- 论文原标题:What Would a Graph Look Like in This Layout? A Machine Learning Approach to Large Graph Visualization
为了为图数据挑选一个合适的布局,论文提出了一种机器学习方法,基于用 graph kernel 计算的图拓扑相似度。这种方法可以显示图结构在不同的布局方法下的外观,并且可以估计这些图在布局下的美学度量。文章的贡献点是提出了一个可以用来设计 graph kernel 的框架。
个人评述
这篇文章简直是一篇集大成的文章,提出了一个重要的思想:用已有的数据集来生成新的可视化效果。竟然不是 2017VIS 的 best paper?通篇下来我竟然没有看出什么特别的缺点,要有的可能只是:
- 特征向量只和 DGK 进行了比较,可能不够丰富
启发:
- 本文的所有结果基于一个假设:拓扑相似的两个图,布局结果也应该相似。那么我们是否可以引申?比如图的傅里叶变换结果是否可以用于计算拓扑;如果有探索交互数据,拓扑相似的图,其探索交互过程也应该相似,就可以用来做交互推荐。
一、介绍
挑战:给定图数据,特别是大规模的图数据,生成其节点链接布局耗时繁琐,开销巨大。
解决:一种比较好的解决方案是通过一些预测方法(predivctive methods),在机器学习里面,已经有很多预测方法用于预测图的属性,最知名的方法就是图核(graph kernel),可以用图核来支持一些核化机器学习(kernelized machine learning),比如 SVM。
贡献:
- 一种快速、精准展示图在不同布局算法下的结果的方法;
- 一种快速、精准的可以评估图的布局结果美学指标(aesthetic metrics)的方法;
- 一个基于 graphlets 的设计图核的框架;
- 一次示范,以证明图核对大规模图可视化的有效性
二、背景
给定图数据$G$,如何得到某种图布局?
如果已经有一个数据集${G_1, G_2, \ldots, G_N}$,其中包含了大量的图数据和对应的图布局结果。
假如可以从中找到一份图数据$G_k$,它的拓扑结构跟$G$最相似,那我们就可以用它的图布局来当做$G$的结果。

那么问题来了,如何度量两份图数据之间的拓扑相似度?
拓扑相似度度量
也叫做:graph matching, graph comparison, network alignment。
- 老方法:isomorphsim relation, graph edit distance, graph measures。但复杂度太高,或者普适性不强。
- 新方法:图核(Graph kernel):可以支持 kernelized machine learning,对图之间进行成对比较,得到图和图之间的拓扑相似度。可以支持 SVM 等方法。
kernel,或者叫做 kernel function,是一个比较两个输入$\chi$之间相似度的函数$\chi \times \chi \mapsto \Bbb{R}$,经常被定义为特征空间$\cal{H}$中两个向量的内积:
其中$\phi$将输入$x$映射到高维特征空间:$x\mapsto \cal{H}$
现有的图核:walks, shortest pathes, subtress, cycles, graphlets,前面几个都有较高的时间复杂度($O(|V|^3)$或者更高),或者不适合无标记图。graphlets kernel被引入已解决上述的问题。
- graphlets:图元,指的是一系列异构的(isomorphism)导出(indeced)子图。
isomophism: two graphs $G = (V,E)$ and $G’ = (V’, E’)$ are isomorphic if there exists a bijection $f: V \rightarrow V’$, called isomorphism, such that$ (v_i, v_j) \in E \Leftrightarrow (f(v_i),f(v_j)) \in E’ \text{ for all }v_i,v_j \in V$.
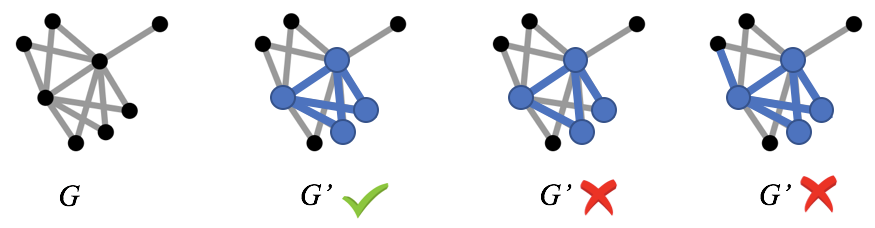
indeced: Given a graph $G$, a graph $G’ = (V’,E’)$ is a subgraph of $G$ if $V’\subseteq V$ and $E’ \subseteq E$. A subgraph $G’ = (V’,E’)$ is called an induced(or vertex-induced) subgraph of $G$ if $E’ = {(v_i,v_j)|(v_i,v_j) \in E \text{ and }v_i, v_j \in V’}$, that is, all edges in $E$, between two vertices $v_i,v_j \in V’$, are also present in $E’$.
