动机
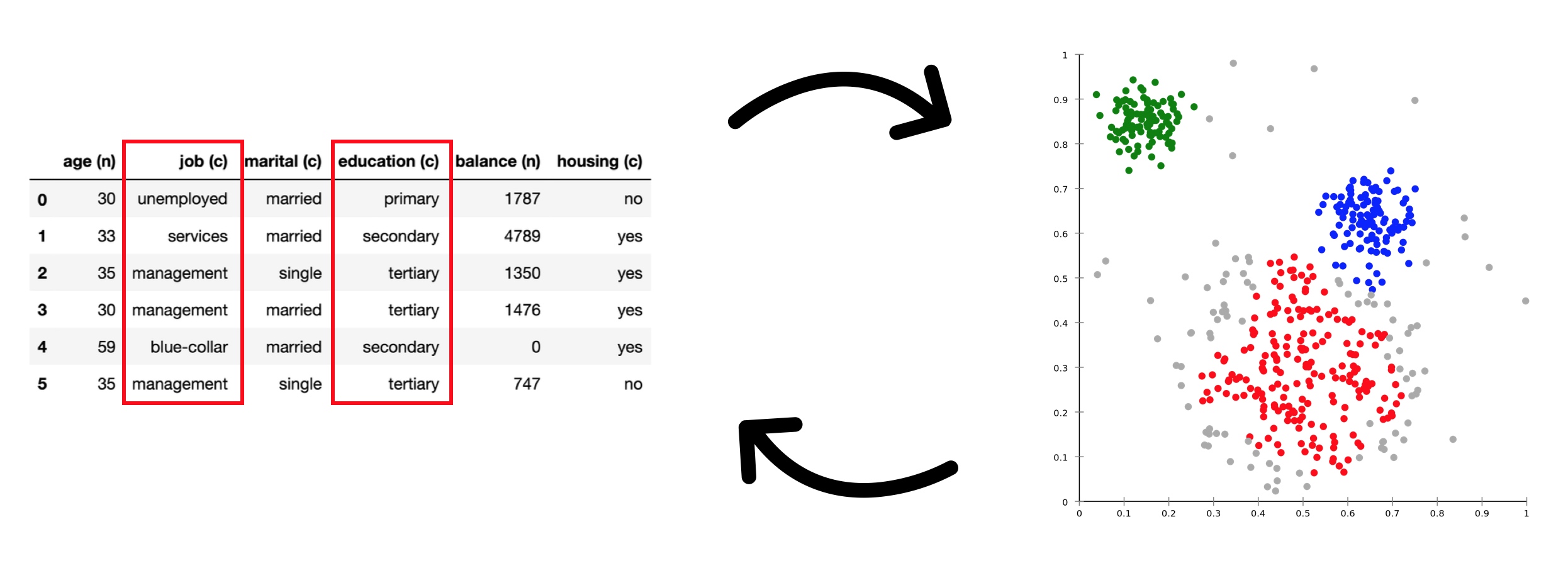
- 可视化中对于经常遇到的高维数据往往需要对其降维和聚类,来进行理解。然而实际上,对于复杂或是专业领域的数据,我们并不知道为什么会得到这样的聚类结果。聚类之间划分的依据是什么?他们各自有怎样的特点?由于降维浓缩了很多信息,因此答案只能在原始数据中去找。
- 可是这样一来就形成了一个闭环,问题出在降维之后得到结论,并不一定容易理解。对研究者而言,这样难以继续深入挖掘数据背后的含义;对读者而言,也比较晦涩,不够具备说服力。
- 如果有一种方法可以告诉我们,每一坨聚类对应的高维数据中最与众不同的几个维度的分布。例如这里的表格数据,它的每一列就是一个 feature,我们需要知道各个聚类对应的关键 feature。这样我们就可以得知聚类的特征,从而理解聚类的背后的含义
挑战
- 理解降维数据聚类的方法方面的研究不多。
- 现有的可以 review 原始数据的特征的方法不够 scaling,比较耗时。
贡献
- 本文设计了一个可以有效高亮出降维结果的聚类中重要 feature 的可视分析流程
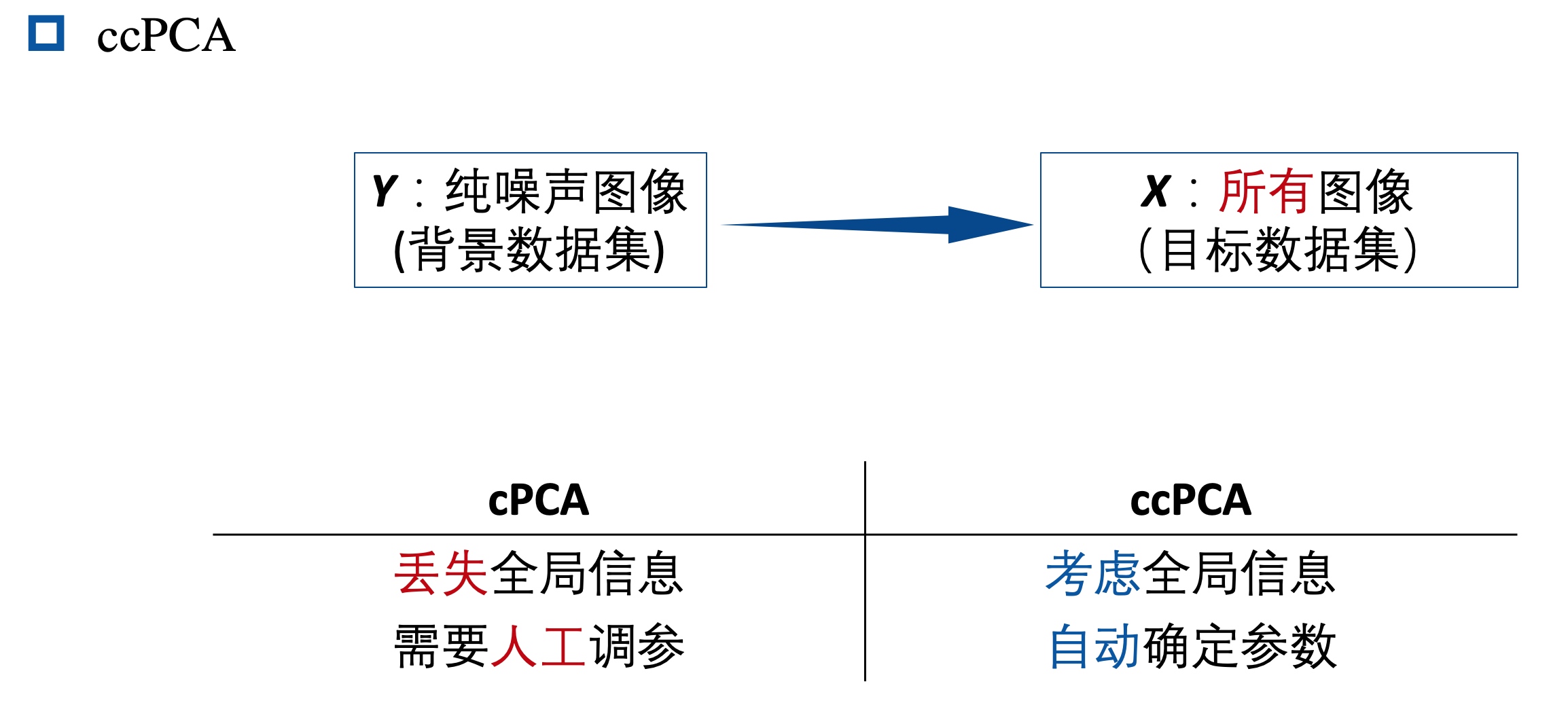
- 介绍了对比-主成分分析(cPCA)的增强使用方式
- 基于 cPCA 提出了对比聚类-主成分分析(ccPCA),用于计算每个 feature 在聚类之间的相对贡献
- 实现了一个支持理解降维数据聚类之后的结果在 feature 中的相对贡献的交互式系统
相关工作
探索降维结果的可视化方法
