P4: Portable Parallel Processing Pipelines for Interactive Information Visualization
作者:Jianping Kelvin Li and Kwan-Liu Ma
发表:TVCG 2018 Sep. 19
简介
本文介绍了一个基于 GPU 加速的信息可视化框架:P4 (Portable Parallel Processing Pipelines)。它利用 GPU 辅助进行信息可视化过程中的数据计算与图形渲染,能够对大规模数据进行可视化。
该框架实现了四个可视化开发中的目标:
- Performance: 运用 GPU 处理数据和渲染视图
- Productivity: 声明式语法
- Programmability: 运行时处理用户定义逻辑
- Portability: 基于浏览器平台(WebGL)
相关工作
图形与可视化技术
1. 声明式可视化语法
常见的可视化框架采用声明式的语法定义可视化编码与交互,能够很直观地呈现可视化效果,提升开发人员的效率。常见的可视化框架,如 D3、Protovis 可以声明式定义可视化属性,Vega、Vega Lite 等框架可声明式定义可视化交互。
2. GPU 技术
目前 GPU 主要应用于两个方面:图形绘制和通用计算。
在图形绘制方面,有基于渲染管线的绘制框架:OpenGL、WebGL,以及不同平台下的渲染框架,如 Metal、DirectX 等等。在通用计算(GPGPU)方面,一些框架可以利用 GPU 计算浮点数的高效性以及并行上的优势完成高速计算,如 OpenCL,CUDA 等。
高性能可视化技术
1. 大规模数据处理