下图是一个导出子图的示例:
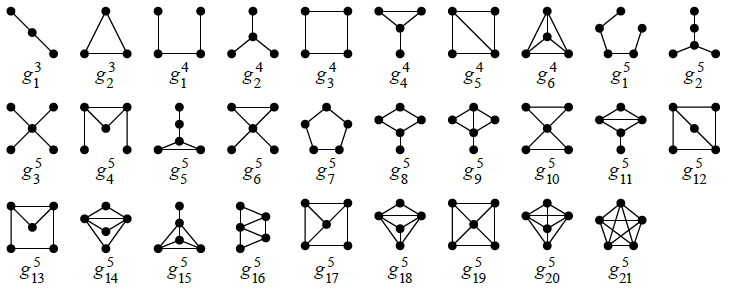
下图列举了所有 3 节点、4 节点、5 节点的 graphlets:
$\phi$:如何对输入$x$,生成其高维特征空间$\cal H$的特征向量$\phi(x)$,以便进行内积,生成 graph kernel?这里,$x$也就是图$G$。
通过计数图中相互独立的图元的个数,统计它们的频率分布,将图元的频率分布向量,得到图的特征向量。
三、方法
设计 graphlet kernel 的框架
一个 graphlet kernel 的设计,需要以下步骤:
- 采样图元,统计个数(采样方法)
- 计算图元频率向量(频率计算方法)
- 求两个图元频率向量的内积(内积方法)
采样图元
穷举所有图元开销过大,要穷举所有 k 节点图元,开销是$O(|V|^K)$。故而采用随机采样方法,主要有两种:
- 随机节点采样(Random vertex sampling (RV)):为了找一个 k 节点图元,通过随机找 k 个节点,用它们原有的边连接。但对于真实世界的网络,$|E|\ll O(|V|^2)$,那么大部分随机采样的图元将会是不连通的。当只想采样连通图元的话,就需要很多轮迭代才能采到足够数量的图元,时间开销会很大。
- 随机游走采样(Random walk sampling (RW)):基于随机游走的采样方法,还没被用于设计 graphlet kernel,这种采样方法可以用来采集连通图元。
计算图元频率向量
图元频率被定义为每种图元$g_{i}$的相对频率,以此构成的频率向量,作为图的一个特征向量。一共有两种方法用来计算频率向量:
线性比例变换(linear scale, LIN):也被叫做图元浓度(graphlet concentration),是每种图元在图中的百分比,一些工作用每种图元的加权数量$w_i$来定义它(文中并未指定权重$w_i$的定义):
对数比例变换(Logarithmic scale, LOG):类似于节点度分布,图元频率分布也经常服从幂律分布,这会导致缺少关键信息的图元会远高于那些信息丰富的图元,故而一些工作用了一个对数变换来解决这个问题,其中$w_b$是一个基础权重,来防止$log(0)$:
定义内积
文章引用了以下几个计算特征空间中的内积的 kernel 函数,内积结果即为两个图的相似度:
余弦相似度(Cosine similarity,COS):现有最多的 graphlet kernel 使用欧氏空间中的两个向量的点积后产生的点积产生的矩阵的归一化结果作为核函数,也就是两个向量的余弦相似度,也是两个向量的