(InfoVis2015) Probing Projections: Interaction Techniques for Interpreting Arrangements and Errors of Dimensionality Reductions
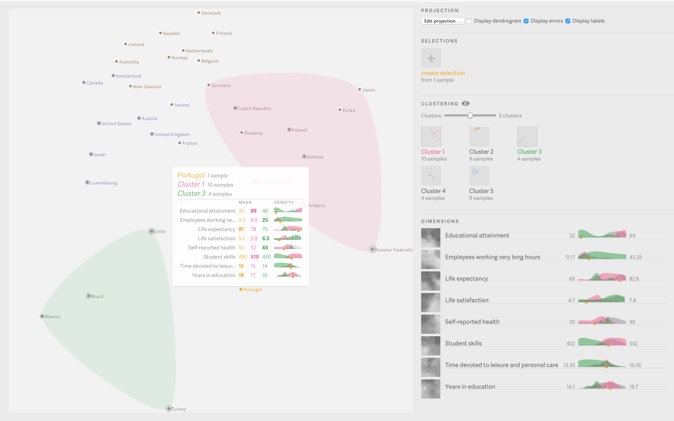
Workflow
- User selects the cluster in MDS
- Depict the correspond density plots
- Finish the feature comparison
Limitation
- not scalable for large number of features
判别分析
(2017) Linear Discriminative Star Coordinates for Exploring Class and Cluster Separation of High Dimensional Data
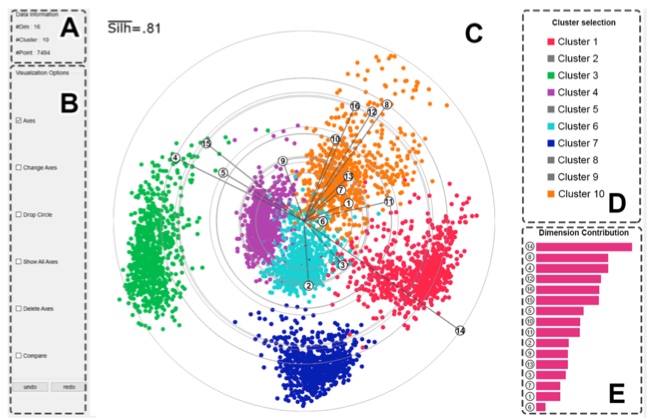
这篇文章用了 Star coordinates 来表示原始数据在二维空间的一个线性嵌入。右下角的 E 视图按照贡献大小对 star coordinates 的各个维度进行排序。
Limitation:仅适用于相互独立的 feature。assumes the features are independent to each other
对比学习
- 对比-主成分分析(cPCA),
- 本文第一个使用对比学习方法来进行可视分析研究。
分析流程
