
在互联网时代,大数据炙手可热,许多人言必称大数据,但能够真正说清大数据为何物的人并不多,更遑论如何借助大数据挖掘出巨大的商业价值。究竟如何定义大数据?大数据有哪些特征?本文旨在厘清大数据概念,阐明大数据应用方式及探究未来大数据发展之道。
Q1:大数据是商业炒作吗?
业界给大数据的定义是4 个“V”:体量大(Volume)、种类多(Variety)、速度快(Velocity) 和真实性高(Veracity)。但这个定义其实并未抓住大数据本质。如果仅仅看这几个维度,大数据就是一种炒作,因为它们只是表面现象。
大数据的本质应该是如何为企业带来一种更新更好的商业运作模式,而大数据应用的成功,也是依靠决策者提出好的商业问题及与其相关的商业模式。这些商业问题可以非常简单,但问题背后必须有一系列相关的商业模式。
比如,如何运用智能手机应用商城的数据, 来提高对用户APP 推荐的精度? 随后,利用应用商城的大数据,可以产生上百万维的数据表,进而建立可靠准确的推荐模型,使得用户体验水平大幅提升。
大数据应用成功的关键也正取决于是否有一个明确的商业(或科学)目的,商业模式的定义是其前提条件。
Q2:数据越多越有用?
首先,如果收集大数据的目的是建立一个对位置数据的预测模型,那么,得到这一模型的训练数据一定要包含所需的信息。但问题恰恰是,事前并不知道哪些特征是重要的,因此,需要把尽量多的数据整合起来,让机器去寻找。
然而,这个问题为什么不能去咨询该领域内的专家们呢?事实证明,专家们虽然会自己解决问题,但大都说不清他们是如何解决这些问题的。这也就是为什么在大数据应用中,专家的作用更多体现在帮助连接、聚合尽量多的数据上。
除此之外,要建立一个好的预测模型, 用来训练模型的数据总量也要足够多。如果历史数据少于一定规模,就会出现所谓“过拟合”(为了得到一致假设而使假设变得过度复杂)现象。例如,如果一个服装品牌按照某一个模特的身材来设计,衣服很可能做得偏瘦,以至于绝大多数其他消费者无法使用。这种“过拟合”现象在建立大数据下的预测模型时也会发生。
那么,数据的总量越大,是不是预测模型需要学习的时间就一定越长呢?答案是否定的。研究成果表明,在一定条件下, 当数据变得越大,实际所需要的训练时间反而越短。为什么会这样呢?可以想象:如果一个学生在学习某种概念时,只有少数习题,那么这个学生想透彻学会这个概念,就需要把每一个习题翻来覆去地看, 加以扩展,这样学习的过程会比较慢。相反,如果他有许多不同类的习题,只需要把每一个习题过一遍,即可应付未来的大部分情况。因此,习题多的学生,学到同样水平的时间反而会短。
Q3:人工智能将超过人类大脑?
经过几十年的探索,可以相信:机器的智能只能从针对大数据的学习中得来,而大数据只能从人与人的交互、人与机器的交互中得来。如果想要这些交互产生足够多的数据,就一定要让这些交互为人类提供有用的服务。
如今,什么数据最为充分?充分的数据首先是最容易被记录的那一部分,比如语音、图像、文字等。能不能直接获取人类大脑活动信息,并以此来充实我们的智能呢?当今的这种技术(如磁共振脑图成像技术) 还不够精确,因此,通过学习得到的系统虽然在单方面可以超过人类大脑(如IBMWatson),但就通用性而言,现阶段的人工智能比起人类大脑还差得很远!
有没有可能在不久之后的某天,具有人工智能的机器人成为人类的敌人呢?这是有可能的。但前提是:这些机器人的领袖一定是人类。
Q4:用户隐私问题如何解决?
