论文: NameClarifier: A Visual Analytics System for Author Name Disambiguation
作者: Qiaomu Shen, Tongshuang Wu, Haiyan Yang, Yanhong Wu, Huamin Qu, and Weiwei Cui
发表会议/期刊: VAST2016 / TVCG
一、概述
目的: 不同文献中的作者重名问题
动机:
现有的纯挖掘算法往往采用全局模型, 无法处理一些特殊情况 (比如, 同一篇文章重名; 重名者研究领域高度相似; 重名者研究领域随时间发生变化等等)
现有可视化方法很少
贡献:
用可视化方法将原本黑盒解法变成一个白盒的过程
提供一种引导用户进行分类的方法而不是简单的给出分类结果
提出一种两步去重的过程, 迭代的改良分类结果
二、系统流程
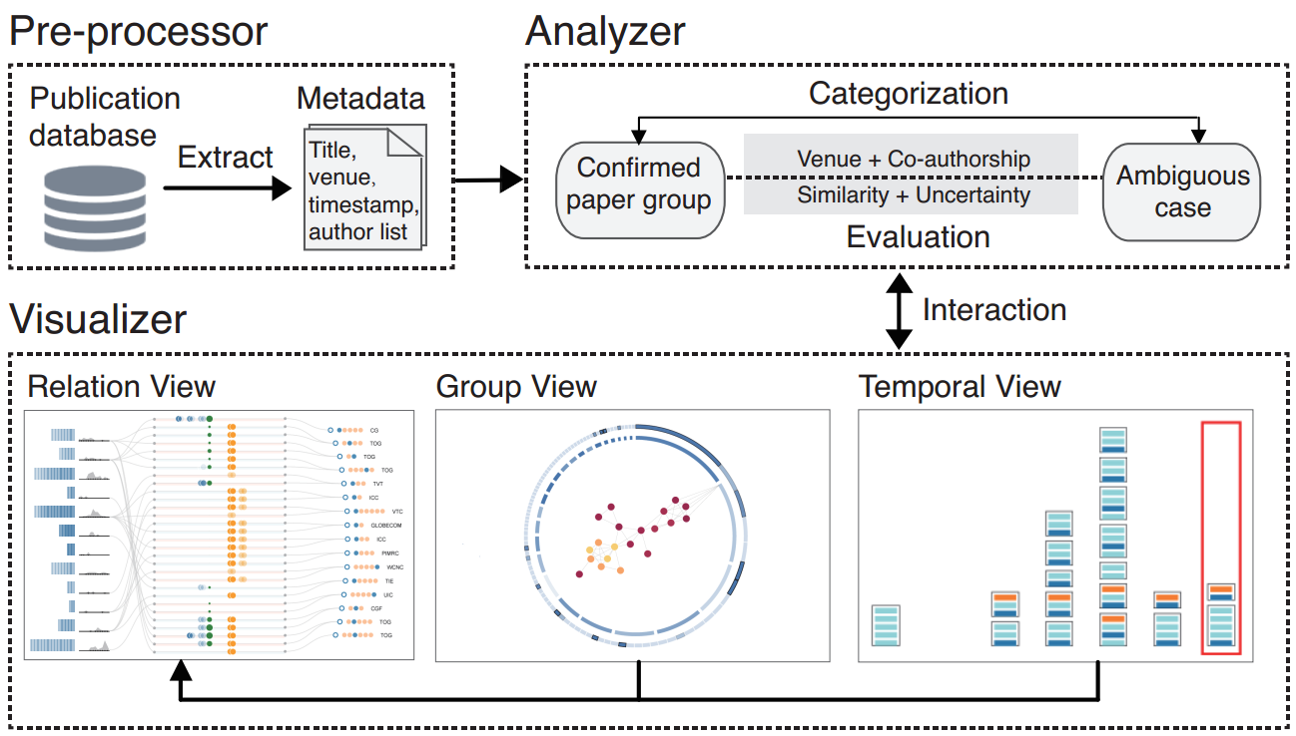
给定一个名字, 输入到这里的是所有这个名字的文献的资料 Pre-processor: 对每个 publication 抽取 metadata 给 Analyzer 然后 Analyzer 首先将所有有明确身份的文章分组(person1, person2 等等以及各自对应的文章的集合), 将剩下的标为歧义的文章. 然后将确定的组与歧义的文章比较估计相似性, 利用的是不同时间所发表刊物的一些属性和共同作者的一些数学关系最后 Visualizer 展现这些关系, 一共有三个 view 第一个 view 主要是分类那些有着歧义名的文章来到现有的确定组中去, 后面两个 view 主要是来验证前面的初步结论.
