简介
DeepDive是一个可以通过机器学习技术利用特定领域知识,并且通过用户反馈提高分析质量的开源知识提取系统。
其目标为帮助用户从数据中提取实体和关系,并对事实经行推理。
DeepDive可以处理结构化/非结构化、干净/带噪声的数据,并将结果输出至数据库。
主要面向从互联网非结构化数据中抽取结构化信息,做一系列后处理,构建知识库并抽取关系等。
DeepDive的特点为:
- 意识到数据存在噪音(不精确性),通过为每个断言设置置信度予以校正
- 数据源多样性,如文档、网页、图表等
- 可以通过使用已有的领域知识指导推理,接受用户反馈,提高预测的质量
- 使用Distant supervision技术,只需少量/甚至不需要训练数据
- 是一个可拓展的高性能推理和学习引擎
要求
用户需要:
- 对SQL和Python熟悉,以便使用Deepdive或集成Deepdive的工具开发;
- 需要对DeepDive进行改进的用户还需了解知识库构建(Knowledge base construction)、关系提取(Relation extraction)、Distant supervision、概率推理(Probabilistic inference)、因子图(factor graphs)等基础背景知识。
数据模型
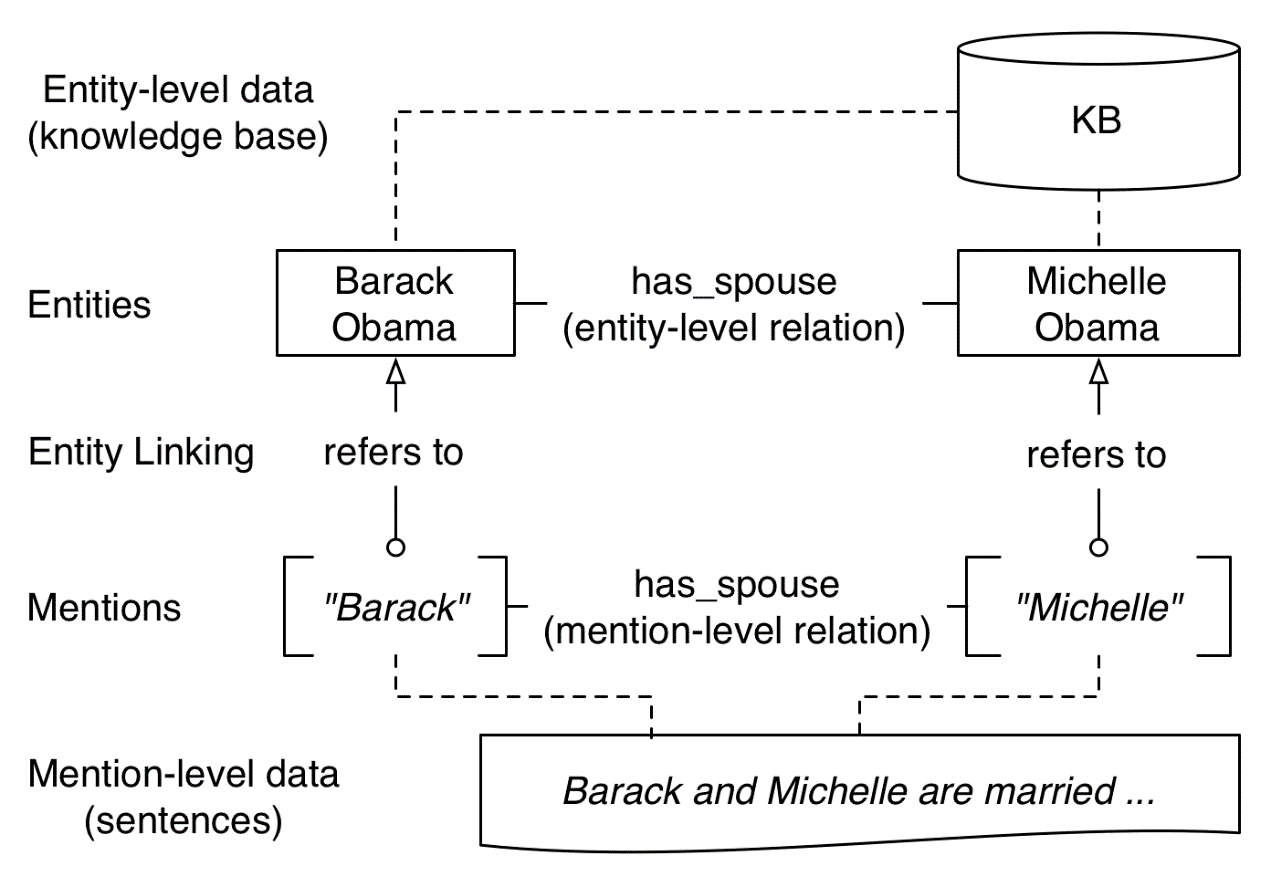
- 实体:现实中存在的事物,如奥巴马
- Mention:对实体的一个引用,如“奥巴马”三个字
- 实体级关系:实体间的关系
- Mention级关系:Mention间的关系