高斯径向基函数核(Gaussian radial basis function kernel, RBF):经常被用在机器学习中,$\sigma$是一个自由参数
拉普拉斯核(Laplacian kernel,LAPLACIAN):是 RBF 核的一种变种:
预测图的布局结果(WGL)
文章把这个方法称为WGL(What Would a Graph Look Like in This Layout? )
文章基于相似度,设计了一个类似kNN的最近邻算法,用来找出和输入图$G{input}$拓扑结构最相似的 k 个图,并展示他们已存在的布局结果给用户。用户就可以通过观察这些拓扑相似的图来预测$G{input}$的结果,步骤一共分三步:
- 计算准备好的已存在的图(每个图都预先计算好了布局结果)和输入图$G_{input}$的相似度
- 移除不满足约束条件的图(因为有些图,虽然它的特征向量和$G{input}$很相似,但是因为节点过多或者过少,事实上应该不算做相似图,比如下图:图元频率分布的四个例子,文章中设置了一个约束条件,即相似图的节点数,不能多于$G{input}$的 2 倍,或者少于$G_{input}$的 1/2)
- 选出$k$个最相似图
图元频率分布的四个例子
下图中,x 轴表示了图元的种类,y 轴表示了图元的频率。图 a 和 c 的图元频率分布相似,且节点数量也相近,我们可以认为它们两者是拓扑相似图;但是,虽然图 b 和 d 的图元频率分布相似,但是因为节点数量相差过大,它们事实上不应该算作相似图。
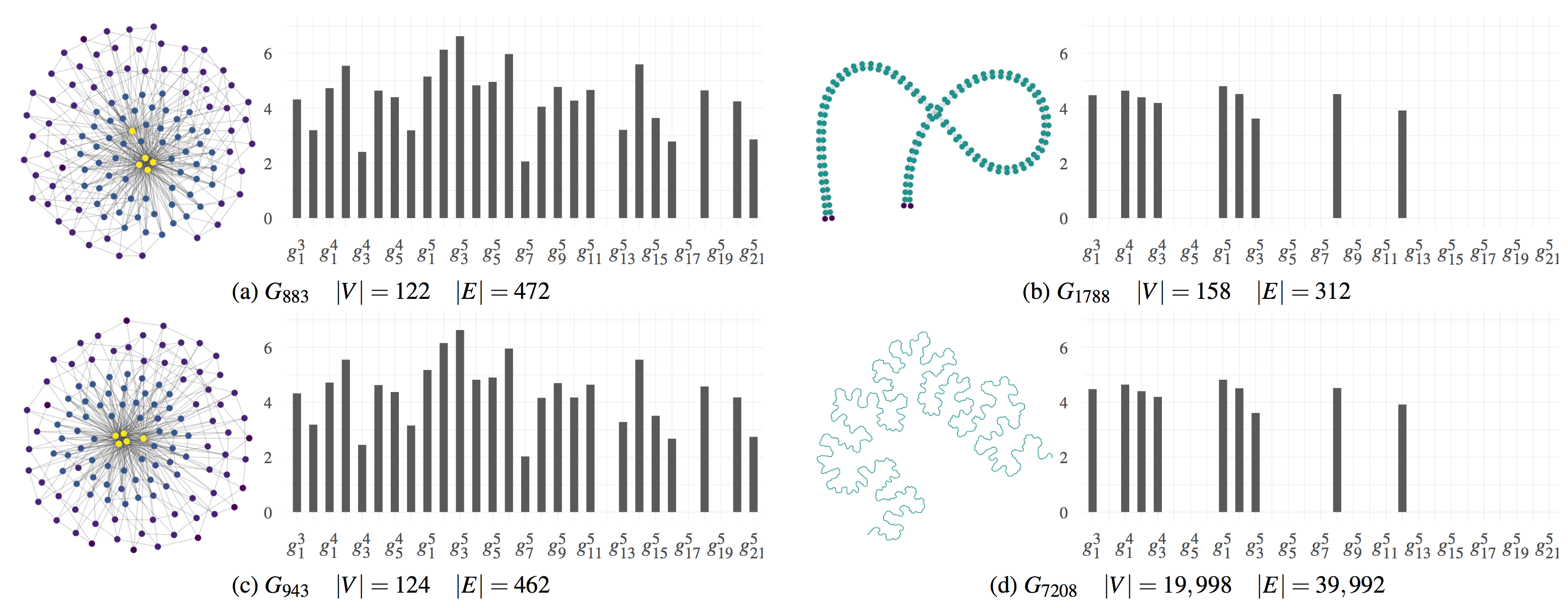
预测图的美学指标(EAM)
文章把这个方法称为EAM(Estimating Aesthetic Metrics)
美学指标是用来评判一幅图布局的良好状况的一系列指标,既然计算一个图的实际布局结果非常耗时,我们可以训练一个回归模型,用于预测某个新的输入图的美学指标,而不用实际计算布局结果,训练步骤一共分三步:
- 准备训练数据(一系列的图,以及它们在不同布局下的布局结果和相关的美学指标)
- 用 graph kernel 计算训练数据中的图和图之间的相似度
- 训练回归模型
之后,我们就可以通过计算新的输入图和训练数据中的其他图的相似度,用已有的回归模型,估算输入图的美学指标。
四、评估
估算布局的美学指标
评估目的
为了回答一下几个问题:
- 精确?在不计算实际布局的情况下,是否能够精确地估算布局的美学指标?