三、数据处理
主要就是 Analyzer 所做的工作, 分为两部分: (1) 依照歧义性进行分组, (2) 对相似性进行估计. 分组分成两块, 确定列表与歧义列表. 确定列表的列表每一个都是一群被数据库索引的人, 如 Wei Chen001, Wei Chen 002,…上面每个人都有一批的文章, 这样的一个人 A_G 和一批文章 P_G={p_1,p_2,…,p_n},章构成一个“确定组”G (一对多). 歧义列表则一篇不确定的文章对一个不确定的人. (一对一).
估计相似性又分成两大块, 分配可能性与信度, 从共同作者与发表刊物两个角度来计算.
四、可视设计
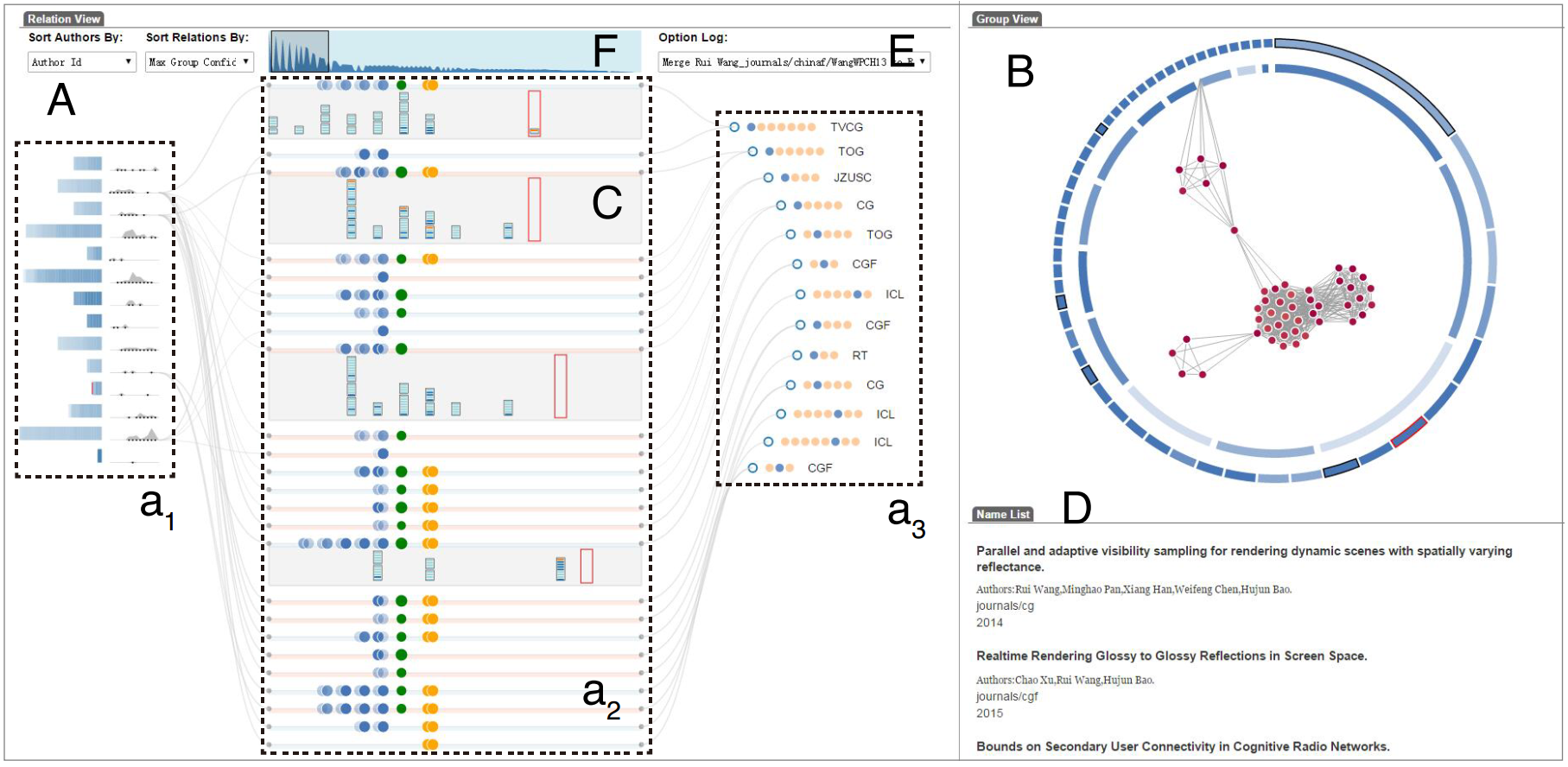
系统分为三部分, Relation View, Temporal View 和 Group View. Temporal View 是嵌入在 Relation View 中的.
