论文:TopKube: A Rank-Aware Data Cube for Real-Time Exploration of Spatiotemporal Data
作者:Fabio Miranda, Lauro Lins, James T. Klosowski, and Claudio T. Silva
发表:IEEE InfoVis 2017
本文基于Nanocubes的工作,添加了top-k查询的功能,使得data cube可以被运用到更加广泛的场景中。
本文针对的数据存储类型是关系型数据,也就是表格数据,例如:
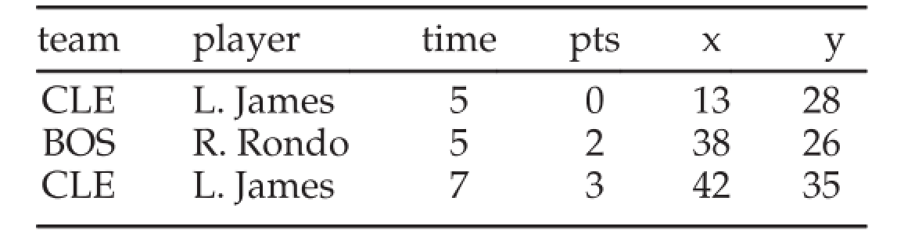
而要进行的查询可以用如下SQL表达:
SELECT player,count(*) AS shots FROM table
GROUP BY player
ORDER BY shots DESC LIMIT 50
其中,count可以是其他度量。本文只能做基于线性度量的查询,例如求和等。