- 快速?能否快速的获得估算结果?
- 更强?由上述框架产生的 graph kernel 是否能够在计算时间和精度方面都优于最先进的 graph kernel?
实验设计
数据集
- 收集了包括并不限于社交网络、网络文档网络、几何网络的 3700 个图。在不失一般性的情况下,把具有多个连通部件的图拆成几个分离的图(一个连通部件对应一个图)。
- 之后剔除少于 100 个节点的图,因为这些图的计算会特别快,从而影响实验结果。
- 最后剩下 8263 个图,节点数范围从 100~一亿一千万,边数范围从 100~18 亿。因为某些图在计算布局的时间上花了 10 天以上或者内存跑完了,这些图就被抛弃了。
kernel 选取
一共十二个(2×2×3)核函数,是由生成 graph kernel 的框架中提到的 2 种采样方法(随机选点 RV 和随机游走 RW)×2 种图元频率计算方法(线性 LIN 和对数 LOG)×3 种内积函数(COS, RBF 和 LAPLACIAN)组合而成。
并且,选取了一个目前已有的最先进的 graph kernel,DGK(Deep Graph Kernel)进行比较。
对于所有的 kernel,每幅图都采样了 10000 个有三个、四个、五个节点的图元(一共 49 种图元,其中 29 种是连通的)。因为计算开销的问题,这三种图元用的比较多,而 6 节点以上的图元一般比较稀有。并且 RW 采样只考虑连通图元,RV 采样考虑非连通和连通的图元。
布局方法选取
这里只考虑二维平面,用直线绘制边的布局方法。
因为时间问题,不可能计算所有的布局方法。所以根据(1)使用的广泛性,(2)是否有公开实现,(3)是否被证明优于同类其他方法,文章选取了 5 种布局方法类别中的 8 个具有代表性的布局方法。
- 力引导(Force-directed methods):电子模型中选取了 Fruchterman-Reingold (FR),能量模型中选取了 Kamada-Kawai (KK)
- 基于降维的方法(Dimension reduction based method):选取了 High-Dimensional Embedder (HDE)
- 谱方法(Spectral method):选取了 Koren 的方法
- 多层方法(Multi-Level methods):选了 sfdp 和 FM3
- 基于聚类的方法(Clustering based methods):选了 Treemap based layout 和 the Gosper curve based layout
美学指标的选取
文章选取了其中四个有标准形式,具有一般性的,切能够在合理时间内计算得到的美学指标:
Crosslessness ($m_c$):在很多研究中,边的交叉数量被作为一种最重要的审美标准,边交叉越少越好:
其中,$c$是边的交叉数,$c_{max}$是边交叉数的近似上界,被定义为:
