论文:Visualizing a Thinker’s Life
作者:Patrick Riehmann, Dora Kiesel, Martin Kohlhaas, Bernd Froehlich
发表:IEEE TVCG 2019
简介:本文提出了一个可视化框架,用于帮助读者理解和分析一个中等规模文本集合中的内容。
研究背景
目前,大多数基于文本的可视化和分析工具都是为了处理越来越大的文本语料库.由于这些文档通常包含数以万计的文档,因此单个文档对结果可视化的影响常常可以忽略不计,而且没有重点,所以目前很多可视化工作都是对信息的总结。但是当需要分析一个人或者少数几个人的文章时,对一个文档的可视化是必须的,因为需要从单个文档中获取信息并且分析他们之间的联系。本文以Bazon Brock的作品为研究对象,他是德国著名的艺术理论家、批评家,他的全部作品可以在网站上访问,涉及2160篇文档(本文将一篇文章、书籍的一个章节、一篇评论等视作一篇文档)。
本文工作及需求
本文的工作可以总结为以下4点:
- 本文提出了一个可视化框架,帮助读者理解和分析中等规模的文本集合(通常是单个或少数作者的作品集合)的内容。
- 设计了几种基于文档的可视化方案用于对Brock的作品进行探索。
- 可视化都对基于通配符的短语搜索敏感,该搜索允许对作者的作品进行复杂的查询。
- 对基于自动主题提取的可视化与基于专家知识的可视化之间的评估和比较。
作者与两名熟悉Brock的专家进行了交流,确定了分析Brock工作的几个需求:
- 每个文档作为一个单独的可视化元素。
- 识别、调查和比较Brock在他的著作中涉及的潜在主题,特别是随着时间的推移这些主题是如何变化的。
- 对单词和文本具有适当的搜索能力,特别是Brock作品中涉及的其他哲学家、同时代的人、出现的地点等。
- 所有可视化要对基于通配符的短语搜索敏感。
可视分析系统
TextGenetics
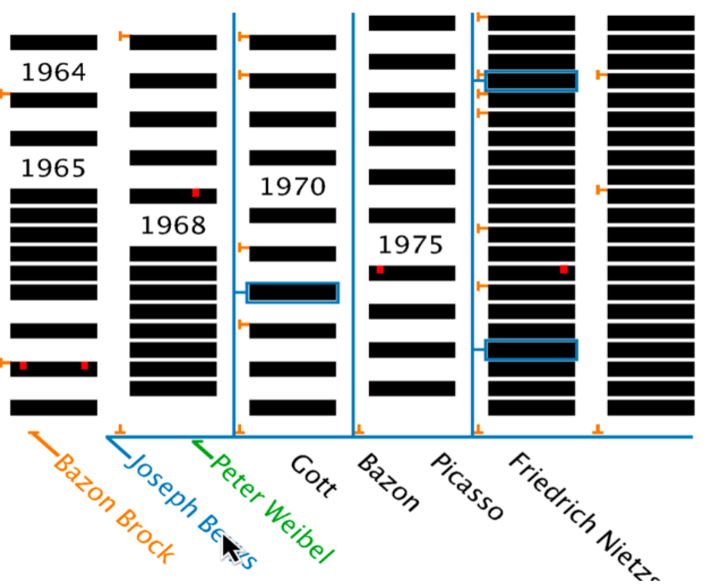
TextGenetics根据时间和结构方面可视化文本集合。作者选择了白色背景上的黑色矩形来代表文本集合中的文档,将文档按照垂直时间轴排列,并将分割到多个列中。每个年份作为一个单独的标签,表示这一年份发表的所有的文档。 两个黑条的垂直间距表示文档是单独发表还是与其它文档一起发表的。一些文档中的红色色块表示能体现Brock本文思想的部分(文章的精髓)在文档中的位置,这些是由读者手工标记的。

由于该可视化元素需要对搜索敏感,所以作者设计了包含3种灰度的编码,假如用户输入查询条件A,得到的搜索结果有AA、AB,并且用户选择查看AA的结果,那么文档不包含A这一检索条件的显示为图(a),文档中只包含AB的显示为图(b)、文档中包含AA的显示为图(c),当用户选中某个文档时,显示为图(d)。其中绿色的色块表示AB在文档中出现的位置。

当用户选中某个文档时,会提供关于这个文档更详细的信息,例如文档标题、标题和出版年份,以及大致的页数等,以及更详细的文章精髓和匹配的内容,微型词云详细的展示了文档的内容。