首先,Nanocubes针对数据的不同纬度进行了不同粒度的划分,同时在时间维度上采用了一种离散加和表(Summed area table, SAT)的存储和计算方式,见下图:
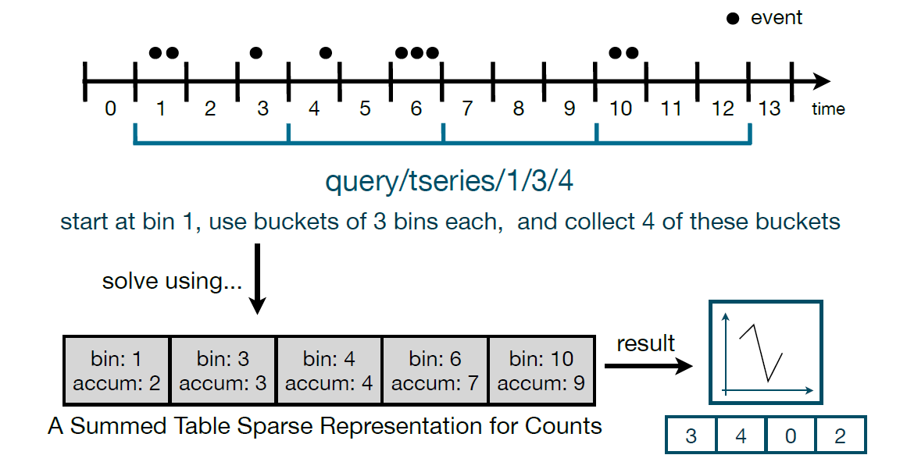
这里任意区间的数量统计都可以用两个数值相减得到(例如,4-6之间的数据点数量4=7-3)。
在此基础上,Topkube添加了排序信息:
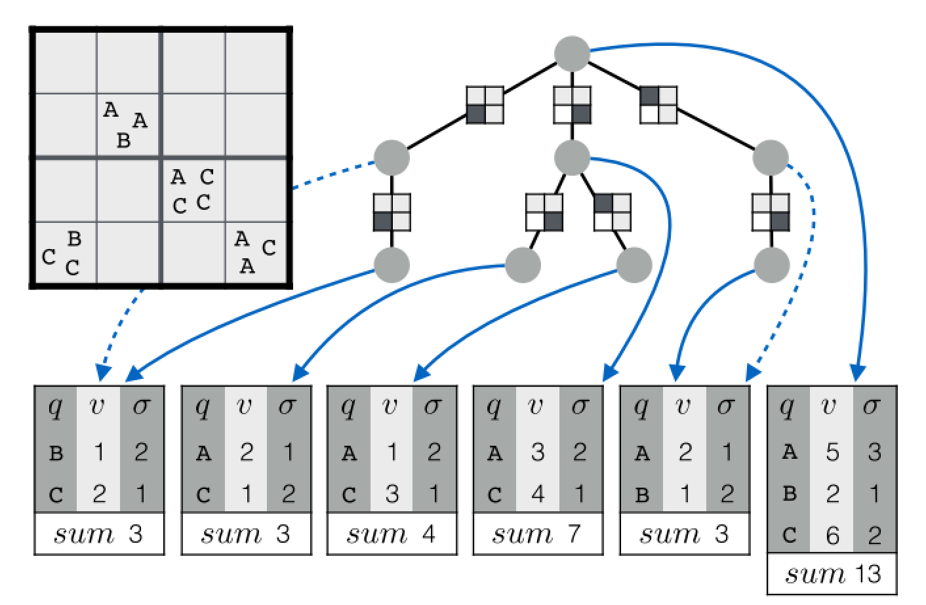
第一列是key,第二列是value,第三列是这个value在这个方块中的排序
当查询只设计单一cube时,结果可以通过直接访问排序信息得到,但大部分查询不会如此简单,例如下图中,就包括了624个空间cube和3个时间cube:
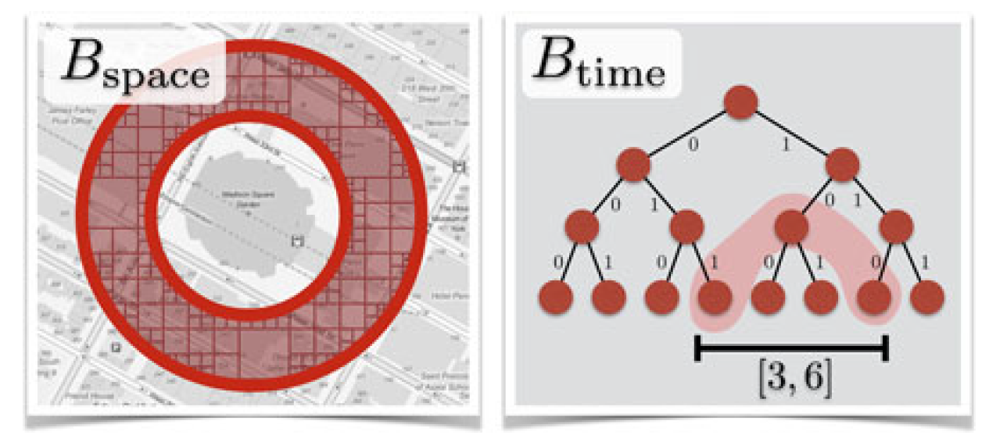
所以,还需要一个快速的算法能够统合多个cube,本文提出了两种算法。