Minimum angle metric ($m_a$):被定义为点$v$上的边的最小夹角和理想的最小夹角的平均绝对离差:
其中,理想最小夹角,定义为点上的所有边刚好平分 360°:
Edge length variation ($m_l$ ):根据边长的变异系数计算得到:
其中:
- $l_{cv}$是边长的变异系数
- $l_\sigma$是边长的标准差
- $l_\mu$是边长的平均值
Shape-based metric($m_s$):可以用 mean Jaccard similarity(MJS)方法,比较某个图和标准图(一般认为标准图的结构良好,属于较美的图)的相似度,定义该图的$m_s$
其中,$G_1=(V, E_1)$和$G_2 = (V, E_2)$是所有节点都相同的两个图,$N_i(v)$是图$G_i$中$v$节点的相邻节点。采用Gabriel graph作为标准图,用于比较。
如何评判估算结果是否精确
为了评价在某种布局下,上述步骤估算出来的美学指标和这幅图在这种布局下实际上的美学指标的吻合情况(也就是估算精度),需要计算一下输入图$G_{input}$在经过布局方法布局后,真实的美学指标。之后,可以用以下两种方法比较估算结果和实际测量结果的吻合程度:
均方根误差(Root-Mean-Square Error (RMSE)),结果越小越好
其中:
- $\cal Y = {y_1,…,y_n}$是经过实际布局后,测量出来的真实结果;
- $\tilde{\cal Y} = {\tilde{y_1},…,\tilde{y_n}}$是回归模型的估算结果。
测定系数(coefficient of determination (R ) ):结果越小越好
其中$y_\mu$是测量结果$y_i$的平均值
实验结果
估算精度方面
部分精度评估结果
上图展示了四个不同的 kernel(RW-LOG-LAPLACIAN, RW-LOG-RBF, RV-LIN-COS, DGK)在八种不同的布局方法($sfdp, FM^3, FR, KK, Spectral, HDE, Treemap, Gosper$)的四种不同美学指标($m_c, m_a, m_l, m_s$)的两种不同估算精度度量($RMES, R^2$)的结果。加粗部分是最佳结果。
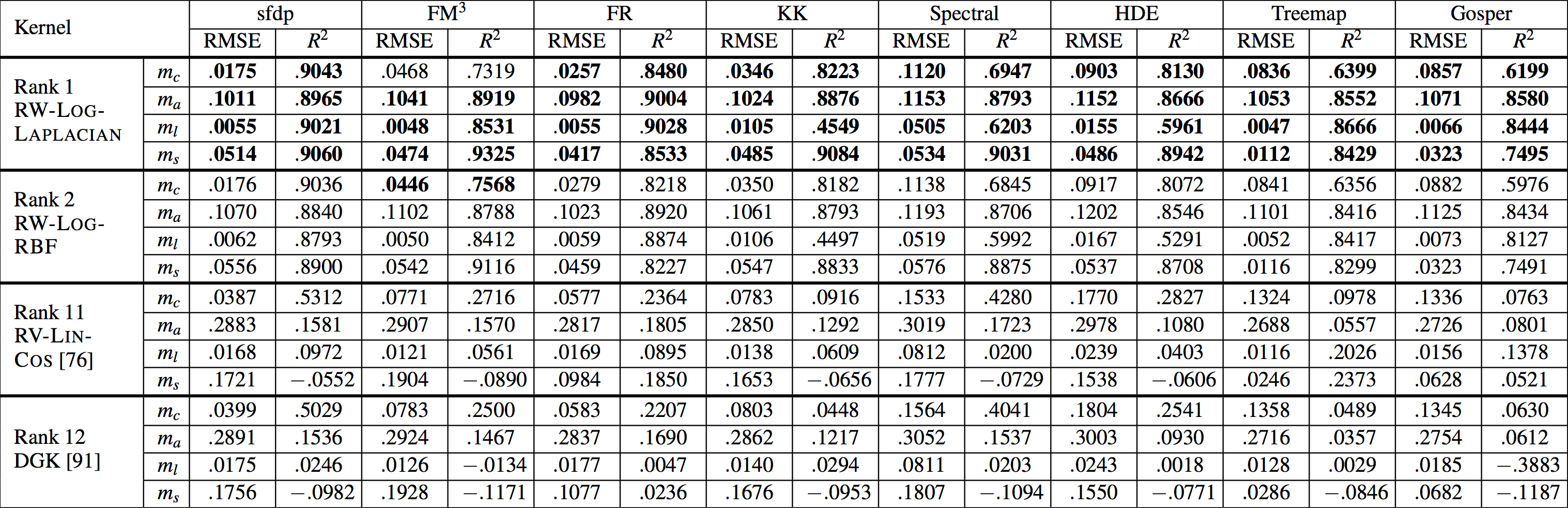
- 从上图可以看到,除了在$FM^3$布局下的$m_c$指标以外,RW-LOG-LAPLACIAN kernel 的表现都是最佳。而 RW-LOG-RBF kernel 则在$FM^3$布局下的$m_c$指标表现最佳。DGK 排名为第十二名,说明框架产生的 kernel 大部分都优于这个对照组,也就回答了第三个问题。
- 总体而言,RW 采样方法得到的结果精确度要高于 RV 采样方法,LOG 变换比 LIN 变化的精度更高,用 LAPLACIAN 的核也比其他两者精度更高。