隐私问题的出现其实比大数据要早, 但隐私真正成为家喻户晓的议题,却是在大数据成为热点之后。从斯诺登揭秘到苹果数据上传,随着越来越多媒体的爆料,大家对隐私的关心程度也与日俱增。隐私问题的最大矛盾在于,一方面,数据被严严实实地包起来,另一方面,它又要被运用来发现有用的东西,不得不将之开放和上传。
目前看来,数据隐私问题有三个考虑: 1. 技术;2. 用户利益;3. 社会接受程度。
从技术上来说,以前有关数据的解决方式大都是把数据从终端迁移到计算端(如计算中心),得出结果后再把结果送到终端。这种方式无疑会引发隐私问题,因为一旦数据离开用户的个人终端,就无从保证谁将有权利接触数据,数据的隐私也就无从保护了。
要保护隐私,一种新的模式是“计算随着数据走”,也就是利用终端自身的强大计算功能,在终端算好一个结果(如一个预测模型,即本地模型),再把这个模型与某一个通用模型加以整合。这种模式无疑会引入更多计算量与复杂性,目前还属于前沿研究领域。这种方法就像是有人要买股票,但又不想别人知道他自己的需求,只读取网上有关股票的信息,与自己知道的需求结合起来,做出买卖决策。只要每个人足够聪明,又有足够的计算能力,这样的系统就会最大程度地保护每个人的隐私。
另一种做法是,仍把数据传输到计算中心,但在传输之前,将数据加以改变, 使其中的关键隐私信息在传输和计算中被隐藏起来,让人无法反推原始的敏感数据(如用户性别、住址等),同时又保证计算结果的真实性和可用性。实际上,一个更难的问题是:无论如何隐藏和加密原始数据,用户心里总有不放心的一点阴影。由于这个阴影的存在,用户永远不会相信一个单纯靠技术的隐私保护计划。可以预见,在未来,隐私问题的解决程度将成为用户选取产品的重要依据。
可是,大数据已经来到人们身边。今天社会上的每个人,实际上都是大数据的使用者。同时,又在不断暴露自己的隐私。比如,用户使用免费的电子邮件账户,即便知道这些服务商在挖掘我们的邮件信息;用户使用搜索引擎询问各种问题,尽管这令我们的问题被记录在案。既然如此,为何用户在使用大数据服务的时候,依旧乐此不疲呢?答案在于用户利益与隐私暴露的费用比:如果用户得到的利益大于个人数据泄露的价值,用户还是会同意接受并分享这些数据的。因此,隐私问题的关键是,如何让系统和用户在矛盾中寻找到一个平衡点。
最后,随着技术的发展,社会对于数据分享的接受程度也会改变。上一代人所不能接受的事物,到下一代可能就不是大问题了。Facebook 就是个例子: 实名制允许人们访问他人的主页,并看到许多信息,这一点在最开始引起不小的质疑,但最后,广大青少年热烈地拥抱这一新技术,并纷纷加入其中。
Q5:运营商管道vs 互联网用户大数据?
互联网与电信运营商的关系,可以用一个例子来理解:马路上形形色色的车辆可以视为互联网,车上所装的货物、乘客及运输系统可以视为互联网的数据和各种应用,而车辆所走的高速公路类似于运营商提供的管道。对于互联网而言,它更关心乘客和货物,关心如何把他们安全送到目的地。但从运营商角度而言,它更关心的是道路是否通畅。从这一点来说,互联网的数据有关乘客和货物,运营商的数据是车流量、道路拥塞的程度。所以,互联网的数据是终端用户数据,运营商的数据是关于数据的数据。
