论文:Graphicle: Exploring Units, Networks, and Context in a Blended Visualization Approach
作者:Timothy Major, Rahul C. Basole
发表:IEEE InfoVis 2018
简介:本文提出了一种针对大规模,多变量关系型数据,兼顾属性和结构探索的单元可视化方法。

研究背景
现实世界的很多数据集本质上都具有大型,多变量和关系性等特征,对数据的分析和决策通常需要同时考虑属性和结构信息。然而,现有的可视化系统和方法通常只能提供对各个数据单元及其属性的探索和对底层网络结构的探索之中的一个,很难兼顾这两种探索。这样的做法可能会错过潜在的分析机会,从而难以得到对数据的全面理解。吗
贡献
在多种unit visualizations之间构建了一种设计方法,有助于更好地理解基于属性和结构的探索之间的关系
设计了融合了多种unit visualizations技术的graphic系统,包括以下功能:
a. 通过布局方式的改变,允许进行灵活的大规模多变量网络探索。
b. 支持多焦点和多尺度数据属性和网络结构的视察。
c. 通过交互,允许用户智能地选择上下文和恢复已经过滤掉的数据。
相关工作
unit visualization与aggregate visualization 的定义
Park定义了unit visualization的内容,即在unit visualization中,数据集中每一个数据项使用一个单独的视觉元素进行映射,相对应的,把许多data case集合,用成一个视觉元素编码,就是aggregate visualization。如图所示的GatherPlots ,就是运用这样的可视化方法。这种方法使属性分布更好的展示出来,但是Park并没有把在unit visualization定义下网络可视化着重阐述。

network visualization