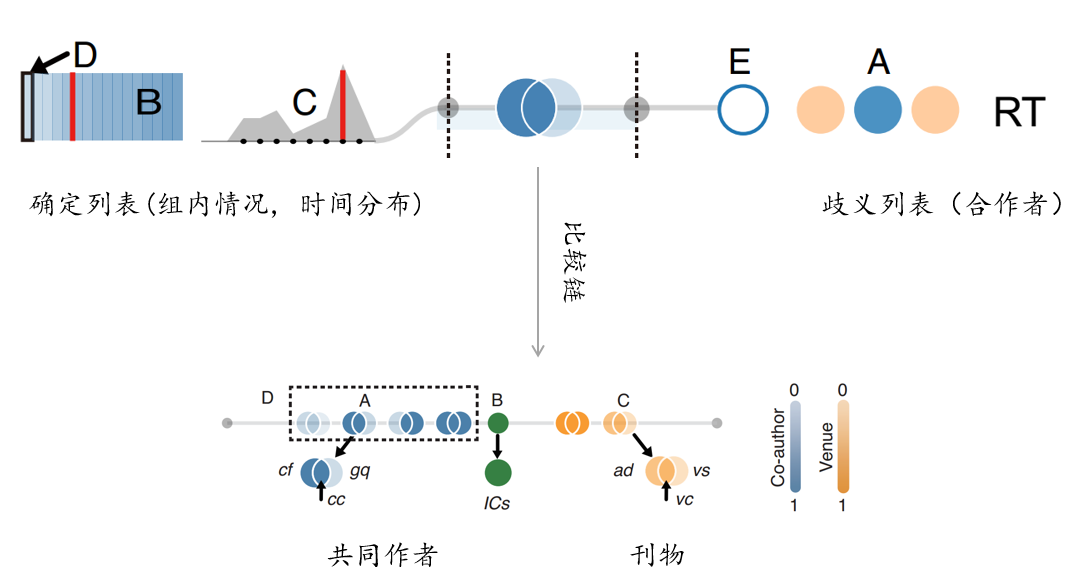
Relation View 是确定作者和歧义作者之间的关系的一个展示, 由细分为三部分, 左边是确定作者的信息, 右边是歧义作者信息, 中间是比较链. 具体说明如下图.
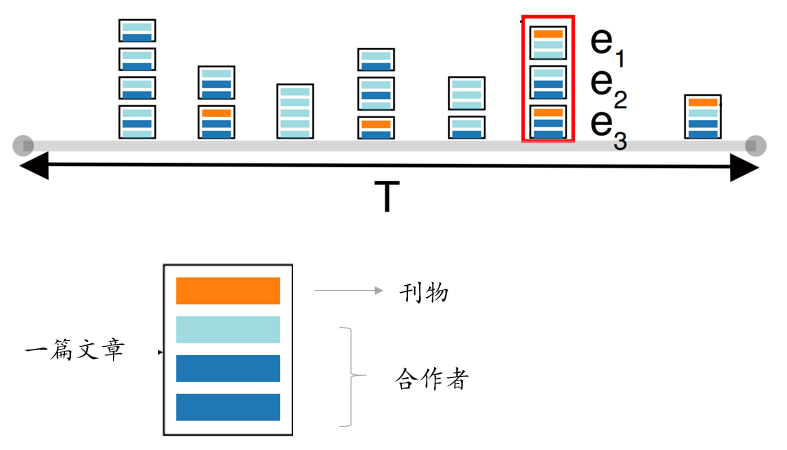
Temporal View 的设计初衷, 是因为一个作者的兴趣会变, 有时候只能做为歧义组一段时间内的一个指标. 这个视图帮助确定组的文章的时序情况, 展现和歧义文章的关系. 第一条橙色说明和歧义文章同一个刊物; 如果有合作者也在歧义文章中那么用蓝色标出, 其余用青色表明存在. 红框表示的是歧义文章发表的那一年.
Group View 能帮助用户对一些已经确认的姓名进行查错, 评估已经分类的作者分类情况的准确性. 所有输入划分成确定子集与歧义子集. 确定子集每一个代表一个确定的作者, 歧义子集每个包含了一些文章他们可能属于同一个作者(这个初始划分是根据合作者相似性只在子集内有出现划分的). 选中一 arc 出现合作图 (力引导布局), 每个 node 一篇文章, 若有共同作者就连线 node 的颜色代表时间先后顺序.
考虑到歧义子集中的文章可能属于一个确定作者, 如果他们有共同合作者的话, 我们将他们联系起来(将这些子集用黑色框高亮起来). 此外, 当展示歧义子集的合作图时, 如果歧义 node 和一个确定子集有共同合作者, 这个确定集所对应的 arc 会发出一条边和吸引力将歧义 node 吸引来.