算法1,Sweep algorithm:

这个算法看着复杂,其实就是一个堆排序。通过维持一个以key进行排序的堆,在不断pop堆顶的过程中保证key的排序,于是相同的key被连接在一起(例如(A,2)(A,1)(B,1)(C,2)(C,1)(C,3)这样的顺序)(第10行)。
然后就可以通过一次线性的扫描计算出所有相同key的对象的value总和。此时通过维持一个尺寸为k的堆(InsertK函数),就可以在插入过程中动态的保持top-k的获取。
算法2,Threshold Algorithm(TA):

其实也很简单,就是贪心算法+终止条件。选取某个cube中拥有最大value的key先进行计算,弹出所有相同key的对象求和,然后不断重复。这个过程中同样保持与上面相同的一个尺寸为k的堆。
终止条件就是当(1)找到的key已经多余k的(2)当前剩余的所有cube的最大value的和也小于已有的第k大的结果。
TA算法必须在所有cube中有相近数量的对象数时才能有很好的效率,所以作者采用了一种混合算法,通过sweep先将一些比较小的cube合并,然后在进行计算:

其中theta表示一个cube尺寸的度量,越大则sweep合并后的结果越接近TA的理想状态,等于1时TA算法不生效。而越小则sweep算法需要的计算越少,等于0时等于直接使用TA算法。
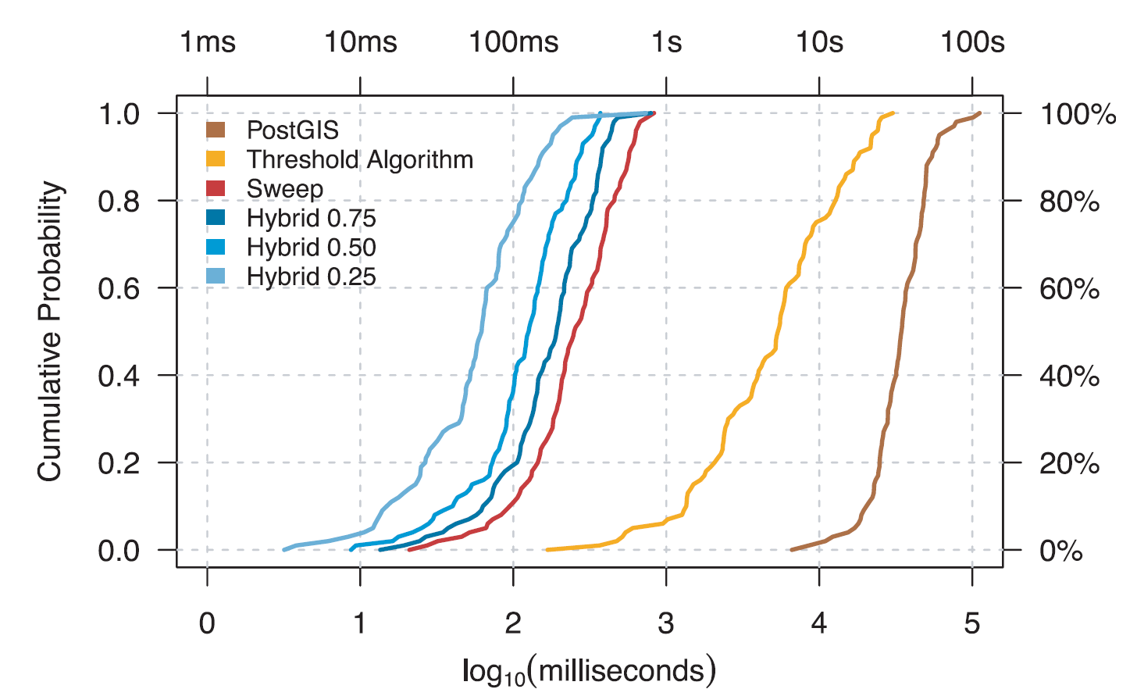
从最后的实验来看,取0.25是比较理想的一个数值:
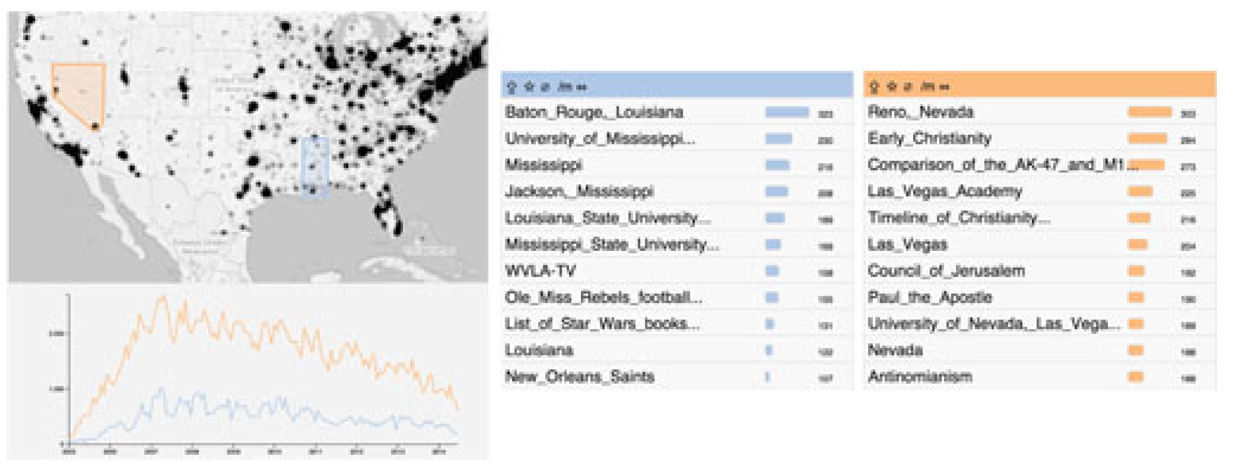
一些用例展示:
wikipedia数据,进行空间范围选取:
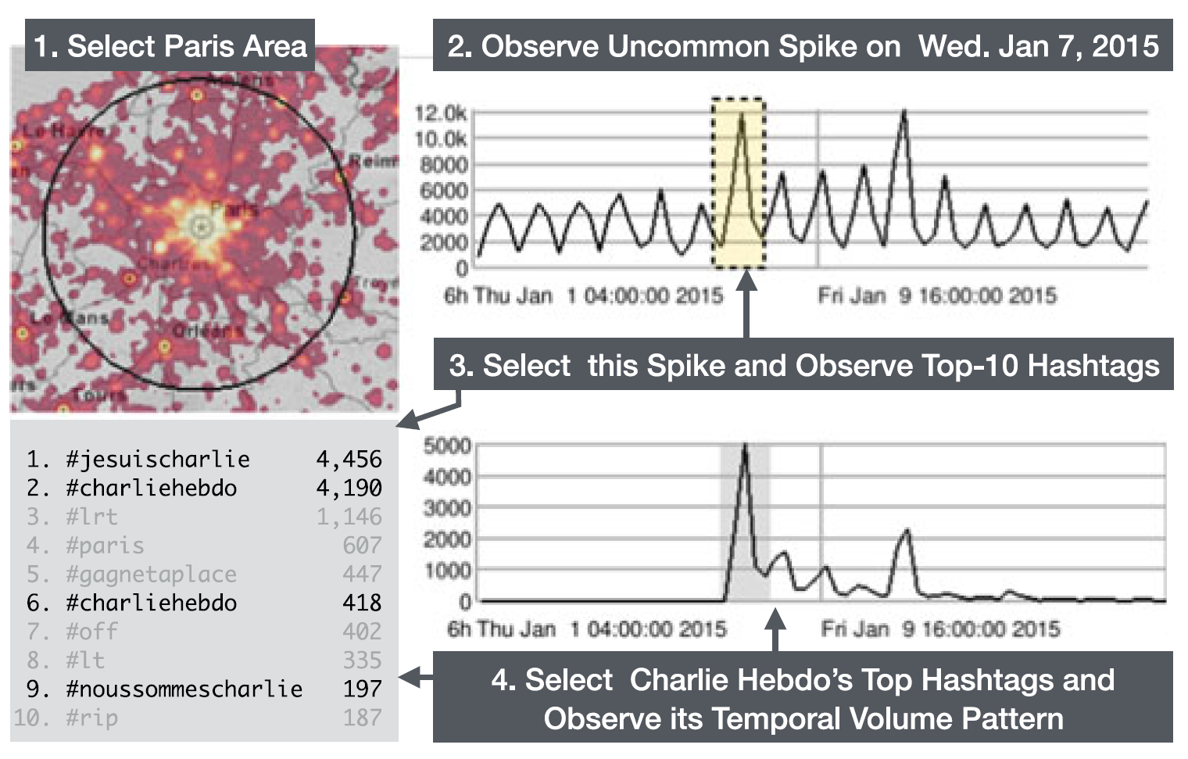
flickr数据,进行时间范围选取:

microblogging数据,进行空间、时间和tag(key)的选取:
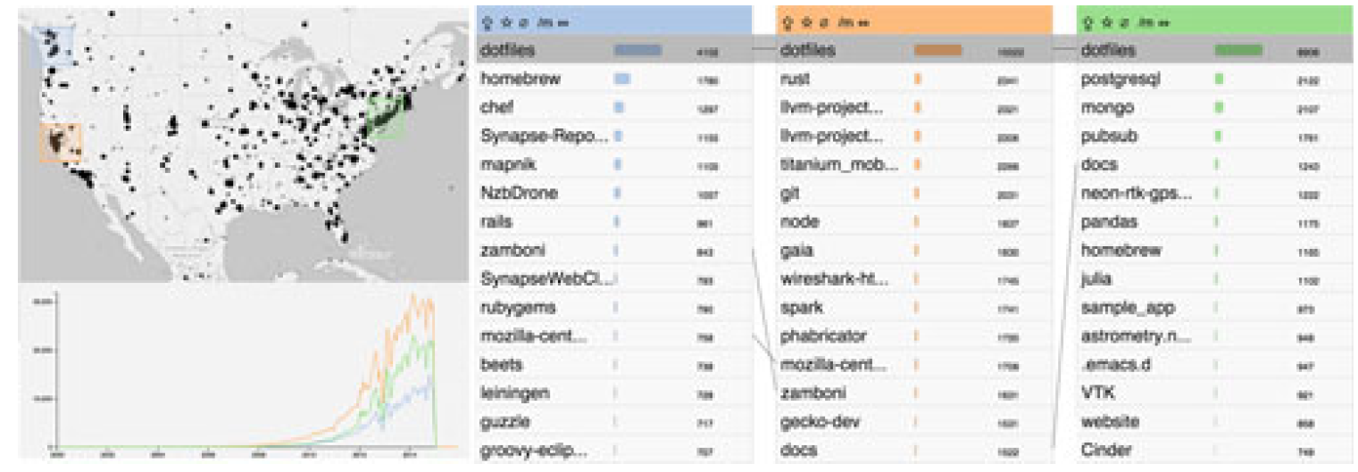
GitHub数据:
✉️ zjuvis@cad.zju.edu.cn