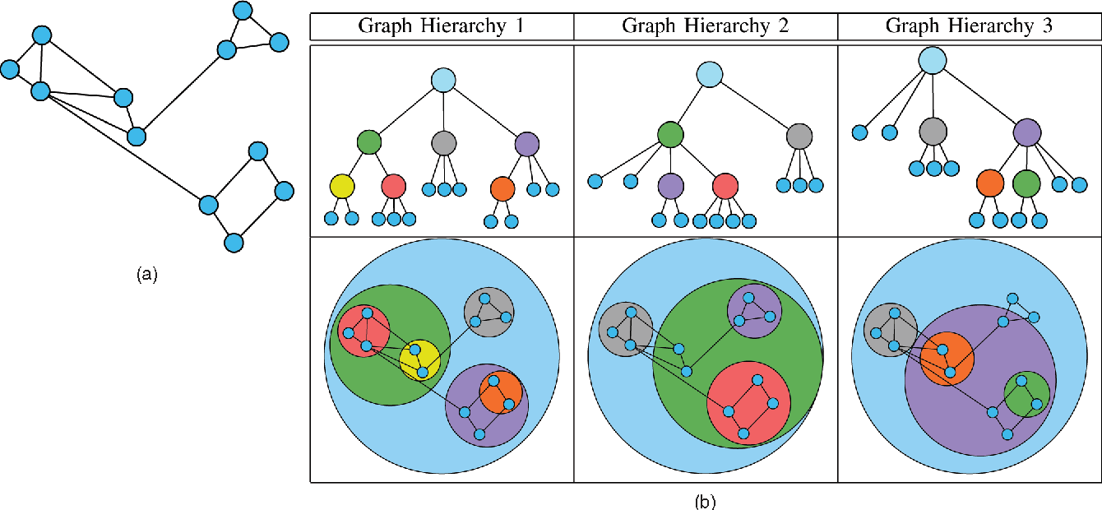
- 在大规模的图结构可视化中,常常需要简化展示信息。常用的方式就是根据拓扑结构或者属性信息将节点分组,这样一来,每个组别就可以被当成一个节点。如图所示利用层次结构将节点分组,简化展示信息。另一种方法就是用特殊的图形替换拓扑结构来达到替换的目的。
在多变量探索方面,Pretorius and Van Wijk的界面允许用户根据节点和边的属性,对它们进行聚合和分离操作,PivotGraph 将节点和边转化为网格中的点来表示。
目前的方法仍主要集中于结构探索或多变量探索中的一种。虽然The DOSA 和g-Miner支持了两种探索,但分别存在着不支持自下而上的探索和只支持数据等问题。
本文工作
作者利用了三种不同类型的可视化方法的长处:
用直接unit visualization,探索不同单元在用户所选属性上的分布。
利用network unit visualization,强调网络结构。每个单元的定位由其他单元以及之间的连接关系决定。重点支持基于网络结构的可视化探索方法。
用pack unit visualization,根据用户对属性的选择和过滤,将单元组织成不同的集群,每个集群装在一个容器中。这样,每个单元的位置就由集群的属性的决定。除了支持基于单元的可视化探索方法外,还同时支持多焦点、多尺度的探索方法。
这种混合探索消除了单元和结构之间的界限,兼顾了单元的属性探索和结构探索。
系统设计
系统界面
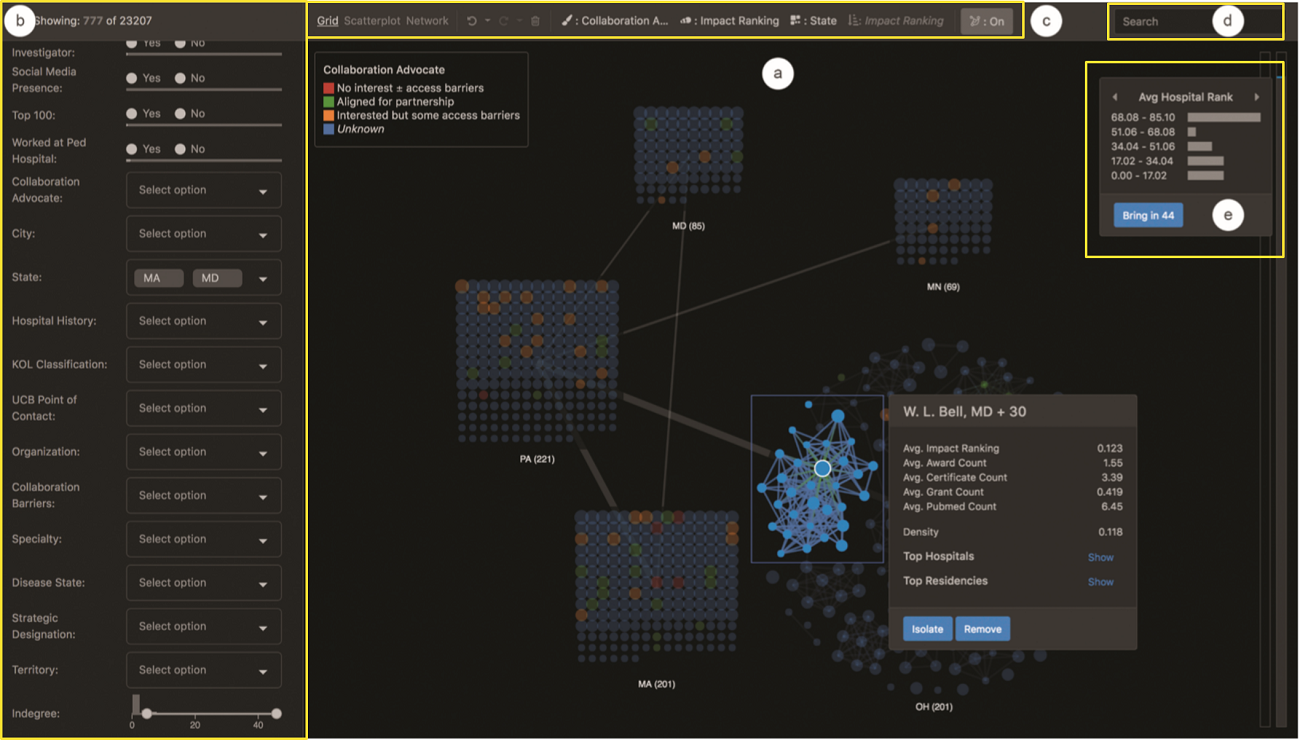
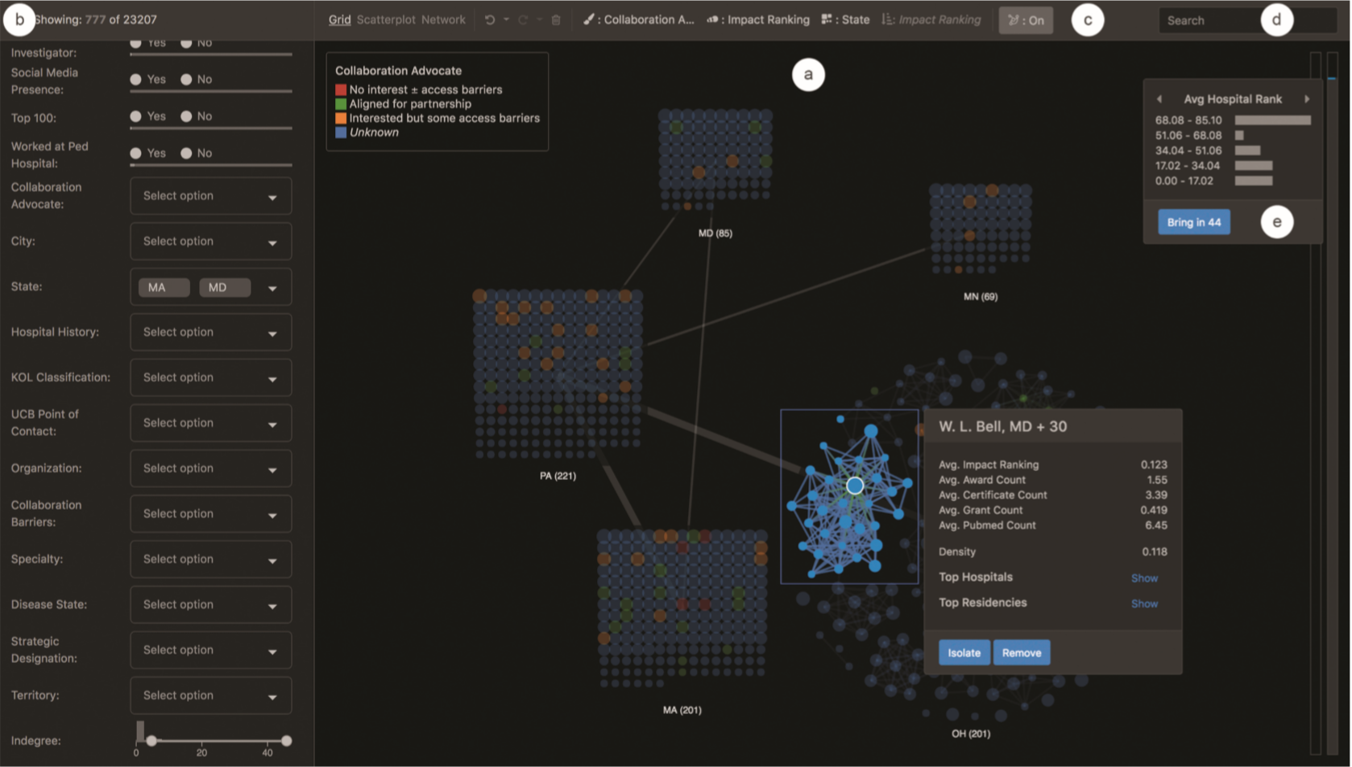
a是主界面,通过鼠标来支持缩放和平移。 这有助于系统更好地支持探索非常大的数据集。
b是用于属性过滤的筛选面板,过滤器面板含有许多交叉在一起的小部件。直方图和实心条显示相应数据属性值的分布,并在过滤或恢复单元时更新。
