城市数据规模与日递增,为政府职能部门制定新政策和提高管理水平进而提高人民的生活水平带来新机遇。然而,有效地分析城市数据依然存在诸多挑战。一方面城市数据规模巨大,另外一方面城市系统极为复杂其内在的时空特征难以处理。聚合方法在城市数据分析过程中较为常见。聚合方法的核心问题是聚合的粒度与探索数据片(Data Slices)之间的平衡。粒度(空间或时间)较粗能减少数据片的数量,但是可能导致信息丢失。例如图1显示的是2011年5月1日上午8点到9点纽约出租车上下客的热力图,图(a)中在第六大街没有出租车上下客的记录,因为当时此处因举行NYC 5 Boro Bike Tour而封路。然而在图(b)和(c)以天为单位的聚类很难发现小的局部事件。细粒度的聚合能避免此类问题,但是需要探索更多的数据片,在手工探索界面中寻找城市数据中的模式是不切实际的。在这篇论文中,作者试图通过自动方法检测发生的事件,以此指导用户探索感兴趣的数据。
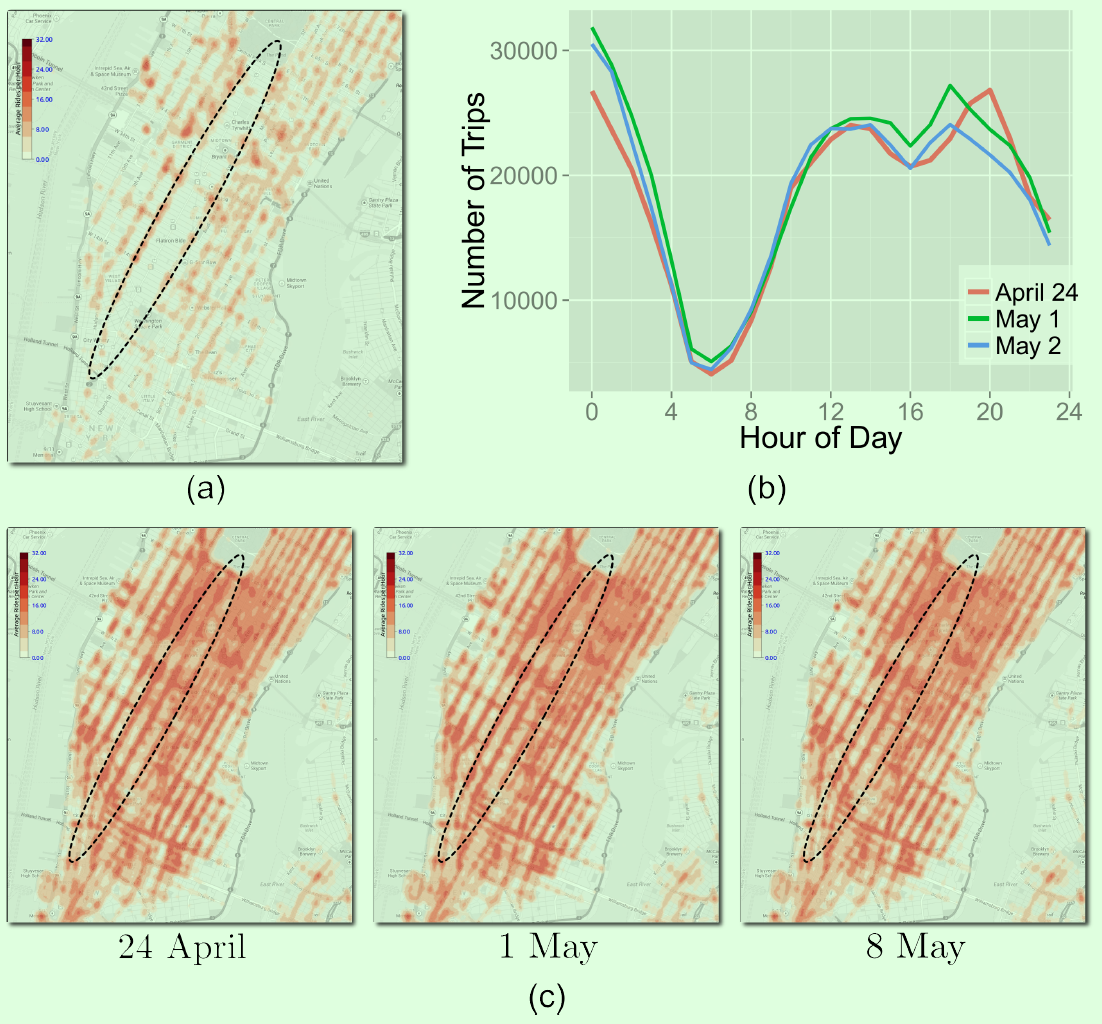
图1 难以检测的非常规事件
论文的主要特点在于:
用拓扑分析的方法检测事件,这种检测方法不仅能够检测出发生频繁的热点事件,而且对于出现频率不高的事件也能检测出来;
对相似事件建立了索引,便于用户检索。
此项工作的核心流程如图2所示,其中事件检测和分组是其最核心部分。
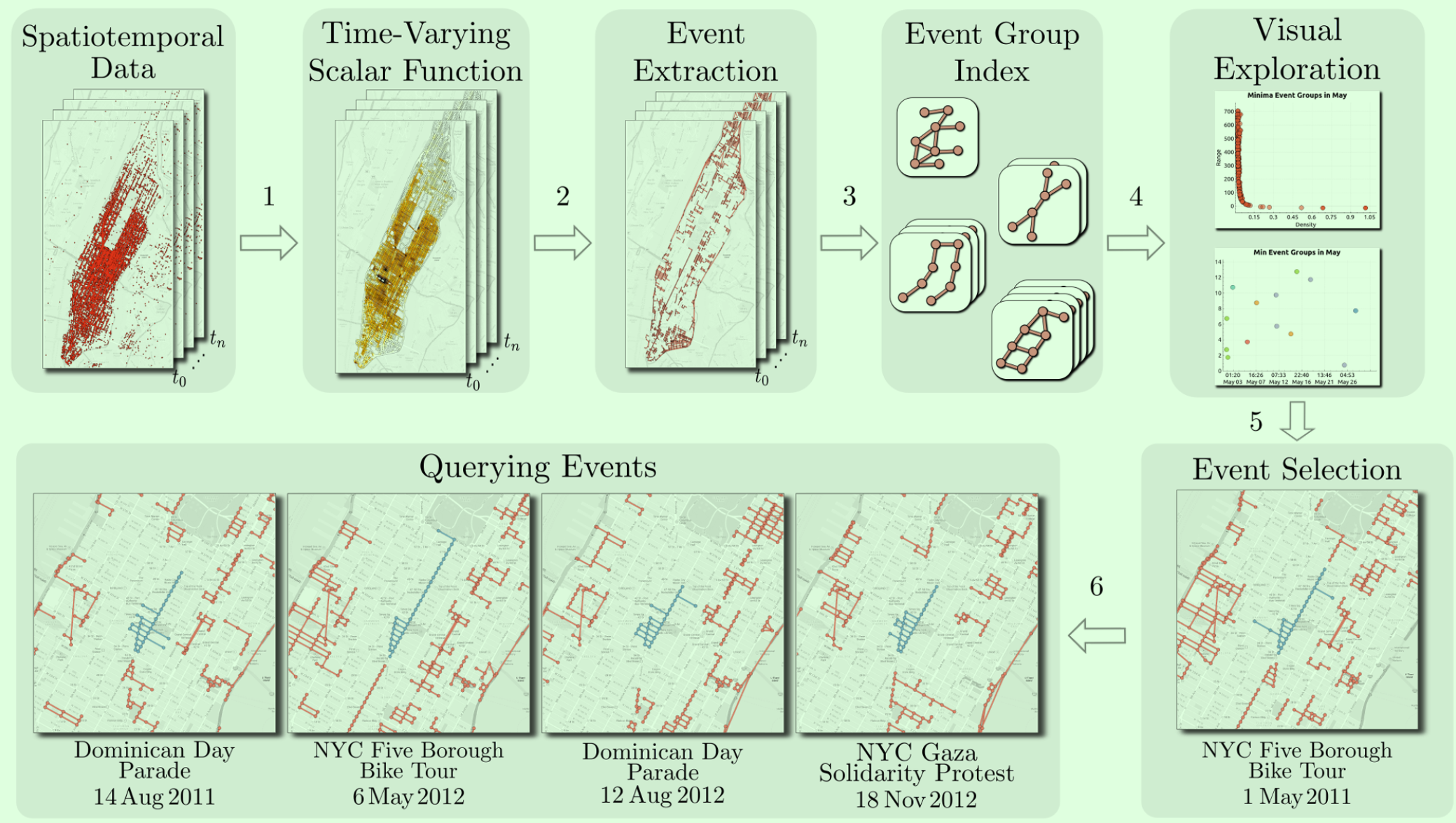
图2 系统流程图
在事件检测中,论文采用了计算拓扑学中相关概念(图3),如拓扑图,标量函数(Scalar Functions), 临界点(Critical Points), 拓扑持久性(Topological Persistence), 合并树和分割树(Join Tree and Split Tree)等。标量函数将拓扑图中节点的空间属性映射为实数便于计算拓扑持久性。临界点是拓扑图节点上标量函数出现最大值和最小值的地方,反映了两种不同的拓扑特征。