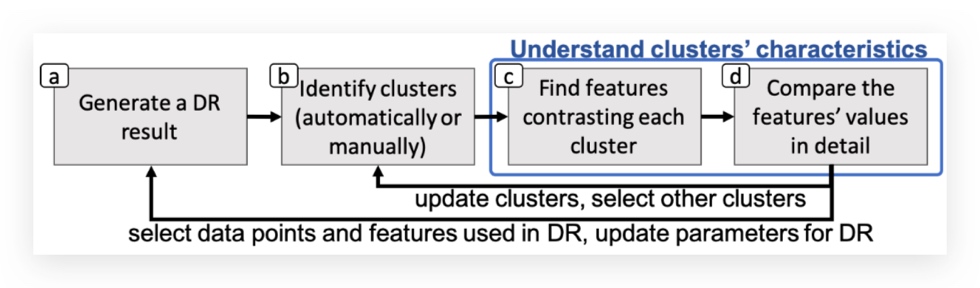
这张图简洁的表示了文章的 analysis workflow。
(a)首先对高维数据应用降维方法,这里支持 MDS,PCA 和 t-SNE。
(b)然后再进行聚类,例如 k-means,DB-SCAN,谱聚类和手动聚类。
(c)接下来是对先通过 cPCA 理解聚类结果的特征。
(d)再分别将每个聚类作为 target 来 review 相对剩余的其他数据点之间贡献较高的 feature 值的详细差异。
通过(c)(d)两步,我们可以理解原始数据中的哪个 feature 是如何对每个聚类产生贡献的,在理解了所选聚类的特征之后,用户可以选择一部分感兴趣的数据点来更新降维结果和聚类,或者改变算法参数。再重复以上步骤。
方法
cPCA
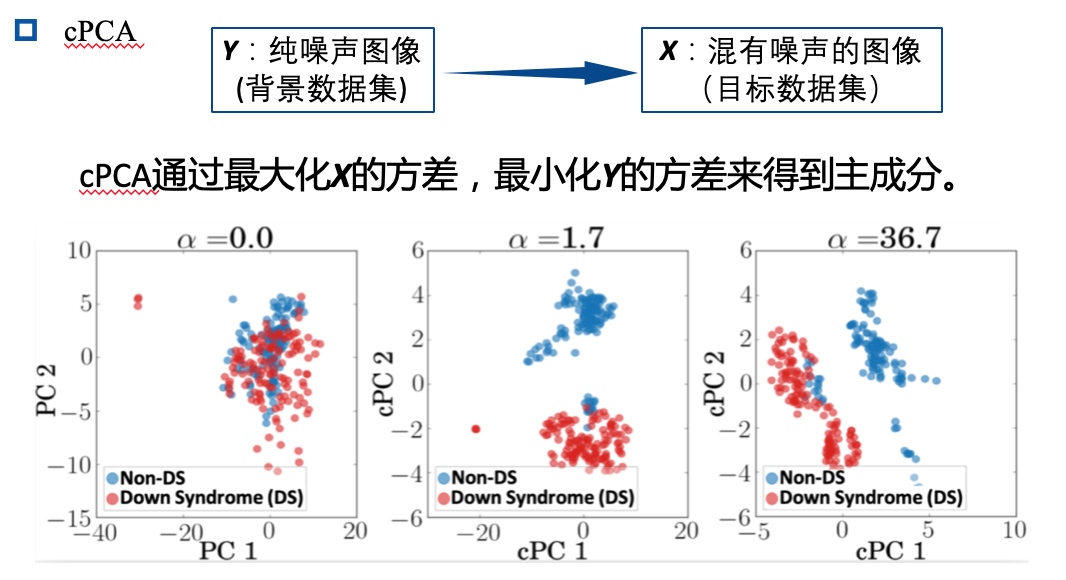
当我们拥有多个相关联的数据集或者数据集可按照某种特征来分割,我们就可以使用对比学习。
例如,我们可以将 patient 数据集按照是否患有某种疾病分为 X 和 Y。当用户想要挖掘 X 的 pattern,但是 Y 又包含了用户想要从 X 中去掉的结构信息。传统的 PCA 只能看出所有聚类之间的差异,但是无法单独考虑某个聚类和其他所有聚类之间的差异。所以就提出了 cPCA 这种对比 PCA 方法。
ccPCA
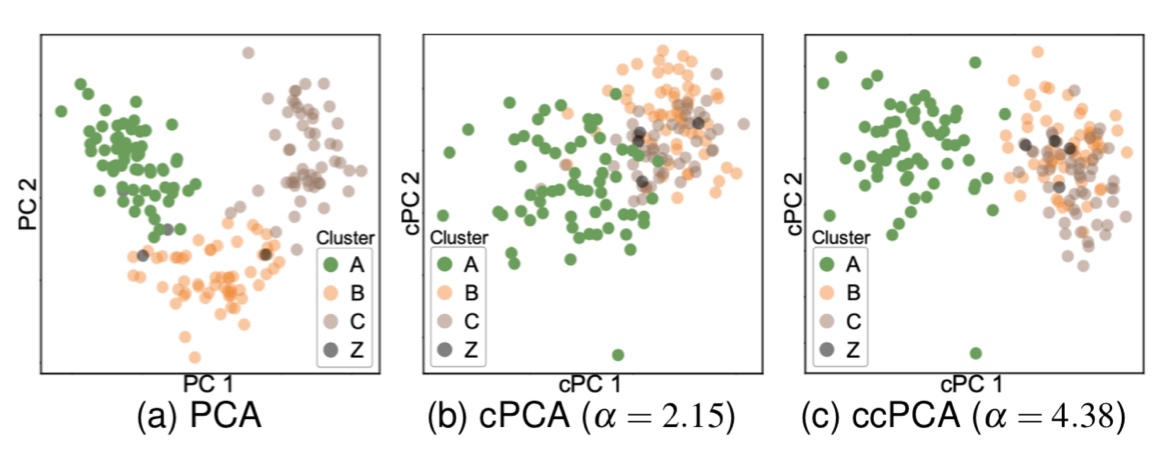
这里比较的是葡萄酒识别数据集的降维结果。四种颜色分别表示 4 类特征的白酒,这里关注绿色的类。