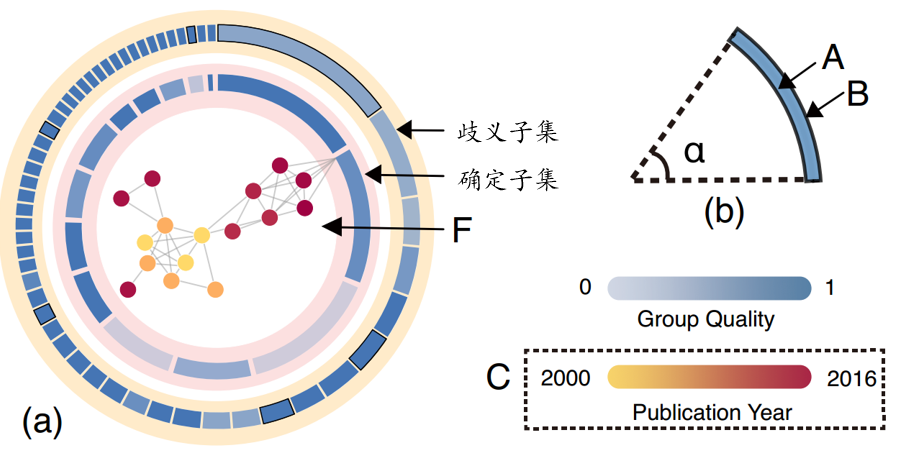
此外, 系统还提供了丰富并且实用的用户交互, 比如视图关联, 迭代消歧, 回溯, 查询等等.
五、案例分析
文章提供了两个非常详尽的案例, 对系统每个组件、每个交互的实用性进行了详尽的展示. 这里简单介绍一个例子, 用的是 DLP 中 Rui Wang003 和 Rui Wang004 的数据. 数据特点在于这两位学者的 (1)同样的合作领域: 图形学可视化 (2)相似合作者 (3)彼此间有合作论文. 数据以供 560 篇文章 179 确定 381 不确定.
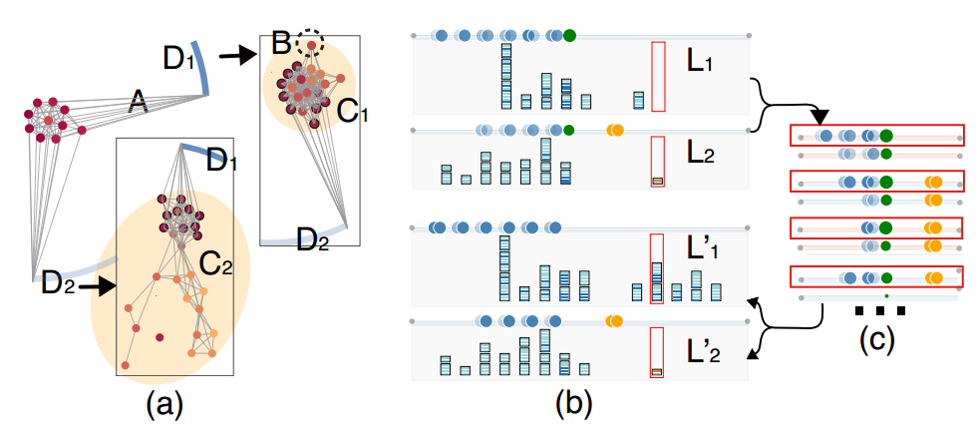
我们发现一篇文章和某两确定文章的的比较链 L1 L2 难以区别出谁会更明显的类似 (前者更多共同合作者, 后者更多类似的刊物). 将这些文章放到 group view 中发现他们同属于一个不确定 arc 有一个高密度的合作图 A. 这个图与 D1 D2 两个确定作者有着关联.
如果把 D1 与 A 合并可以得到一个更紧凑的图 C1 而把 D2 与 A 合并得到 C2 却很松散. 所以我们推测 A 中文章都属于 D1 .我们从灰色框右上角离 D2 最远的 B 开始看 一个个将这些文章分类, 经过一轮轮的分类以后 L1 L2-> L1’ L2’. 这时候 L1‘特征很明显了.
六、讨论
系统十分依赖人的主观判断, 可以在未来工作中结合一些现有的好的挖掘算法进一步提高效率. 人如果一多, 可扩展性也得需要考虑. 可以增加一些交互来改善. 还可以用一些虚构数据集合来验证系统有效性.
七、思考
这个系统设计美观, 针对的问题非常实际. 各种设计 glyph 编码了大量信息, 这个技能非常值得我学习. 尽管大量编码可能让人一下子难以上手, 但是如果是领域专家在充分理解之后用起来应会很省事.
文章行文流畅, 结构清楚, 逻辑上非常通畅. 尽管编码复杂, 描述时候仍然很有条理.
✉️ akiori@zju.edu.cn