论文:Progressive Learning of Topic Modeling Parameters: A Visual Analytics Framework
作者:Mennatallah El-Assady, Rita Sevastjanova, Fabian Sperrle, Daniel Keim, and Christopher Collins
发表:IEEE VAST 2017
介绍
主题模型是一类用于将文档根据在其内部的主题分布归类的非监督机器学习方法。主要思路为,根据文档及其中的词汇建立起文档描述向量,从而求解出文档中的主题分布与每个主题中的关键词分布。主题模型是一类非监督的黑盒模型,本文希望能帮助理解主题模型的输出,并使得所用的模型适应当前数据与任务的特性,以增强模型的可靠性。而可视分析恰恰能通过人的参与和反馈,完成数据和任务驱动的模型构造过程。本文的主要贡献包括:
- 提出了一个有人参与的主题模型循序渐进改进方式
- 设计了四个根据四个任务驱动的可视化窗口
- 通过实证测试与定性实验验证了方法的有效性
方法框架
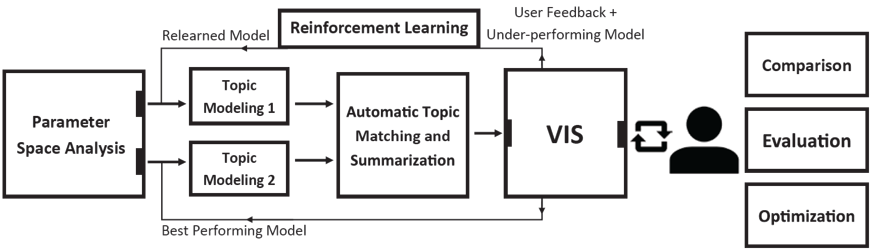
上图为本文提出方法的总体框架,可以分为以下三个部分:
- 参数空间分析(左)
- 可视分析界面(右)
- 话题收敛过程(中)
可视分析界面
本文提供了四个不同粒度的可视分析界面(如下图),分别对应了以下四个分析任务:

T1.主题模型输出概览
T2.理解主题描述
T3.检查语料库特征分布
T4.文档相关反馈
主题模型输出概览

如图,主题模型输出概览界面中,左边跟右边的两列分别是由两个主题模型计算出来的多个主题,根据他们之间的匹配度从上到下排列,原点大小表示属于这个主题的文档数量。连线的颜色表示主题匹配对应的三种结果:绿色完全匹配,蓝色仅相似匹配,黄色不匹配,线条透明度表示匹配度大小。中间的一列是相似的两个主题间的常用词汇。选择某一对感兴趣的主题后,进入下一层的主题总结视图。
主题总结
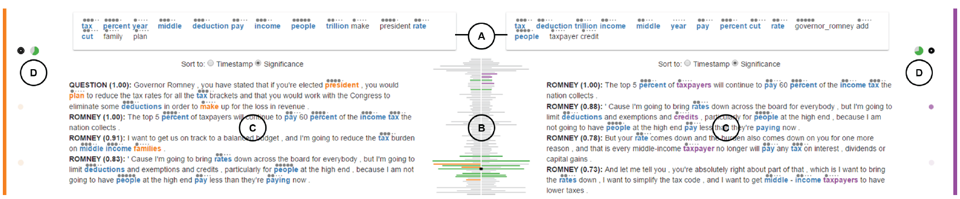
界面上方的两个框内分别是两个主题的关键字,下方分别为表示与相应主题最相关的十句话。文中,蓝色单词表示出现在两个主题中的词汇,橙色或紫色表示只出现在橙色主题或紫色主题中的词汇。每个关键词上方有五个圆点表示该关键词与主题的相关性。中间对称的柱状图中,每一个柱子表示一篇文档,长度表示该文档的长度。同时属于两个主题的文档用绿色表示,只属于单个主题的文档用该主题的颜色表示(橙色或紫色)。通过展开中间的语料库柱状图可以将其展开,进入参数分布分析界面,研究语料库的结构以及文档的特征和参数分布。
检查语料库特征分布
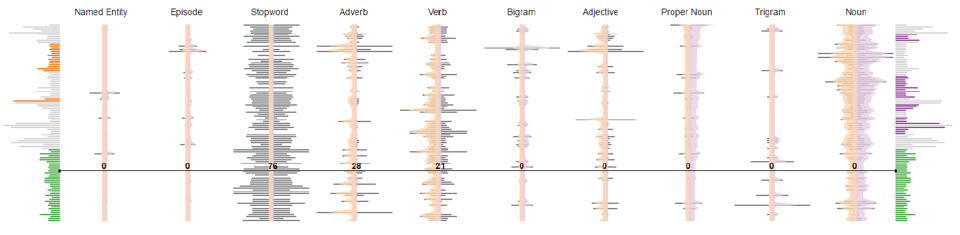
上图显示了整个语料库在各个特征上的分布。每一列用一个小提琴图表示一个特征(词类)。每一个小提琴图中,背景灰色的柱状图表示该文档中,该词类在该文档中出现的频率。小提琴形状(两边)表示两个主题中该词类的参数分布(某词类在某文档中的权重)。
文档相关反馈

此视图中,用户可以通过在下方的柱状图中选择某一篇文档,对该篇文档的两个主题进项反馈,通过在 C 区域选择左边或右边的主题,以及上方的确定性分数,将更适合这个文本的主题反馈给系统。
话题收敛过程
话题收敛过程作用于参数空间和文档关键词向量,系统通过决策滑动条决定关键词的重要性变化。被用户认为好的模型将不会在收敛过程中受到改动,不好的模型会用新的根据决策滑动条确定的参数空间与文档关键词向量代替旧的参数,重新进行计算。
实验
阶段一:模型改进
- 任务:在 2 小时内通过可视化界面改进主题模型
- 数据:2012Romney 与 Obama 总统竞选辩论
- 实验控制:2 个 LDA 模型,各自产生 9 个主题
- 被试:2 语言学家、2 政治科学家、2 计算机科学家
阶段二:模型评估
- 任务:对给出的主题模型结果打分评估
- 数据:2012Romney 与 Obama 总统竞选辩论
- 被试:3 语言学家(不参与阶段一实验)
实验结果:主题的改进率与模型的不确定性在整个学习改进过程中逐步降低,语言学专家纷纷认为本文的工作非常有用。
✉️ zhangtianye1026@zju.edu.cn