(a)使用 PCA。当 PC1 和 PC2 结合起来时,绿色分类和其他的较好的分开,但是只用 PC1 时,绿色和橘色则有重叠。
(b)使用 cPCA。绿色作为 target,其他的作为 background,并且通过半自动方法确定最优的 alpha,从两个主成分单独和结合来看,绿色都与其他类有较大的重叠。
(c)使用 ccPCA。整个数据集作为 target,除绿色之外的作为 background,通过自动方法确定 alpha。可以看出只用 PC1 的分类结果好于之前两个。
相对贡献
系统界面
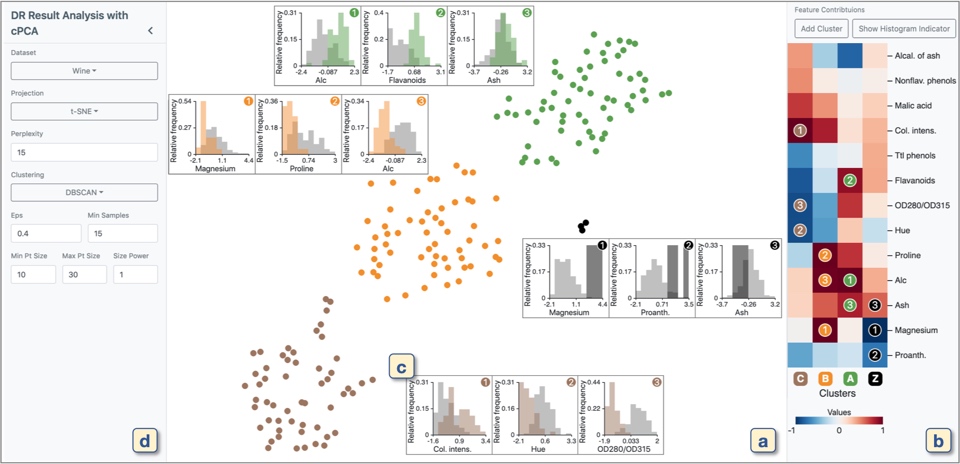
系统的 demo 分析了葡萄酒识别数据集。这个数据集包含了 178 种葡萄酒以及 13 中 feature,包括酒精度、色彩强烈度、黄酮含量等。
首先是(d)中的 panel,先使用 t-sne 降维。然后使用 DB-SCAN 对降维结果聚类。
接着是(a)中展示的是三种聚类,用不同颜色表示。黑色表示的是 DB_SCAN 识别出的异常点或者是噪声数据。
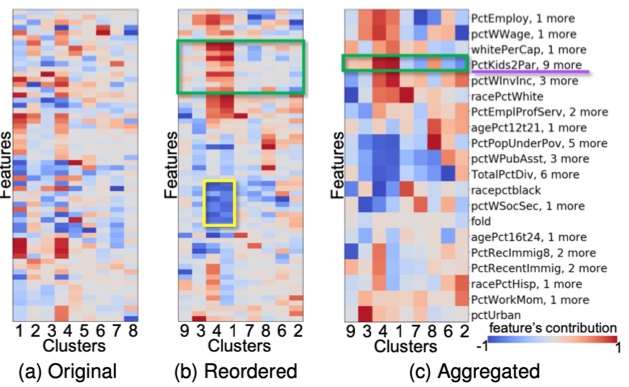
对每个聚类应用提出的 ccPCA 方法,从而得到了每个 feature 对聚类作出的贡献。贡献视图如(b)部分所示。
最后(c)部分表示的是各个聚类 3 个贡献绝对值最大的 feature 的直方图,可以直观的看出每个聚类的特征。这里的直方图将 target cluster 用相应的颜色表示,其余类用灰色。Y 轴表示频率的相对大小。
案例分析
- Tennis Major Tournament Match Statistics dataset
