加强,以提高 fact sheet 的质量
按照分数和相异性来选择事实会引起偏差,不完美。需要开发一个更好地事实评估方法
✉️ 1220341948@qq.com