什么是关于数据的数据呢?以照片为例,像素点就是数据,而照片大小、类型、照片文件的产生时间与地点,就是数据的数据。
数据的数据在电信行业意义重大。但其前提是:资源无论到何时都是有限的。管道再宽,也是有限的。那么,从运营商的角度来说,他们希望知道什么呢?还是以车和路来比喻:
- 你想知道如何为一些重要的常客开辟一条快速通道吗?那就首先要知道哪些是重要的常客。只有知道了常客的群体,常客的特征,才能有效抓取到他们。
- 你想知道哪些重要车辆所属的公司在受竞争对手的高速公路公司吸引,正考虑换路吗?那就要分析这些车辆公司的痛点何在。
- 你想知道哪些路段需要特别维护,并派一些常驻维护车辆驻守吗?那就需要分析哪些是容易受损的路段。
这些对数据分析的需求随着运营技术的前进而提升。在5G 的场景下,运营商需要给大众提供更密集、更快、更个性化的电信服务,由此也就知道用户的使用规律、痛点、服务软肋在哪里。一个如影随形的高端服务并非由无数服务员在所有用户可能出现的地方等待,而是由一个聪明的服务员在用户需要的时候及时出现。未来的网络技术,如软件定义网络(SDN), 就更需要大数据的支持:SDN 的大脑可以根据网络大数据的深度挖掘所产生的修改,而变得越来越聪明。
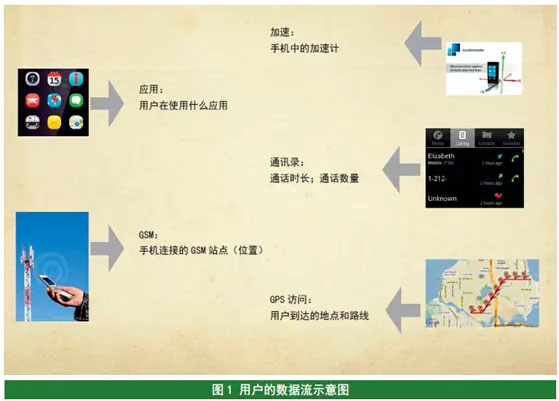
Q6:大数据和云计算、物联网是什么关系?
如果把整个IT 流程看做一棵树的话, 物联网就是这棵树的叶子和枝干。如果传感器网络所感知的信息是有关“人”的信息,比如用户在网上购买商品的信息,或与人的移动行为和动机相关的信息,那么它就会有极大的商业价值,对这种数据的需求也会剧增。人的心理因素是世上最复杂的,对应着某种动机和意识的行为、动作也千差万别。人与人的关系组成了无穷多的维度,而大数据正是这些维度叠加而成的。这些数据不仅包括人本身的语言、文字、动作、视觉数据,更是人与人之间关系的数据。凡是与人相关的活动数据,都是最值得收集的数据,与之相关的需求则永远存在。
所以说,关于人的数据才是大数据。物联网只有考虑到人这种广义的“物”,才最有价值。否则,物联网所传输的数据无论从复杂度还是商业目的而言,都极为有限。
大数据和云计算的关系则在于,大数据的成功应用除了“大”,还有三个必要条件:实时在线、对事件的全面描述以及产生差异化的效果。云计算使得这三个必要条件得以满足。
首先,云计算使人们可以随时随地使用存储和计算,使大量数据得以及时被采集和分析。手机上APP 应用云的服务就是一个云计算的例子。由于存储和计算成本的降低,云计算起到了实时在线的作用, 从而使得更多的人愿意使用云服务,大数据的雪球由此可以滚动起来。
云计算的另一个好处是可以实现大规模的数据整合。当今世界并不是为大数据应用准备的,因为大量数据集散落在不同地方,以不同方式存放,其拥有者也是不同的人。在云计算条件下,很多大规模数据整合的问题都会得到解决。当大家数据放在一起时,数据整合的门槛会大幅降低,因此,大数据也会像核物理的聚变一样, 产生成倍的效果。
Q7:有了大数据,我们还需要专家吗?