ConceptCircuit
ConceptCircuit可视化了Brock的作品与其作品中出现的某些重要的实体(人物、地点)之间的联系。用线路图显示实体与文档中的连线,作者提供了4种不同的颜色来区分不同的实体和连线。为了简化线路,作者采用了T型设计和L型设计的方案,当线路的终点采用L型设计,线路的其他连接采用T型设计。只有到鼠标覆盖到某个标签上时才展示完整的线路。
TopicAssembly
TopicAssembly展示了每个文档的主题分布、以及主题关于词的分布。每篇文档由一个多边形和周围的长条组成。多边形的大小表示文档的长度,周围长条的长度表示对应主题的权重,画布周围的词云表示每个主题对应的词分布的大小,单词的大小表示主题与单词之间的权重。作者分别设计了MDS(左图)和中心坐标系(右图)两个布局版本。

TopicGenetics
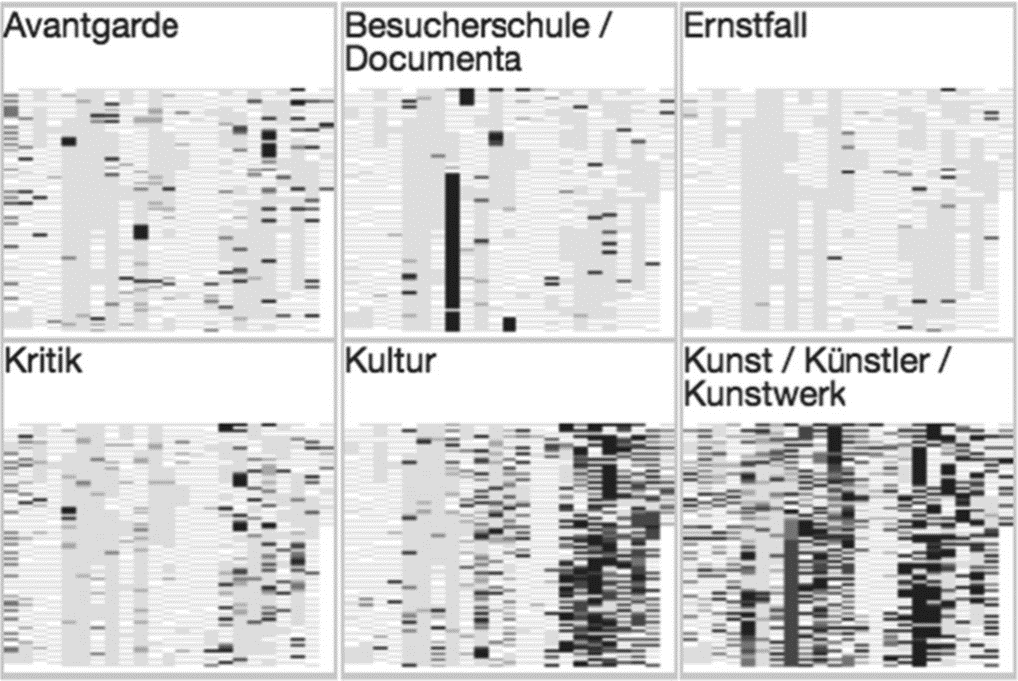
考虑到自动提取主题算法效果并不令人满意,TopicGenetics对专家策划的主题进行可视化,每个主题对应一个TextGenetics的缩略图,它可以反应Brock作品种某个特定主题在特定工作期间的重要性,允许用户根据主题过滤文档。
TopicTrends
TopicTrends使用时间轴的一维布局,用来比较不同主题几十年来的演变情况。每一行代表一个主题,途中选中了两个主题,红色表示某个文档与选中的主题具有较高的关联性(专家给出的权重较高),反之则用黄色,灰色表示该主题只在一个文档中出现。