对于大规模数据可以采取减小实际处理的数据量的方式进行优化,如对数据进行 filtering、sampling,做 data cubes 等。除此之外,也可以运用分布式的技术来处理,这种方法常见于企业级的可视化工具种,如 Spotfire、Tableau 等。
2. 实时交互性增强
为了提升用户交互的实时性,额可以采用多线程并行处理的技术,分管不同的工作,保证系统不会阻塞。同时也可以使用增量可视化的形式,逐步呈现可视化结果。
系统结构
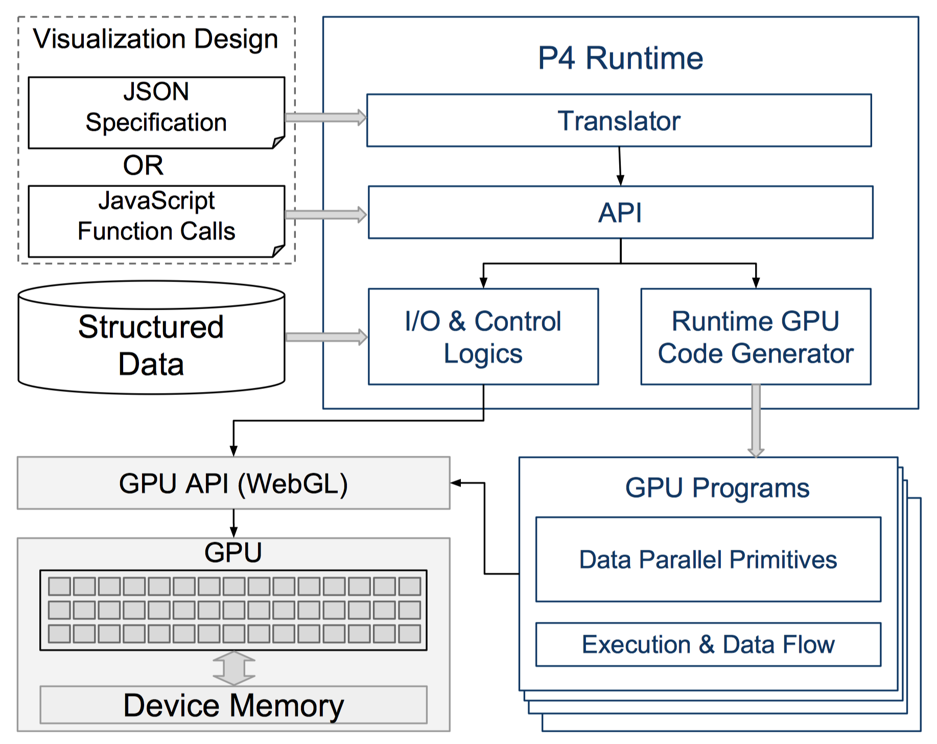
如图所示,整个系统包含四个部分:
- 程序接口部分:图中左上角。接受用户的输入,支持 JavaScript 调用或者 JSON 格式的设定,同时接收用户传入的结构化数据;
- 核心处理部分:图中右上角。处理用户输入或设定的数据处理逻辑与可视化编码,调用相应的函数或调用 GPU 程序生成模块生成 Shader 程序;
- GPU 程序模块:根据用户定义的逻辑,在运行时控制生成对应的 shader 程序;
- GPU 计算部分:调用 WebGL 相应 API 完成数据和程序到 GPU 的传入,控制 GPU 进行计算于渲染。
编程接口
P4 的编程接口遵循 InfoVis Reference Model:
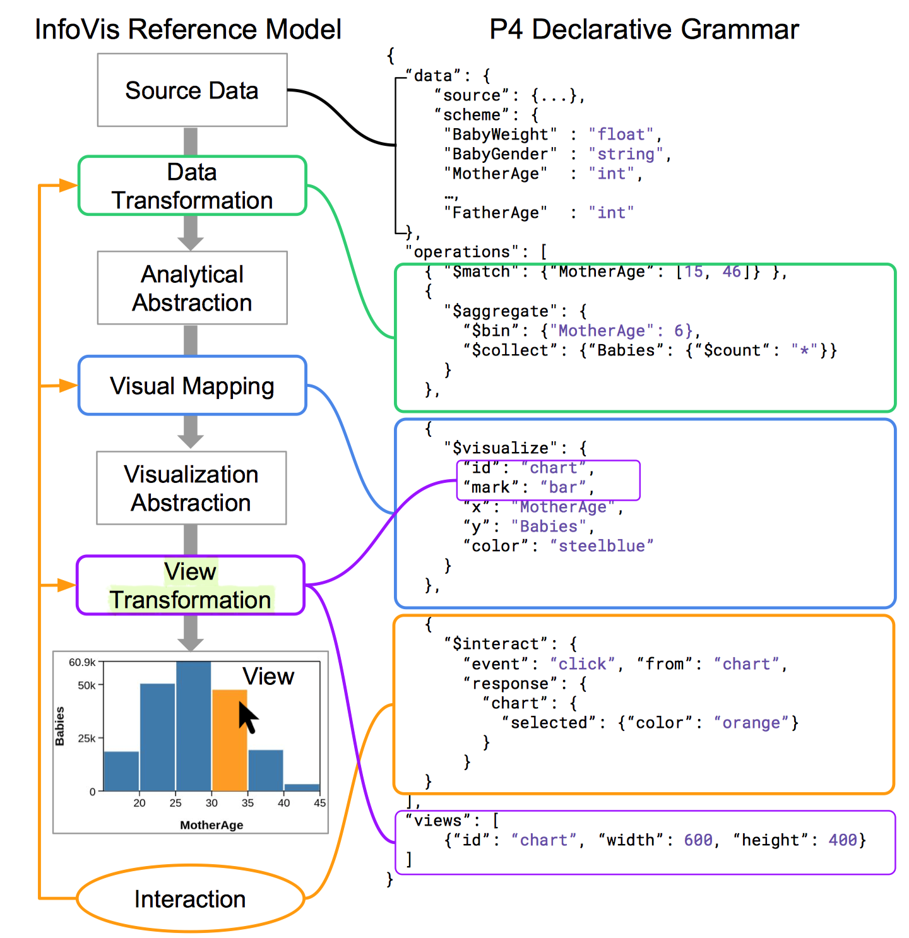
大致有五部分组成:
- 原始数据:设定数据的来源以及数据的格式
- 数据变换:通过原始数据得到可视化图表需要的目标数据,支持 Derive,Match,Aggregate 三种操作
- 可视化映射:设定对应的可视化编码以及编码的属性可视呈现数据
- 视图变换:对视图整体属性进行设定
- 用户交互:设定用户交互事件以及响应行为
控制流