拓扑持久性是不同临界点处标量函数值,反映了事件的重要程度。合并树和分割树分别抽象最大值和最小值两种不同拓扑结构。为了减少计算量,论文将树中较小的分支当做噪声进行剪枝。在计算事件过程中,为了保留一些热度较小但覆盖范围较大的事件,论文中还特别引入hyper-volume指标。除此之外,论文中根据事件发生地点的相邻性和事件的拓扑持久性判断事件是否相似。而隔时间较短的相似事件被合并成一个事件分组,每个时间分组都赋予一定的分组标识,该标识作为事件查询的索引。
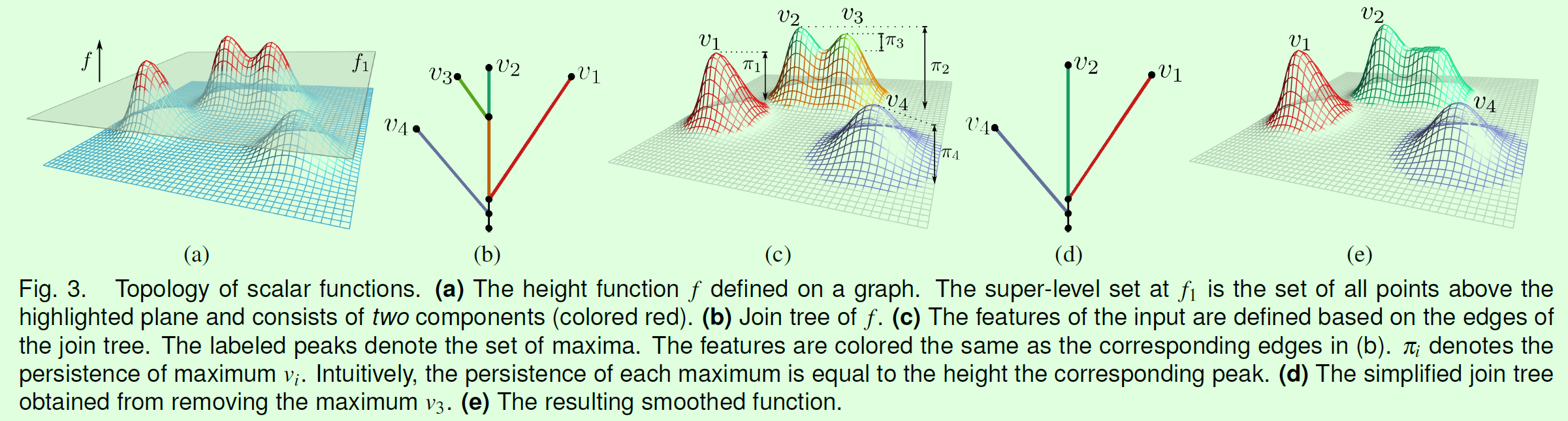
图3 拓扑学相关概念
论文以两类数据作为分析对象,一类是纽约出租车数据,另一类是纽约地铁运行记录数据。在出租车数据中,以曼哈顿地区的街道为拓扑图,路口为图中节点,街道为图的边。标量函数定义为一小时内每个节点中出租车的密度,而密度则计算为该节点一定范围内出租车记录的高斯加权和。