- 174 data points (tennis players)
- 13 features (statistics)
- Nutrient dataset
- 7,637 data points (foods)
- 14 features (nutrients)
- Communities and Crime dataset
- 2,215 data points (communities)
- 143 features (statistics)
案例一
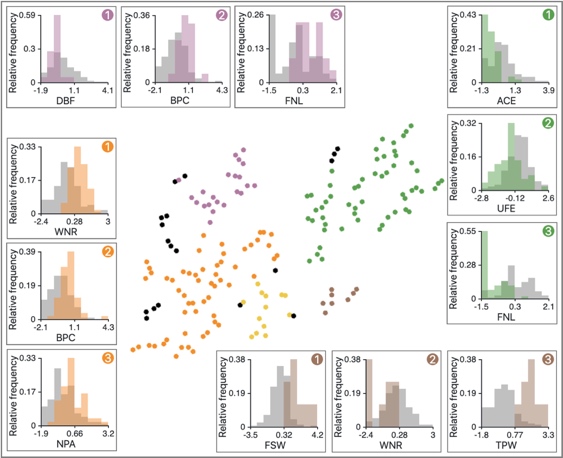
这个数据集是 2013 年四大满贯的男子和女子的比赛统计。可以看出每个聚类都有不同的打球技术风格。
the purple cluster tends to have low ‘DBF’ (双误数), high ‘BPC’ (破发数), and high ‘FNL’ (首场获胜数). 运动员发球失误率低,接发率高,从而胜率高。
the orange cluster has high ‘WNR’ (胜场数) and ‘NPA’ (净胜分). 运动员擅长拿下多拍回合。
the brown cluster has low ‘WNR’ (胜场数) but high ‘FSW’ (一发得分数) and ‘TPW’ (总得分). 擅长通过发球得分。
总结
优势: 1.支持大型数据集 2.适用于非线性方法
不足; 1.时空复杂度高,无法实现实时处理 2.需要数据本身有较好的聚类结果
✉️ panrusheng@zju.edu.cn