c从左到右依次是三种视图切换的选择器和撤销,重做,删除节点的控件,紧接着的四条视觉通道的选择器,分别代表了颜色,大小,高亮和排序所对应的属性编码,最右边的是切换力引导布局的按钮。最右边的两条长条分别编码了上一次筛选的节点集合和不可见的所有节点集合,用于上下文信息的恢复。
d是搜索栏。
e的这个信息框显示的是被筛选节点的分布信息。点击bring in 按钮可以把已经筛选过的节点重新带入到视图中。
单元探索
各个单元在图中由一个圆型粒子编码,在系统启动时,所有单元都被绘制到画布以允许用户对数据集有一个概览。如图所示:

(a)是单元未排序时使用圆形进行pack。
(b)是用户对某一属性进行了颜色编码,因此相当于执行了隐式排序。当单元按属性调整大小时,也会发生隐式排序。 用户还可以选择要排序的属性。默认的排序的顺序是,按用户指定的属性进行排序,然后是大小,然后是颜色。因为整个系统中,可用的大小变化远小于颜色的变化,因此我们首先按大小排序,以增加其辨别力。
(c)图所示的聚类网格按照从左到右,从上到下对单元进行排序。由于每一行的圆形个数是确定的。我们可以更直观地辨别单元属性值的差异。)
网络结构探索
网络视图使用力导向布局将单元定位在节点链接图中。 当节点由属性着色时,使用渐变对边进行插值。 与散点图和网格视图一样,他这个视图也支持度对每一个点的直接交互以及缩放和平移。在单独的grid视图中也可以通过长按某一个节点高亮显示它的一阶领域,二阶领域及全联通图(对应a,b,c),这种高亮不仅限于一个集群内,其他集群内有连接的(包括已经被过滤掉的)也会被高亮出来。

单元和边的透明度以及深色画布背景有助于解决遮挡问题。 透明度使重叠元素之间的界限更加明显,透明度的细微变化在深色背景下更加明显。

混合探索
在混合探索中,我们可以看到pack unit visualization和network unit visualization之间的联系。
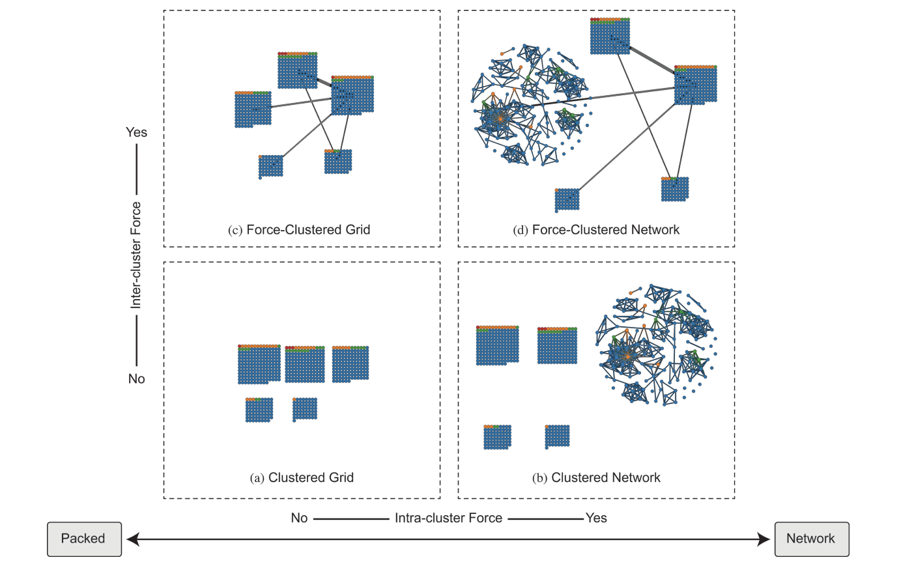