计算时间方面
因为有一些算法是并行计算的,而有一些不是。故而,这里只汇报了 CPU 时间。Estimation time 只考虑预测图的美学指标中提到的计算时间(不考虑训练模型的时间)。
结果显示,精度最高的核 RW-LOG-LAPLACIAN kernel 也跑的最快,平均每幅图 0.14093 秒(标准差为 1.9559)的时间进行估算。
时间开销最大的是在采样图元的时候。
- RW 采样计算速度最快,每幅图平均 0.14089 秒 (标准差为 1.9559)。
- DGK 的图元采样速度比 RW 要慢,每幅图平均 3.38 秒(标准差为 7.88)。
- RV 采样计算速度最慢,每幅图平均 6.81 秒(标准差为 7.04)。
计算时间和图规模之间的关系
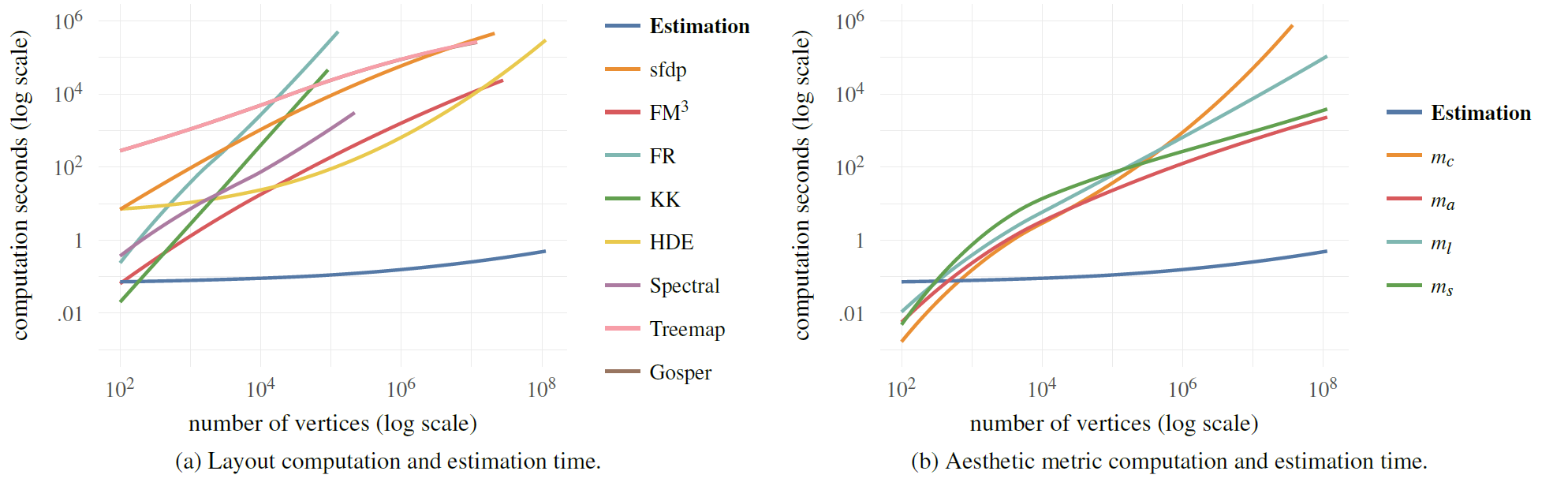
下图显示了拥有最高精度的 RW-LOG-LAPLACIAN kernel,实际计算和估算八种布局结果以及四种美学指标的时间。左图展示了八种布局的平均实际布局时间以及估算时间(y)和图节点数量(x)之间的关系,右图则展现了不同美学指标的平均计算时间以及估算时间(y)与图节点数量(x)之间的关系。随着图的规模变大,实际布局计算时间以及美学指标的计算时间和估算时间之间也就拉开了距离。
讨论
- RW 采样方法比 RV 采样方法精度高,因为 RW 只采样连通图元,故而我们推测,连通图元对展现图的结构信息更重要,故而估算结果的精度也更高。
- 事实上,在用 RV 采样的过程中,每个图采样 10000 个图元,发现只有 1.913%是连通图元,而有 35.77%的图没有采样到连通图元,即便它们这些图本身都是连通的,这就使得这些图本身就很难用于比较。
- 使用 LOG 变换的核,比使用 LIN 变换的核,平均而言有着更高的估算精度,可能是因为图元的分布也经常呈现出幂率分布。
- 因为在估算过程中,不用再计算实际的布局结果,所以估算布局结果和美学指标的速度会很快。
- 发现除了 DGK 以外,其他核矩阵的计算时间都很短,而且相差不大,平均 5.99 秒,标准差 3.26。而 DGK 因为要计算语言模型 language modeling,需要平均 182.96 秒。
预测图的布局结果
评估目的
此次评估是为了验证文章提到的WGL 方法评价出来的图和图的相似情况是否和人类心理上认为的相似情况接近。
实验设计
此次试验是一个排序实验,是为了比较WGL 方法得到的训练数据中的图和目标图的拓扑相似度的排序结果($r_T$)和人类主观评价出来的相似度排序结果($r_P$)是否匹配。
任务
如图:用户调研中的其中一个任务示例所示,参与者都会面对一个目标图(Target)和九个选项(Choices),他们需要从这些选项中,挑选出和目标最像的三个图,并按照相似度进行排序。
为了避免偏见,实验并没有定义什么叫做“相似”,并且也没有告诉用户,这些图都是用同一种布局方法进行布局的。