在大数据时代,专家的一部分作用确实可以被大数据应用所取代。例如,推荐金融产品时,专家需要将特定金融产品推荐给特定客户。这些客户有以下特点:接受这一推荐的可能性很高,同时,对其他客户的影响力也很强,在接受这一产品的同时,他们很有可能会把产品消息向亲朋好友传播。这一重要的市场工作过去是由专业的市场部门经理来完成的。然而在大数据应用中,通过对大数据的整合分析得出的大规模推荐模型的推荐效果,是市场部专家的二十倍以上。
这个例子说明:首先,在传统商业领域,大数据的功效确实能够取代并超越人的作用。在过去的实践中,市场专家最多能够判别十几维的数据,而数据挖掘模型却可以处理几万维甚至几千万维的数据;其次,取得这么好的效果需要做许多前期工作,如搭建数据平台、整合不同数据、建立分析预测模型,以及利用模型对未来数据进行分析决策。
这些研究人员具有三个突出特点:
一是非常强的驾驭数据管理系统和快速编程的能力,
二是和业务专家沟通并理解业务目标及约束能力、分析数据的能力,
三是与模型连接并预测到业务决策的能力。具有这些能力的人,我们称其为数据科学家。
所以,有了大数据之后,专家依然是需要的,只不过专家在决策过程中的作用与焦点改变了:专家已经不能独享成功,而一定要和大数据系统共同完成一项复杂的任务。大数据做了以往专家在数据分析领域的工作,但专家对于专业领域的价值和经验依旧无法取代。建立数据分析模型需要理解业务及业务目标,这仍需要专家的研究和贡献,毕竟外行还是不能领导内行。
Q8:大数据最适合做什么?
大数据的发展和其他任何技术的发展路径一样,都需要经过“初始化- 极端膨胀- 较大失望- 理性思考- 成功应用”这个逐渐成熟的过程。在历史上,听起来先进的技术在这个过程中却消失的例子比比皆是。那些成功的技术一定要经得起理性的思考和时间的考验,以找到它们在实践中最合适的落脚点。
目前,大数据有一个作用可能还没有被注意到——大数据可以连接大量不同的数据孤岛,使得大数据所覆盖的范围更大更广, 也使得大数据驱动的业务随着这个雪球越滚越大。这样,使用者可以不断得到新的数据, 而用户也能不断得到新的服务。
从现在大数据成功应用的领域来推断, 应用最多的应该是集中在对过去事件的存储、抽取,以及对不同数据的聚合联通、总结统计上。大数据聚合的重要作用之一是关联不同数据之间发生的个别事件。通过连通,实时发现事件真相。有了这样的数据就可以做以下分析:某个事件在发生的同时还会发生什么其他事件?如何通过过去数据来预测未来可能发生的事件?如何能够自动建议,用某种行为来促使某些事件发生,或保证某些事件不发生?等等。
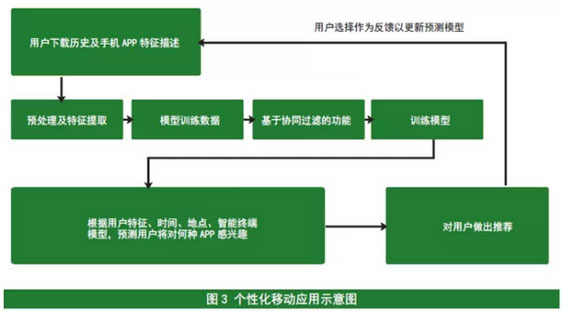
Q9:大数据不能做什么?
大数据明显不是万能的,那么,大数据不能做什么呢?
不能替代有效的商业模式。大数据的应用不能没有商业模式,比如如何在大数据业务中为用户带来价值,使得数据成长和商业增长同步等等。而商业模式显然不是能从大数据本身挖掘的,而是由具备丰富经验的专家来确定的。
不能没有领导的决断力。在今天的大部分公司中,数据的存在形式无异于一个个孤岛。把这些数据整合起来不仅是个技术活,还有很强的管理因素。往往在同一个公司的不同部门会有很多竞争,数据就是一个部门的资产。虽然把几种不同数据聚合在一起会很有价值,但能真正做到这一点的公司却会发现,要成功做到数据整合需要更高级领导的决断力。这也是为什么一些很有前瞻性的公司会专门有一个部门来负责全公司的数据业务。
不能无目的地挖掘。在大数据的初学者当中,有一个普遍的错觉:当我们有了足够的数据,就可以在其中漫无目的地找到知识。这样的错觉实际上是不科学的。数据挖掘需要约束与目标,否则就是大海捞针,必然是徒劳的。比如,开普勒的成功是建立在以太阳为焦点的椭圆形假设上的。
