论文: TelcoVis: Visual Exploration of Co-occurrence in Urban Human Mobility Based on Telco Data
作者: Wu, W., Xu, J., Zeng, H., Zheng, Y., Qu, H., Ni, B., … & Ni, L. M.
发表期刊: TVCG2015
本文是 2015 年 VIS 中 SciVis 的文章,并被 TVCG 收录
简介
本文利用广州的的电信数据(telco data)对人口流动(human mobility)中的共现现象 (co-occurrence)进行可视分析. 所谓共现, 简单的理解为来自区域 A 和区域 B 的人在同一时间段内到了同一个地方. 这种现象的分析研究有很多实际应用, 例如
帮助城市规划者应对流行病, 帮助社会科学家洞察和建模人的社交 (比如富人与穷人之间的交流)
帮助商店店主了解在特定时间段造访餐厅, 商场的人的类型, 以便进行有针对性的促销, 做出更好的商业决策
帮助管理者估计高峰期在地铁口, 高速公路入口共现的人的数目
随着(智能)手机越来越普及, 收集到的电信数据也更加细粒度, 数据量也愈发庞大. 这些数据使得我们能够进行更好的对人类行为的分析, 比如上面提及的共现现象.
 .
.
数据, 任务及建模
广州某电信运营商提供的电信数据, 只要用户手机和基站有数据交换(电话, 短信以及联网)就会留下记录. 数据 (大小 33GB) 覆盖广州城区, 时间为 2013 年 10 月 21 日一整天的数据, 860 万用户, 24789 个基站(这些基站用 Voronoi 细分成了 9472 个区域).
通过与社会媒体学专家及电信工程师的交流, 列举了一些分析的任务: (1)全局探索: 对不同区域的共现现象中模式的总览图, 比如不同地区共现的分布. (2)洞察探索: 当我们得到了一些模式后, 分析师试图建立初步的假设, 来分析这些原因. 这里需要展示一些人类移动的时空特征. (3)关联性探索: 关联性分析的重要任务是 bicluster 的抽取以及展示 (这里的 bicluster 算法可以参考 “Biclustering of high-throughput gene expression data with BiclusterMiner” ). 它同样需要总览图和细节图. (4)细节探索: 各种细节的展示.
每条数据格式为(ID_phone 机主 id, time 时间, ID_base 基站 id, 经纬度). 对这 24 小时的数据, 每隔 5 分钟为一个时间段, 这样一共有 24*60/5=288 个时间段. 每段中, 这个人的连接时间最长的那个基站作为 location, 若无则记为 unknown. 这样每个人就对应一个 288 维的向量. 覆盖时间小于 8 小时的人被过滤掉, 这样能过滤掉 15%的人.
共现数据抽取: 如果从区域 A 和区域 B 来的人在同一时间段造访区域 C, 则称”区域 A 和区域 B 在区域 C 共现”. 根据定义我们可以把所有共现构建成一个图 G=(V, E). 首先构建一系列子图, 每个时间段一个子图; 每两个点之间若有过共现, 则有一条边连接, 该边有一个权向量(ω_A, ω_B)代表来自两个点的发生共现事件的人. 子图再进一步聚合成为一个完整的图.
挖掘共现的关联性: 首先将上面的每个时间段 k 的子图转换为一个二元(01)矩阵. 记 P={p1,p2,…,pn}是共现发生的地方, R={r1,r2,…,rm}. 这样形成了二元矩阵B^k (k=1,2,…,288), 每一行对应一个地点 pi, 每一列对应一个 rj, 如果 rj 与其他某个区域在 pi 于时间 k 有过共现事件, 则元素B^k(i,j)为 1; 否则为 0. 注意这里至少要包含 2 个区域和 1 个地点, 这样做的目的是为了保证挖掘出来的关联性更有意义.
