论文:UnTangle Map: Visual Analysis of Probabilistic Multi-Label Data
作者:Nan Cao, Yu-Ru Lin, and David Go
发表:TVCG 2015
研究对象:概率多标签数据
一、创新点
- 精确可控的标签节点布局算法
- 提高可拓展性的聚类渲染技术
- 易于理解的评估
二、可视设计
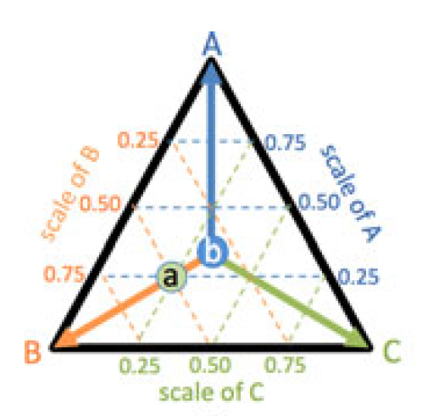
1、三元图:三个顶点为三个标签,将每个数据项对应的三个属性值的和归一后投影到三元图上,其总值的大小用点的透明度编码。
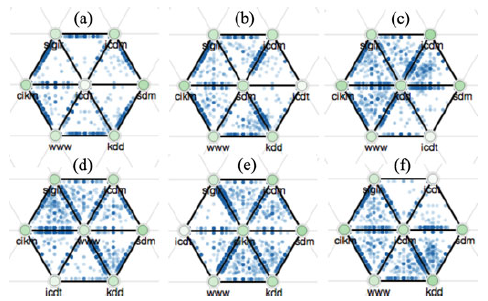
2、三元图网格:很多个三元图组合到一起就形成了三元图网格,在形成的过程中会出现一些公共点和公共边,它们对用户观察 pattern 有很大的影响作用(可以看到下图中不同节点位于中心的 pattern 是不一样的),所以网格上的节点位置排布十分重要。系统一方面提供优化算法可以自动生成网格,另一方面用户可以用交互对位置进行调整。此外,这里通过节点的颜色来编码标签的主导程度。
三、交互
更换相关度测量方法
从数据集中刷选要观察的标签
增减标签
移动标签位置
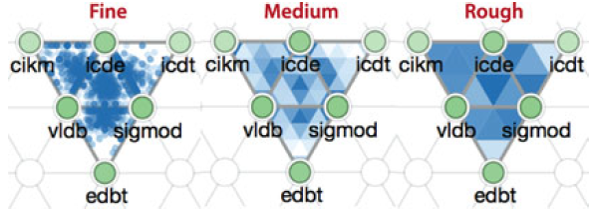
调整呈现的精确度(贡献之一,效果见下图)
四、算法
1、优化目标:相邻的标签相关度尽可能高,数值表达如下:
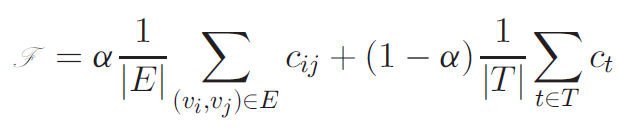
α 为调节系数,左边部分考滤所有边的平均相关度,右边部分以三元图为单位考虑所有三元图中全部边的平均相关度(公共边重复计算)。
2、搜索空间:新增标签可放置位置数*剩余标签数
五、评估
1、比较不同布局算法的实现:变种爬山法优于贪婪算法。
2、评估方法的可拓展性:其计算性能是线性递增的,但是在 medium 和 rough 层级下的呈现性能几乎不随数据量增减而增加。
3、比较该方法和其它可视方法下一些任务的执行时间和准确度:该方法在前四个任务中都是最优的,但是第五个不如其他方法。

4、案例分析:
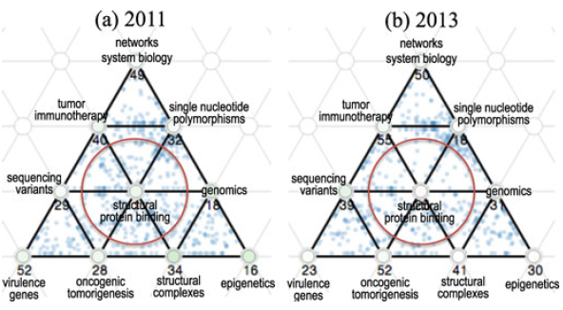
从第一张图中我们可以看出,红圈中的节点所代表的学科方向的热度在 2011-2013 年有所下降,学校都对这个方向有所疏远。在第二张图中,放大这部分可以观察到,在这些学校中,斯坦福大学的研究方向转变是走在很多大学前面的。
六、总结
1、不足:
- 难以识别标签之间的线性关系
- 案例分析只涉及到了精确级别的设计
- 归一难以直接比较数值
2、优势:
- 文章全面且详细
- 设计感强
- 方法有效性得到证明
3、未来工作:
- 提高定位相关信息和比较的能力
- 更加全面的用户调研
- 和其他可视化方法(散点图,柱状图)结合以应用于更多类型的变量
✉️ wangxumeng@zju.edu.cn