P4 整体是一个流水线机制,在每一步中,上一步的输出作为下一步的输入,在整个过程中不存储中间计算结果,因此,如果想在单一路径的流水线中加入新的分支,需要支持一定的手动控制操作。
目前 P4 支持三种手动控制操作:
- Register:保存计算中间状态
- Resume:恢复保存的状态
- Export:将计算完成的结果导出为 JSON 或 JavaScript Object
视觉设计优化
当可视化大规模数据时,会有大量的点分布重叠,因此需要采取一定的方式呈现重叠的程度。本文采取了根据重叠度不同设定不同透明度的方式进行优化,公式如下:
其中:
- $\alpha_{min}$: 设定的最小透明度,默认为 0.1
- $\rho_{max}$: 视图中最大的重叠元素个数
- $\rho$: 当前位置的重叠元素个数
运用上述优化后的效果如下图中间视图所示(左侧为 WebGL 默认颜色混合函数,右侧为聚合后使用不同颜色编码后结果):

并行体系
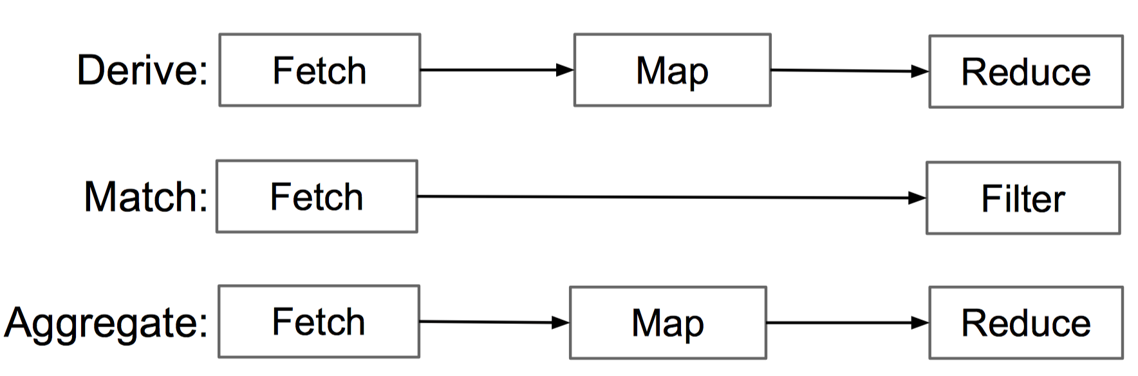
P4 首先设计了 4 中可并行的 GPU 加速元操作:fetch,filter,map,reduce
数据转换操作可以由上述的四种操作组合而得到:
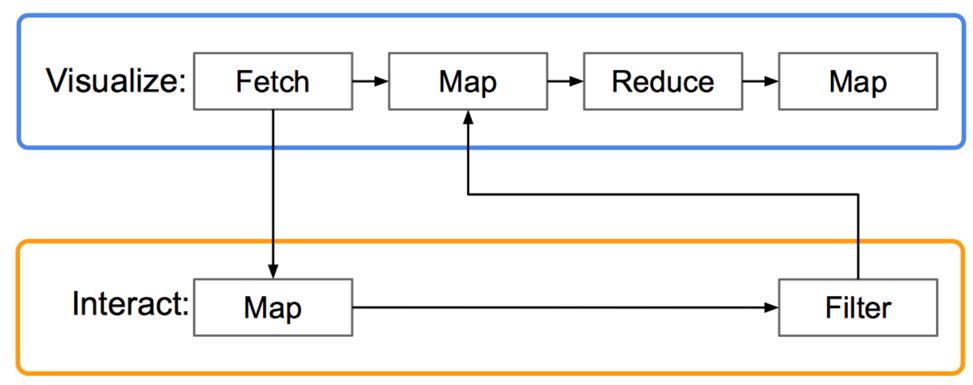
同样,可视化与交互也可由并行元操作进行实现:
性能评估
本文就 P4 的几方面功能分别展开了评估:
1. 数据处理
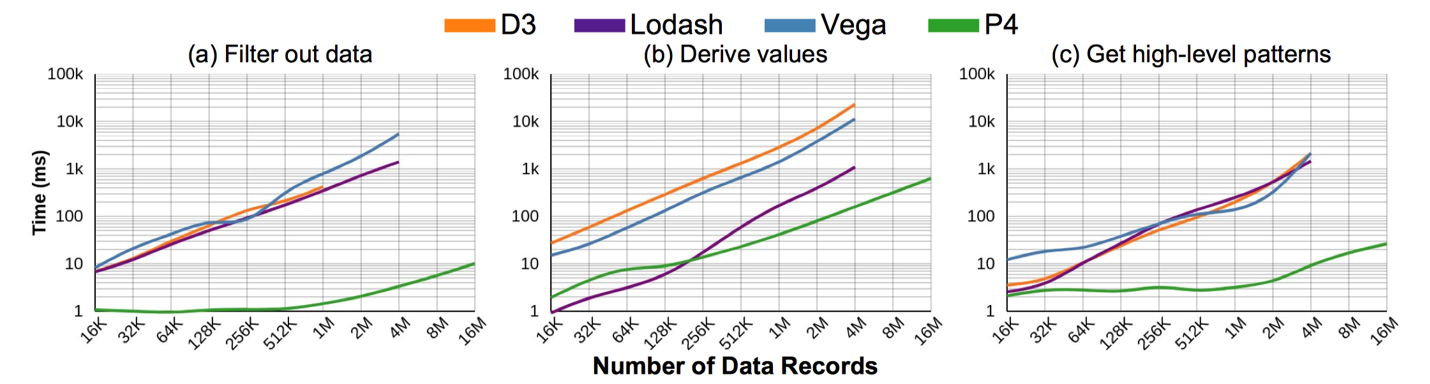
本文对比了 D3、Lodash 以及 Vega 三个 JavaScript 框架,就其在对数据进行 filter、derive 以及获取整体数据特征方面的效率进行比较。从图中可以看出,在大多数情况下,尤其是当数据量逐步增大时,P4 有更好的表现,这得益于 P4 利用了 GPU 对其进行加速。