TopicCalendar
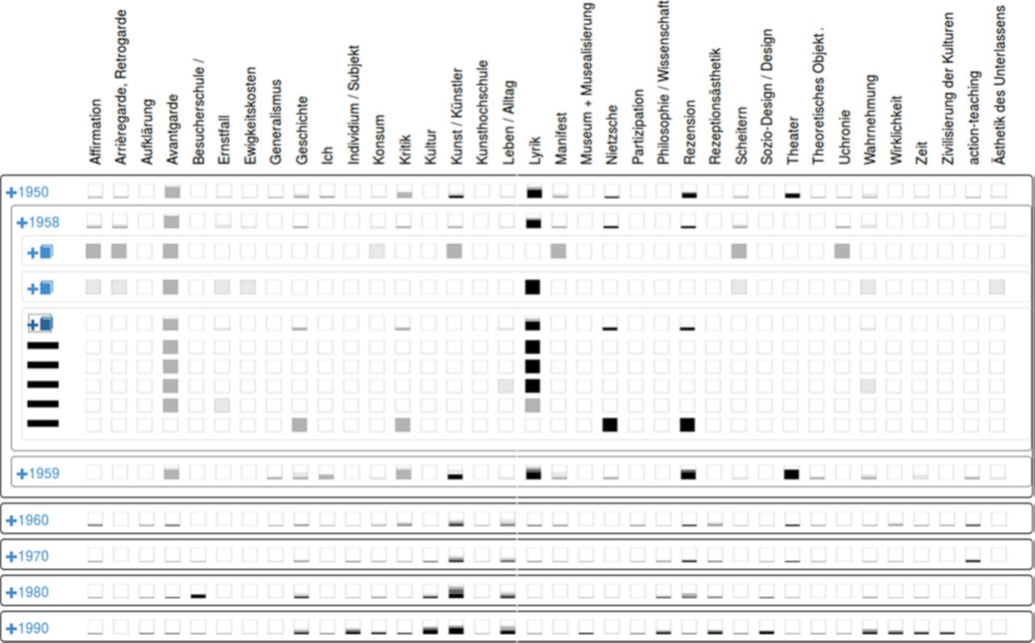
TopicCalendar用于提供不同年代重要主题的概览情况。它采用层次化的布局方式,顶层按照文档发表时间进行聚类,最底层显示每个文档,用户可以手动展开和合并。对于一个文档,作者设计了5个灰度用于表示一个主题与文档的关联性,对于一个更高层次的情况,作者采用了堆叠柱状图的设计。
查询后端
本文改进了Netspeak的搜索技术,支持用户输入通配符进行查询,如?(1个单词),*(任意单词数),[](单词的备选项)。作者建立基于Bazon Brock著作的n-gram语料库,并将训练后的1-gram、2-gram、…、n-gram单独一个文件存储,每个文件包含gram出现的次数(用于建立索引)、对应在文本中出现的位置(用于显示在文档中的位置)。总共占用1.2GB存储空间,其中500MB用于建立倒排索引,700MB用于记录对应在文本中的位置。
专家评审和自动提取主题算法的评估
第一次专家评审
作者将TextGenetics,、ConceptCircuit和MDS布局版本的TopicAssembly交给3个专家进行评审,得出的结果如下:
专家们发现框架的总体设计和布局令人愉快,结构清晰。
TextGenetics可以帮助专家发现Brock的主要工作,我们所有的专家都能一眼看出他的主要著作。点击文档会弹出关于该文档的详细信息,他们认为这对于分析特定的出版物来说是至关重要的。但是TextGenetics中多级灰度和绿色编码有点难以理解。
专家们对搜索结果的交互式的可视化效果得到了肯定。
ConceptCircuit也可以被正确理解
TopicAssembly难以理解,自动提取的主题并不令人信服。
LDA和HDP的评估
作者邀请两名专家提供了38个不同的主题,并且为每个文档赋予了权重。作者用LDA分别生成了5-100个不同的聚类,发现LDA的纯度(Purity)和软纯度(Soft Purity)都非常低,说明LDA的结果与专家提供的主题毫不相关。尽管HDP的结果较高,但是它生成的主题都集中在一个聚类上。
LDA和HDP的统计结果:

HDP的聚类结果:

第二次专家评审
作者邀请参与第一次专家评审的一位专家对系统进行了第二次评审,内容报考第一次评审的视图、以及重心坐标系版本的TopicAssembly、TopicTrends、 TopicCalendar,和 TopicGenetics。专家的反馈如下:
TopicGenetics 可以展示某个主题在Brock某个特定时期的重要性。在不阅读主题标签的情况下,快速浏览一下TopicGenetics就足以让我们的专家识别出特定的工作时期,比如80年代的“Documenta”时期,这段时期之后他跟之前变得不一样了。
重心坐标版本的TopicAssembly在展示潜在的主题上更加清晰,
TopicCalendar比TopicGenetics更能概括文章的主题。对于经验较少的读者来说,这是一个简单的入门点,以后可以分层次地进行探索。
TopicTrends适合比较多个时间上相似的主题,TopicGenetics适合研究单个主题。
ConceptCircuit主要是针对不太熟悉他作品的读者
多种不同的检索方法提高了效率
总结
最后文章做出了如下总结:
本文提出了一个可视化框架,该框架分析中等规模的文本集合。
TextGenetics、ConceptCircuit等视图与基于通配符的文本搜索结合得到了非常好的评价
LDA的自动提取主题的结果并不令人满意。
除了已经实现的短语搜索之外,通配符搜索音节或词形变化也是我们的专家所期待的功能。
✉️ zjuvis@cad.zju.edu.cn