- 实体级数据:实体级关系的集合,如Freebase(知识库)中的关系
- Mention级数据:包含Mention的数据,如”Barack and Michelle are married”这个句子
- 实体耦合:Mention与实体的映射
工作流程
这里以“提取文本中Mention级关系”为例,介绍DeepDive的工作流程。
- 数据预处理。将数据(如文本)载入数据库并解析,获得语句级的信息,包括POS tags, named entity tags等。
- 特征提取。通过开发者编写的提取器,将数据数据转化为关系表示,称为evidence
- 建立因子图。开发者类SQL语言,声明推理规则。
- 学习与统计推理。DeepDive自动进行,可以计算出某特定断言的可能性。
图2为相应流程的示意图
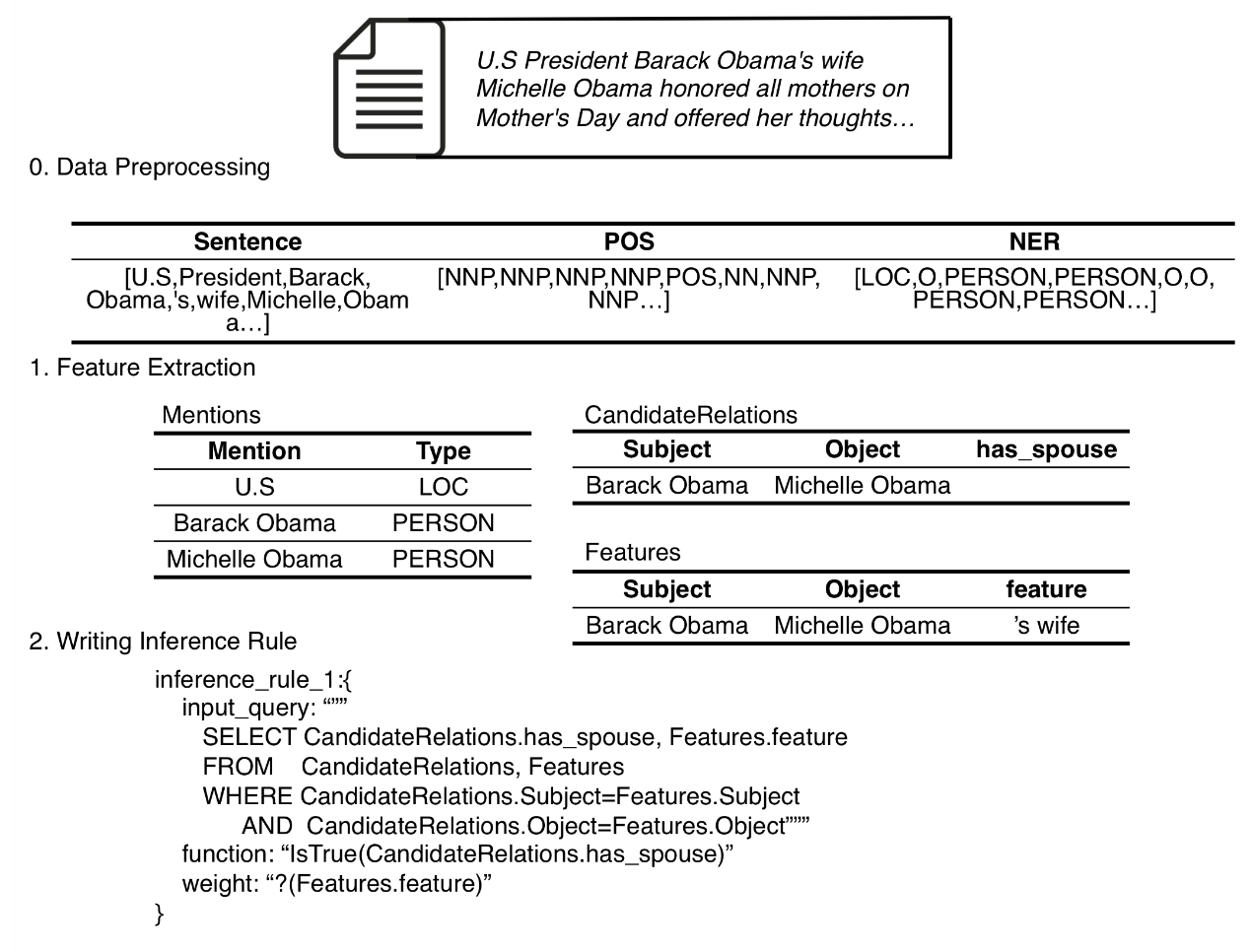
图2 流程示意图
开发者
主持人:Christopher Ré (Stanford University)
团队成员:
- Zifei Shan
- Feiran Wang
- Sen Wu
- Jaeo Shin
- Amir Abbas Sadeghian
- Ce Zhang
- Matteo Riondato.
相关链接
- http://deepdive.stanford.edu/index.html
- http://cs.stanford.edu/people/chrismre/papers/deepdive_vlds.pdf
Questions & Discussion:
✉️ zjuvis@cad.zju.edu.cn