实验采用了九个图数据,八种布局方法进行组合,一共是 72 个任务。
用户调研中的其中一个任务示例
每个任务中,参与者都会面对一个目标图(Target)和九个选项(Choices),他们需要从这些选项中,挑选出和目标最像的三个图,并按照相似度进行排序。a, b, c 三个图的中心节点被展示在右边。

图的选取
- 目标图(Target):一共选取了 9 个目标图,选择过程如下:
- 将已有的 8000+图,利用谱聚类(spectral clustering)的方法分成 9 类
- 对于每一类,选出相互之间拓扑相似度最高的十个图,作为这一类的代表图
- 从这十个代表图中随机挑选一个作为目标图(Target)
- 选项图(Choice):每幅目标图,都要挑选九幅选项图:
- 利用每幅图和目标图之间的相似度,利用Jenks natuarak breaks 方法(一种一维的 K 均值分类方法)将所有图分成 9 类
- 从与目标图最相似的聚类中,选出和目标图相似度最高的图,作为其中一张选项图
- 剩余八类中,每一类都选出相互之间拓扑相似度最高的十个图,再从这十张图中随机挑选一张,作为剩余八张选项图
- 当然在挑选过程中,需要过滤掉那些节点数大于目标图两倍,或者小于目标图一半的图
实验结果
用户调研的总结
蓝色表示用户挑选其作为最相似图的比率,绿色表示用户挑选其作为第二相似图的比率,浅绿色表示用户挑选其作为第三相似图的概率。
左图(a)显示了用户主观的相似图判断和算法结果的匹配程度
中图(b)显示了,在不同布局下,算法选出的最相似图($r_T = 1$)和用户的选择的匹配程度
右图(c)显示了,对于不同的目标图,算法选出的最相似图($r_T = 1$)和用户的选择的匹配程度

- 如图:用户调研的总结,发现有 80.46%的情况,参与者认为最相似的选项图($r_P=1$)和系统选出来的最相似的图($r_T=1$)刚好吻合(图 a 最左边的蓝色长条);90.27%的情况下,参与者认为的最相似($r_P=1$)和第二相似($r_P=2$)的选项图和系统选出的最相似图($r_T=1$)吻合;而 93.8%的情况下,参与者选出的第 1、2、3 相似的图($r_P={1,2,3}$)和系统选出的最相似图($r_T=1$)吻合。
- 除了 treemap 布局和 spectral 布局以外,有 78.52%~93.33%的情况下,参与者选出来的最相似图和算法得到的最相似图一致,有 94.44%~99.26%的情况下,参与者选出来的最相似的三幅图和算法得到的最相似图吻合。
- 目标图中,除了$G{2331}$和$G{3833}$,有 79.58%~98.33%的情况下,参与者选出来的最相似图和算法得到的最相似图一致,有 92.08%~99.99%的情况下,参与者选出来的最相似的三幅图和算法得到的最相似图吻合。
讨论
- 为什么 Spectral 和 Treemap 布局比其他的布局方法结果要差?