(a)显示的是未应用任何力导向布局的基本网格集群布局。可以将各个群集扩展为力导向图,从而创建(b)这张图。 将簇整体视为一个超级节点,在簇间创建一个力导向集群布局就形成了(c)和(d)。簇间的每一条边的粗细表示的是两个群集间连接的权重和。
上下文探索

通过圈选单元集合和或者点击簇标签可以高亮显示画布上的连接以及上下文栏中的被过滤的上下文信息(也就是说已经被过滤掉的连接节点也会被高亮出来)。 (b)图表示的就是选择了一个节点,显示它的完整网络,包括已过滤掉的连接单元。右边的那个小信息框显示的是被过滤的单元集合的摘要,并在上下文栏旁边显示一个值分布。用户可以遍历数据属性并选择要恢复到画布的过滤上下文的各个子集。也就是说你可以选择这里的任何一个。
评估
使用场景
数据:经过预处理后,得到的是23,207 条包含人口,教育,出版,组织等背景属性的美国神经学专家 和 44,256条联系的关系型数据。
过程:作者讲述了的故事是一个医药销售代表寻找适合推广一种正在的新药的医生。它通过之前讲到的几种探索方式,用Graphical系统找到了结果,下面这段话主要讲了他的探索过程。
他通过专注于指定的地理区域(明尼苏达州,马里兰州,马萨诸塞州,俄亥俄州和宾夕法尼亚州,后文中分别用MN,MD,MA,OH,PA代替)和非儿科神经科医生开始他的调查,将医生总数减少到4,116。接下来,他按州分组,他观察到宾夕法尼亚州(1,079)和马萨诸塞州(1,027)的神经病学家数量大致相同,明尼苏达州的人数最少(498)。由于他对具有高影响力排名的医生感兴趣,因此他使用单色调比例通过“影响排名”对单元进行着色。他注意到MA具有比例更高影响力的排名神经病学家。在左下角相应的行上显示,大多数神经病学家来自马萨诸塞州综合医院和布莱根妇女医院,证实了他对MA生态系统的了解。然而,他也知道这些医院不愿意合作。认识到基于MA的医生可能不是一个好的起点,继续他的探索,重点关注使用“Indegree”滑块(> 5)高度提及的医生,然后应用力聚类布局来识别结构信息。