2. 可移植性
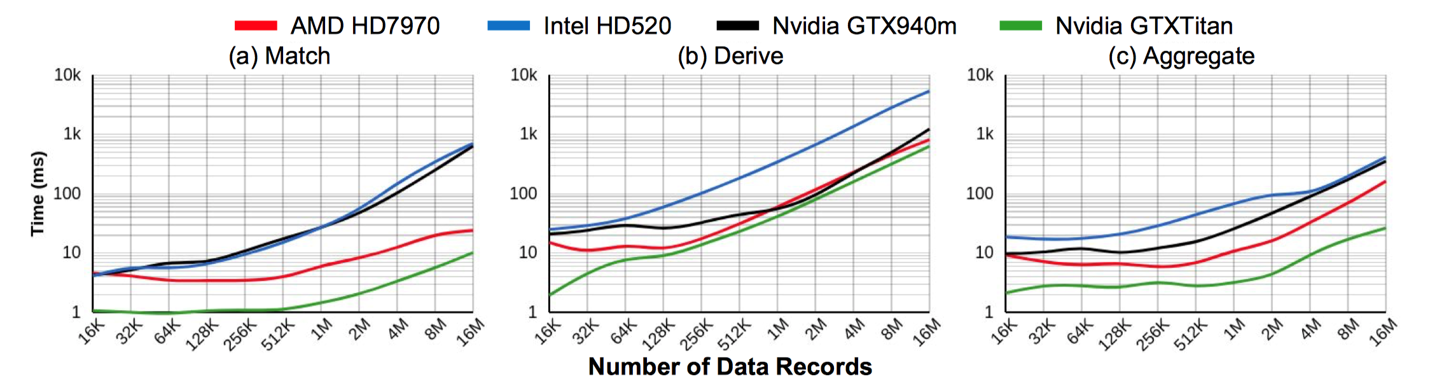
本文针对 P4 在不同显卡下进行了数据处理的性能评测。从上图中可以看出,当所使用的显卡性能越高时,处理数据所用的时间越少。
3. 可视化表现

本文将 P4 与其它三个可视化框架(D3、Vega、Stardust)进行对比,从对比结果中我们可以发现:
- 当数据到达一定规模时,其它三个框架由于浏览器或自身的限制没有办法正常绘制,而 P4 对于大规模数据仍能够正常绘制;
- P4 的初始化时间要大于 D3、Stardust 框架,因为 P4 需要进行编译 shader、传输数据等初始化操作;
- P4 的可视化时间在这四个框架中表现最好,这得益于 GPU 的高速绘制功能。
讨论分析
- 该框架仍有需要优化与拓展的地方。目前,P4 基于 WebGL1.0 实现,后续考虑迁移到 WebGL 2.0 上。另外,目前 P4 支持的可视化效果比较有限,后续考虑以插件的形式添加更多的功能;
- 该框架存在着一定的不足需要进行改进,最大的不足在于其对数据的操作对 GPU 的内存消耗较大,一些操作可能受限于 GPU 显存容量而无法进行;
- 未来考虑添加更多的 GPU 操作,比如添加 scan 元操作已进行平行排序数据,同时,在可视化方面,也考虑添加支持设定极坐标的位置。
总结
- 该框架将主流可视化框架的表现力和 GPU 计算与渲染的高性能相结合,融合了两者的优势;
- 该框架核心功能运用 WebGL 绘制,而标记组件等非核心不见采用不同技术实现,降低了开发难度;
- 该系统架构采用 Bottom-up 的形式组装功能,以数据元操作为基础,逐步组装得到更高级的功能。
✉️ zhaoxiaodong@zju.edu.cn