- spectral:参与者根据线的形状、节点的个数来判断相似程度,我们发现,谱布局,经常会有很多节点重叠,故而会让参与者判断不准
- treemap:因为它的几何限制,经常产生相似的图形,参与者几乎都提到,“这些图怎么长的都一样?”,他们经常会根据边的密度,整体边的走向来判断相似程度,故而判断不准
- 为什么 G2331 情况比较糟糕?图 5所示情况,参与者在 b 和 c 图中徘徊不定:
- 参与者选择 c 的原因:密度、形状、边的数量
- 参与者选择 b 的原因:中心节点的数量
- 系统选择 c 的原因:大体上结构和目标相似
五、讨论
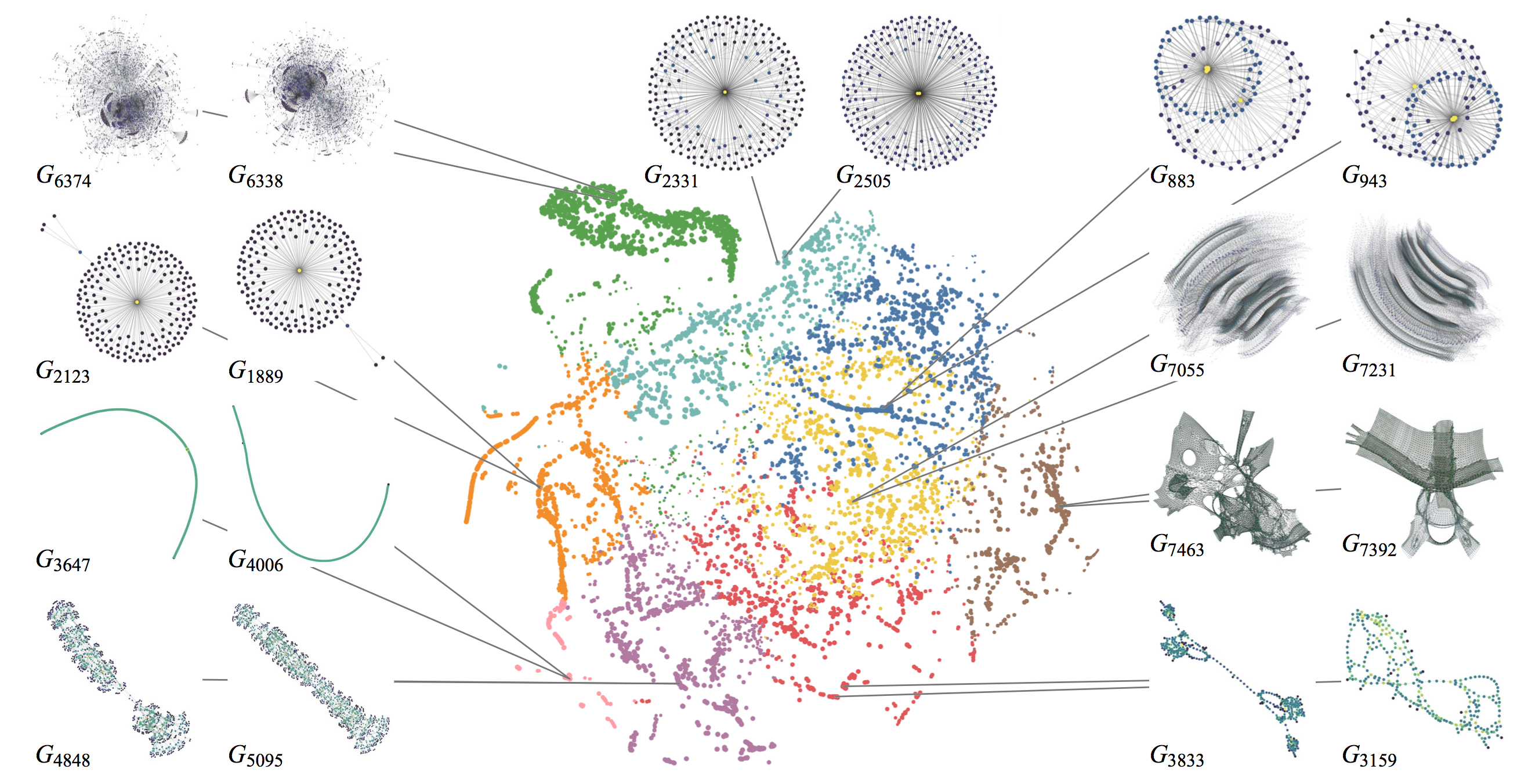
上图是 8263 幅图用 RW-LOG-LAPLACIAN kernel 计算得到的相似度的一个投影,这一对对的图是 9 对拓扑结构最相似但却非同构的图。
这篇论文,为我们进行大图可视化提供了一个新的思路,为了应对大图中高的计算代价,可以通过机器学习的方法,用预计算的代价来代替实时计算。这样就甚至能把大图的某些计算效率提高到实时的级别。
✉️ panjiacheng@zju.edu.cn