他立即注意到,在这个过滤的数据集中,基于MA和PA的医生与他的地理区域中的许多州有转诊联系,但基于MN和OH的神经科医生的转诊较少,这表明存在潜在的联系机会。他通过“协作倡导”属性对节点进行着色,并注意到MN没有任何医生协调合作,但OH有几个。想要了解OH内的推荐网络结构,他激活群集网络视图并通过“影响排名”调整节点的大小。他观察了几个相互连接的网络集群,并确定了一位医生(贝尔博士),他们与合作伙伴关系保持一致,并且与许多未知的医生相关联。他选择贝尔博士的子图,发现他的影响力网络中有74名医生,其中49名已被过滤掉。他专注于这个子图,并将他指定区域之外的已经被过滤掉但仍与之有连接的状态恢复到画布,包括CA,RI和其他。他还发现,这些医生中最常见的医院是OSU Wexner医疗中心。他注意到有希望的领导以及任何其他桥接节点,希望他的同事可以提供帮助。
Expert User Study
人员
2名区域协调员,1名医疗主任
工作5-30年
熟悉数据集中的特定医师
过程
- 1小时课程学习
- 30分钟功能解释
- 自由式探索
反馈
优点
- 有助于理解某一地域整体概览
- 自下而上探索方便有用
- 可以预测意见领袖
不足
- 对数据的担忧,连接类型不足
- 对上下文栏的设计表示困惑
讨论
在最后的discussion中,作者也提出了一些改进的空间:
\1. 定性属性的基数对可伸缩性有影响。随着基数的增加,分组到群集时碎片会增加。如果有很多小组,画布上的单位会变得非常分散。缩放和平移可以缓解问题,用户可以通过直接选择快速选择和删除小组以清理画布。
\2. 当前的工作和其他unit visualization方法没有解决单元和单元容器之间的多对多关系(即基于集合的单元成员资格)。比如说,这里所有的医生所对应的属性都是唯一的,每一个医生对应唯一的医院等。由于分组仅支持定性数据,因此在支持的数据类型有限制。
✉️ zjuvis@cad.zju.edu.cn