报告
第一类是联邦学习开创者讲述联邦学习problem setting,以及几个常用的算法的文章,这类工作目前显然不能再做了,但需要阅读。
Federated Optimization: Distributed Optimization Beyond the Datacenter
这篇文章是联邦学习的雏形,在2015年就被提交至arxiv上,所使用的算法与现版本有所区别,与之前的两个学习算法有相当大关联,SVRG与DANE.
SVRG全称为stochastic variance reduction gradient,主要的工作是对随机梯度下降做了一些修正,使得每一步的梯度估计方差更小,加快收敛速度,相关的工作可以追溯到2012的两篇文章。
DANE全称为Distributed Approximate NEwton,这是个分布式学习算法,主要工作是提出了一个近似类牛顿优化方法,并证明其在二次目标函数上拥有更快的收敛速度。
这篇文章所提出的联邦学习算法,实际可以看作用SVRG产生DANE所需解的估计,然后按照DANE的方式进行更新。
更进一步,在DANE这篇论文总结相关工作的部分,可以看到现在所广泛采用的联邦平均算法,其实更接近与2010年由zinkevich提出的one-shot averaging算法。
所以我认为联邦学习的核心应该是它所提出的问题,即数据不均匀地分布在大量结点上,如何在隐私性的前提下训练一个高质量的全局模型。
Communication-Efficient Learning of Deep Networks from Decentralized Data
这篇文章的一作McMahan是上一篇文章的第二作者,比较擅长差分隐私和分布式算法,也是联邦学习的主要贡献者。
这篇文章的主要工作是进一步阐述联邦学习的问题,介绍了一些实际的应用场景,技术困难等等,并提出了现今被普遍使用的联邦平均算法,在多个数据集、多种模型上进行了实验。
这里可以对比一下上面所说的one-shot-averaging算法与federated averaging算法:

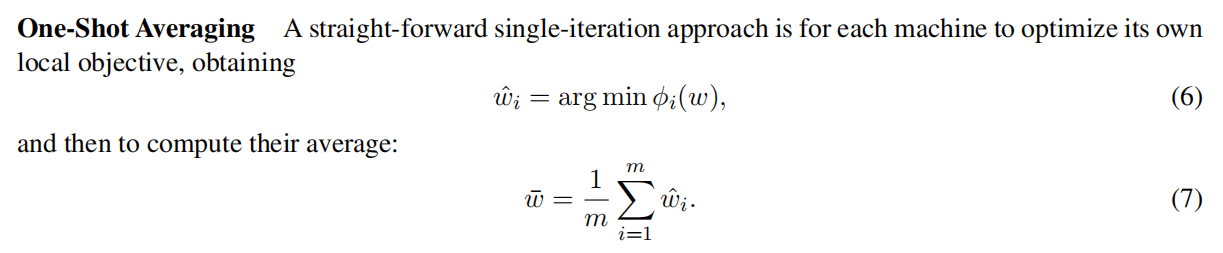
可以看到两者很相似,甚至可以认为联邦平均只是使用了one-shot averaging来解决联邦学习的问题。
如果将联邦学习看作机器学习的新分支的话,符合其问题设定的研究都可以视作联邦学习领域的工作。下面会列举一些联邦学习与其它机器学习分支交叉的工作,这类工作我认为是目前比较好做的工作,不需要很多关于优化的专家知识。
Secure Federated Transfer Learning
这篇文章的第二作者是杨强,一作是两位微众银行人工智能部的职员。主要工作是解决迁移学习中的隐私问题,可以发现这篇文章并没有使用联邦平均算法。
关于迁移学习
迁移学习是机器学习的分支,研究的问题如何进行模型、数据之间的知识迁移。以两个数据集为例,它们各自不同但有相似之处,如车辆分类数据集与轿车分类数据集。一个被定义为源域,另一个被定义为目标域,主要目的是从源域迁移知识至目标域,以提升模型在目标域的性能。
本工作的问题设定
在这篇文章中,源域和目标域数据被不同客户端持有,由于迁移学习需要很多源域与目标域间的信息传递,进行隐私保护和一般的应用有很大区别。
同时也可以看到这里的问题设定也与谷歌对联邦学习的设定不同,只包含两个参与者间的模型构建,可以认为是由迁移学习的应用场景决定的。
核心的加密算法是加法同态加密,并使用随机生成的掩码对中间信息进行保护。
大体思路是先给出较一般的迁移学习算法,然后从隐私保护的角度对训练的具体流程进行修改。
Federated Reinforcement Learning
这篇文章的第二作者也是杨强,第一作者是中山大学的副教授,由微众和中山大学合作完成。
问题设定
相比上一篇文章,这里的问题设定更接近联邦学习的最初设定,在多智能体强化学习中,存在多个观察全局状态的自动智能体,它们选择一个个体动作并获得一个团队奖励。
这里从隐私性的角度出发,假定智能体之间不能分享观察到的状态,甚至有一部分无法接受到奖励来构建决策方式。
目的是在这样的设定下,结合各个智能体来构建有效的决策模型。

大体的思路与上一篇文章相似。
Federated Multi-Task Learning
本文章的第一作者是stanford的virginia smith,在分布式学习领域做了很多重要的工作,近年对联邦学习领域也有很多贡献。
与联邦学习一般的设定不同,联邦多任务学习的目的是为每个用户同时学习不同但有联系的模型,这样的需求常见于许多应用场景中,如一些需要高模型性能同时也需要个性化的应用。
本文章的主要的工作就是为通用多任务学习框架设计了分布式、隐私保护、高通信效率的训练算法,同时对算法的收敛性进行了理论分析,理论相当充分。
类似的工作还有一些,这里不再列出。另一个方向是从一般联邦学习框架的安全性、隐私性着手的,包括不限于以下的工作:
Practical Secure Aggregation for Federated Learning on User-Held Data
这篇文章为联邦学习提出了使用户上传参数对服务器保密的协议,mcmahan是作者之一
Deep Learning with Differential Privacy
这篇也是mcmahan的工作,将差分隐私的方法引入了联邦学习中,使得服务器难以从模型参数恢复数据,提高联邦学习的隐私性。
Differentially Private Federated Learning: A Client Level Perspective
指出现有的框架容易被差分攻击,从而泄露训练过程中各用户的贡献,针对这个问题本文章提出了能够保证客户端级别差分隐私的算法,并且不会造成最终模型较大性能损失。
How to Backdoor Federated Learning
指出联邦学习对参数更新过程进行隐私保护的做法,相比只针对训练集的模型攻击,model-poisoning攻击在使用联邦学习训练的模型上非常容易成功。
按照文章的方法,只需要一个用户进行攻击,就可以达到如使分类模型将含有特定特征图片判定为攻击者指定的类别的效果。
并且表明了使用了secure aggregation的联邦学习模型,无法以检测用户训练过程中贡献的方式来防御该攻击。
另一类就是联邦学习实际应用的工作,不在我们的讨论范围内。
✉️ zjuvis@cad.zju.edu.cn