地铁数据则以地铁线路为拓扑图,标量函数定义为每个站点地铁的晚点时间。论文设计了三方面的可视界面方便用户分析数据:地图视图和查询界面、事件分组分布和时间线视图、过滤界面。其中事件分组分布视图是散点图表示的二维分布图,横向为单位时间内事件发生的次数,纵向为事件持续的时间,坐标空间被均匀划分成四块区域,其中右下角的区域I最具代表性,通常反映出突发的影响较大的事件。
论文针对两类数据分析并给出了一些代表性的案例,如按小时、天和周出现的小事件(出租车数量相对于其周围较少),出现此类事件大多是因为假日游行导致道路封锁,如图4所示。
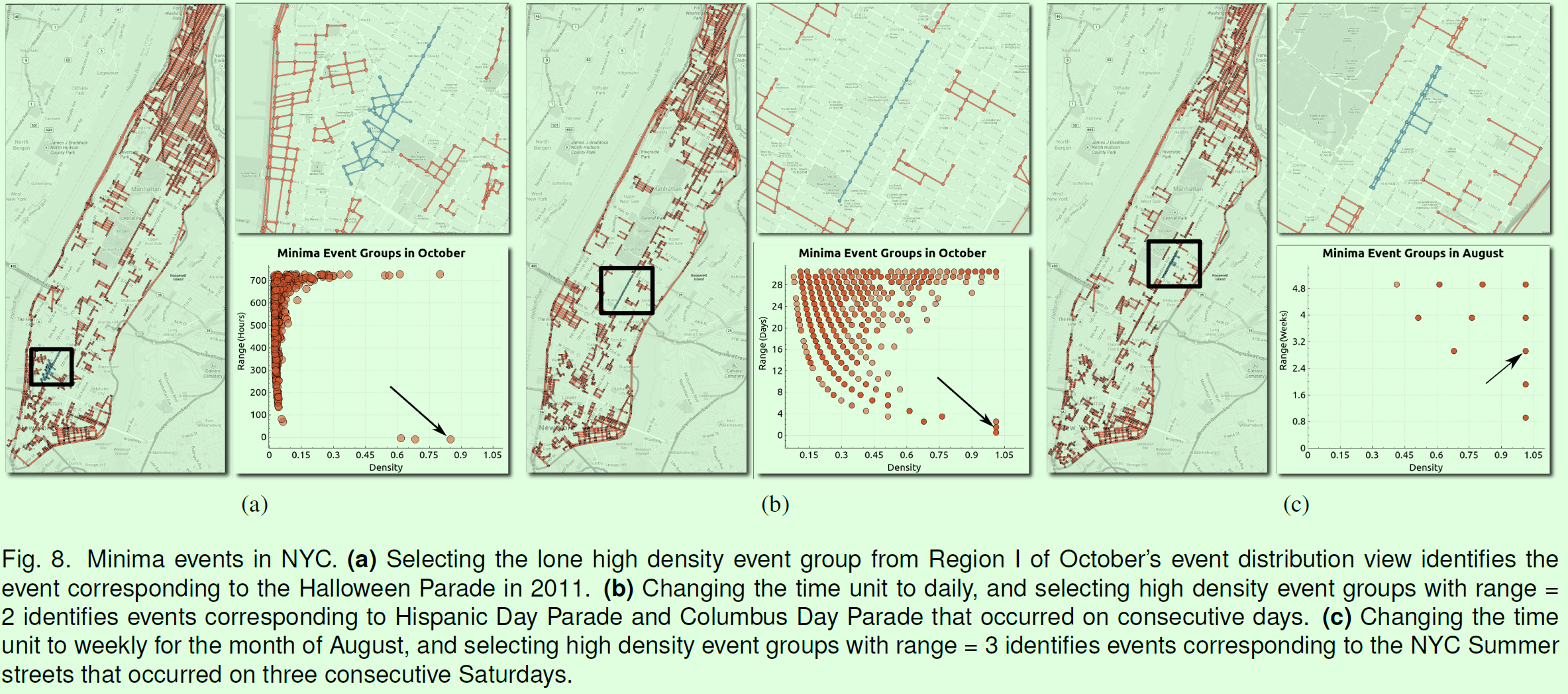
图4 纽约出租车案例
然而,由于标量函数的选取、相似性阈值的选择都会对事件的计算产生一定的影响,例如标量函数可以有多种计算方式,但是究竟哪些更有效则需要多次试验。
✉️ zjuvis@cad.zju.edu.cn