系统设计
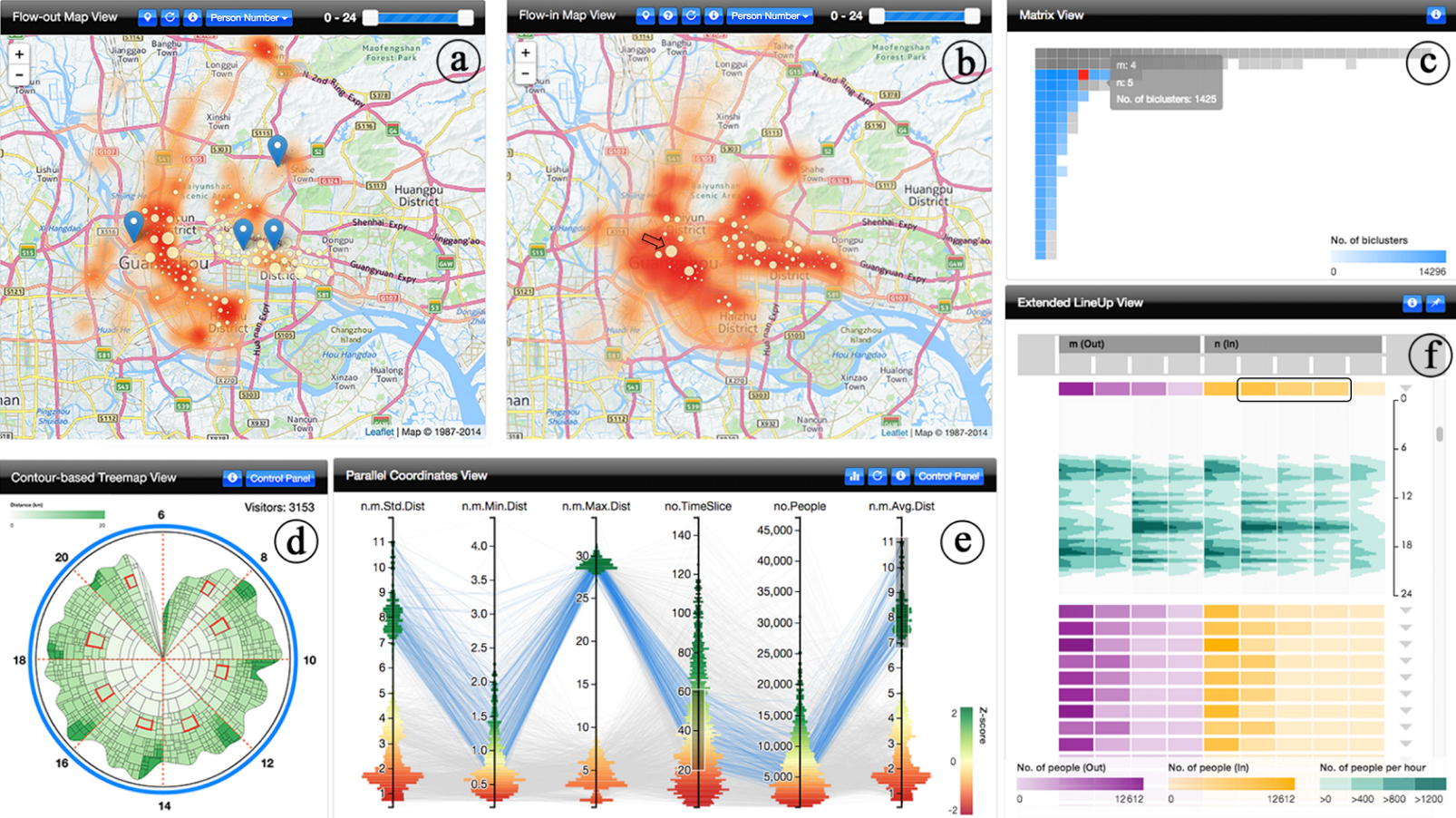
系统由两个互相有联系的部分组成, 一个是基于区域的共现分析, 一个是基于关联性的共现分析. 前者包括 Map View(a,b), Contour-based Treemap View(d); 后者包括 Matrix View(c), Parallel Coordinates View(e)和 EXtended LineUp View(f).
Map View 包含 flow-out, flow-in 两部分, 用于展现共现的总体分布情况. 前者展现流出区域共现时间分布情况, 计算每个区域和其他区域共现的次数, 以热力图形式展现, 颜色越深次数越高; 后者展示流入地点的共现事件分布情况. 如果选取几个点, 两个图会联动展示一些黄色的点, 代表他们共现的地点, 点直径代表人数大小. 用户还可以调节选中的时间区域.
Contour Treemap View 展现出一个选定地点的属性: 不同时间段来到这个地点的人, 这个地点和共现的区域之间的距离, 这些区域人的忠诚度(访问该地点的频率). 每个这样的图中, 外面的轮廓(contour)到圆心的距离, 顺时针方向反应了 288 个时段依次人数的多少. 如图, 一共分成了八个扇形也即八个时段, 每个在本地点有过共现的区域在这里也重复出现了八次. 里面环形的 treemap 布局, 用颜色代表该区域到本地点距离的远近, 大小表示人数的多少, 到这个扇形起始点角度 θ 表示忠诚度, 到圆心距离 r 为人数多少. 我们发现这出现了两次, 其实是因为这个布局算法导致了 r, θ 的偏移.
Matrix View 展现的是共现关联性的概览图. 这是一个(m,n)矩阵, m 是区域个数, n 是地点个数. 每个矩阵元素颜色深浅代表这个规模的 bicluster 的个数.
Parallel Coordinate View 是对一系列的 bicluster 属性的展现, 每条 polyline 代表一个 biclutser. 提供了 z-score histogram 这样一种统计信息的图来减少视觉上的混乱.
Extended LineUp View 是对每个 biclutser 具体区域, 地点及时间分布的更细致展现. 每一横条马赛克代表了, 紫色代表流出的区域, 黄色代表流入的地点, 颜色深浅代表人数的多少. 点击一条马赛克还可以展开一个时间分布图,表示每个时间段人数的大小, 其设计思路借用了 horizon graph.
文章后面介绍了几个案例, 分别展现了利用这个系统来探索不同区域的共现分布情况, 学校附近的共现, 高收入低收入活动路径分布, 不同功能区(生活 娱乐 交通 办公)的等等, 得到了一些有用的 insights, 并且在实际地图得以验证. 专家评估也认为很有价值.
文章还说了一些自己的缺点:缺少一些更优质的数据挖掘方法: 如根据人的行为模式判断工作或生活区; 某些视图用颜色深浅来编码, 而人的感知能力有限; 若要更好的利用平行坐标, 还需要更好的相关性度量, 轴排序算法; 数据量大时候的可扩展性: 暂时的系统只能一天; 若 regions 更多的效率问题; 数据仍存在不全.
在我看来文章还是有很多优点: 首先行文流畅, 结构工整; 设计思路与我们实验室的城市数据相关的项目也略有不同, 值得借鉴; 此外, 他的这些发现如果能做的更细的话, 我认为确实能帮助城市管理者进行更好的规划, 尤其是文章前面提到的那三个应用.
✉️ akiori@zju.edu.cn