不能没有专家。上文提到,大数据在不同应用领域会需要不同的专业知识来指导。而不同的领域, 需要专家们的参与程度也会不同。G o o g l e 实验室有一个在大量图片和视频数据中, 让计算机自动识别猫脸的例子。但这样的深度学习很难推广到其他大数据的领域。因为,成功的先决条件之一是该领域本身具有非常直观的层次结构, 就像图片的构成一样。如果某个领域的数据不具备这样的层次结构, 就很难用同样的方法自动发现规律。而这样一个结构是需要数据科学家来定义的。
不能一次建模, 终生受益。一个好的模型需要不断更新, 需要终生学习(Lifelong Machine Learning) 来不断改进。例如,在奥巴马的竞选中,科学家建立了一个用户投票模型,来预测选民可能的立场,而这个模型是每周利用更新的数据来更新一次的。
不擅长做全局性的优化分析。大数据下的主要数据处理方法是“分而治之”,即把大的数据分为小块,一块一块地处理, 然后再把结果合并。这个过程也许要经过很多次,但总的思想是这样分化、合并之后的结果,与全局计算的结果是一样的。但是,还有很多问题是不能这样来解决的。比如,在下围棋的时候,每一个棋子的目的可能和整个战略都相关,所以分而治之的想法是行不通的。
不能没有对其语义的标注。目前只能通过对数据的标识赋予其意义。比如,推荐系统在没有用户反馈的情况下效果很差,而通过现有的心理学模型等加强其效果都无效。一般来说,如果试图从数据中发现知识,则需要大量的数据标注。往往在一个和用户有直接互动的应用中是可以得到这样的标识数据的。要得到大量的标识数据,不仅需要一个平台来承载有用的应用,而且需要一个对人、对大数据系统的双赢经济学模型。
不能仅用有偏的数据。数据一定要全面地反映未来, 对各个方面都有所涉及。如果数据是有偏的,则很难对未来进行有效地判断。
不能保证包含有效的信息。当数据中的关键特征缺失时,大数据就无法矫正数据与现实之间的偏差,尤其是对于那种与人的心理和行为相关的数据,非常容易产生偏差。问题的关键是:研究之前,专家并不知道哪些特征是关键特征。比如股价受到“黑天鹅”事件影响,使得无法用大数据预测关键事件发生的概率。这就像一个输入管道:垃圾输入导致垃圾输出。这也是为什么某些电影的实际票房和从网上评价数据得来的结果是背道而驰的。
不能保证减小噪音。这是因为在大数据里面,噪音数据的出现往往会以有意义的模式的形式出现,从而骗过知识挖掘系统。这样,大数据可能带来更大的噪音。
Q10:后大数据时代的技术趋势是什么?
大数据所带来的变革,只不过是计算机技术为整个人类带来变革当中的一步。计算机从上世纪五十年代起,就在人类历史上开始了潜移默化的革命。这个革命的根本标志就是人类社会和行为的数字化,以及两个世界(物理世界和虚拟世界)的无缝融合。在这场革命中,人类传统的行业一个接一个被数字化行业取代:从金融系统到电子商务,从机器人制造到无人驾驶汽车……
所以,大数据变革与人类历史上其他重要变革是一样的,需要经过资源( 即大数据) 的原始积累,商业和社会服务的差异化,直到人类对虚拟世界的行业、社会进行再规范,以解决数据资源分配。这个历史过程在上一个工业革命(十八世纪机器革命)时经过了一百多年,但在这一次的革命中,将以更快的形式发生。
以此推论,由大数据引发的下一代技术很可能是更大规模的、面向数字化行业的转变, 这使得现在物理世界里的众多传统行业将全面或部分地转向数字世界,进行融合。这个转变也让许多领域以另一种形式出现, 使得许多行业在整体“食物链条”上下游有所改变。到了那一天,医生、科学家和教师等“高大上”行业是否会成为大数据输送原料的数据采集和解释分析结果的“工人”? 或是成为在大数据驱动下的人工智能机器人的伙伴?这些都引人深思。
文/ 杨强 香港科技大学计算机科学及工程学系教授 华为诺亚方舟实验室主任(2012-2014)
✉️ zjuvis@cad.zju.edu.cn