作者: Ding Chu, David A. Sheets, Ye Zhao, Yingyu Wu, Jing Yang, Maogong Zheng, George Chen
PVIS 2014
对出租车轨迹数据进行数据挖掘或者可视化的文章近年来日益增多,本文比较新颖地将文本主题抽取的方法用到了出租车轨迹数据之上,使得轨迹数据能够被赋予一定的语义并增加了解读性。
作者选用了深圳 21360 辆出租车的每日 GPS 轨迹数据。首先将每一个 GPS 地理坐标映射到具体的街道上,这样就将街道作为词,一辆出租车的轨迹即一个街道名称的序列作为一段文本,多辆出租车的轨迹构成一个文本集合,作为 LDA(Latent Dirichlet Allocation)主题抽取的原始材料。而经过主题抽取,主题和街道、主题和轨迹都有了对应关系,可以得到街道或者轨迹在每个主题上的概率分布(表 1 表 2)。直观上,一个主题相当于一个地区,包含许多街道。
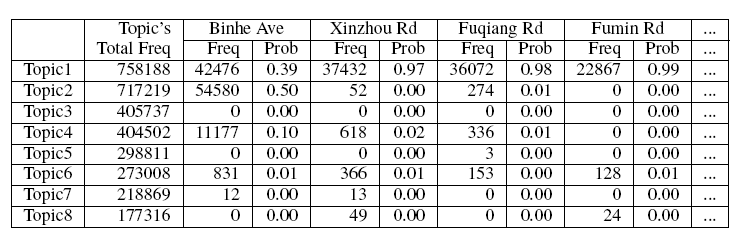
表 1

表 2
作者也分了几种情况抽取主题,如载人和空车两种情况。考虑到 LDA 算法主要的依据是词频,这样当车行驶在低速路段的时候,会发生 GPS 记录点过多引起的街道名出现频率过高的情况,与之相反,在高速路段,GPS 记录点则很稀疏,引起词频分布不均衡。为了克服这个问题,作者进行了速度补偿,设定一个阈值 St,当车速高于阈值时,在轨迹记录点之间增加插值出来的伪轨迹点。
在抽取出来主题的基础之上,作者用信息熵重新包装了街道在主题之中的概率分布(街道熵),以及单车轨迹在主题之中的概率分布(轨迹熵)。其中街道熵高证明该街道连接数个主题(地区);轨迹熵高证明该车出行范围广,穿越多个主题(地区)。
为了讨论主题演化,作者将一天的时间分为数个时段(文中为 3 小时),在每一时段分别抽取主题。这样的直接效果是每一个时段都能抽取出 n 和主题,为了计算这些主题之间的连续性,作者采用了如公式 1 的相似度度量,其中 Ti 和 Tj 为两个不同的,且处于相邻时段的主题,Sij 为相似度。
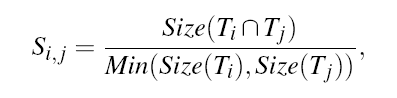
公式 1
在介绍完方法及概念之后,作者设计了名为 VATT(Visual Analytics of Taxi Topics)的可视分析系统。其综合了主题地图、街道云、平行坐标、主题时序演化四个视图(图 1)。其中主题地图将选取某一主题中前 m 位的街道并用一种特定的颜色标识,当主题和主题间有重复的街道时,可以采用比较该街道在不同主题之间的概率大小,或者用街道熵等指标定出优先级,覆盖绘制。街道云计算了街道主题概率分布的余弦相似度,并用投影算法将其分布在平面上,用颜色区分主题。平行坐标的纵轴为主题,连线为一个街道。主题时序演化用圆的大小编码某一个时段内该主题的频数,并从大到小依次排列,圆之间的连线根据如上所述的主题相似度计算得出,粗细编码相似度的大小。

图 1
由于本文分析案例较多,这里仅以两例说明这个系统的用法。
如图 2 所示,该图标识了在 9:00 am~12:00 am 所有主题的 top30 街道,可以看到不同主题的街道都比较好地分离了出来,在主题 2 的街道云视图上(图 3,图 2 的红色街道),可见 BinheAve、BeihuanAve 和 G205 远离群体部分,BinheAve 和 BeihuanAve 是连接东西的大动脉,G205 连接东北,均为交通枢纽,和别的在一个地区内的街道都不一样,这些从平行坐标视图上也能略窥一斑(图 4)。
图 2
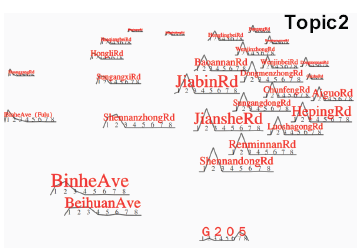
图 3
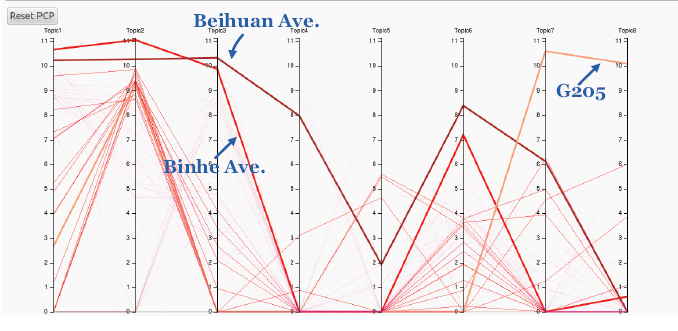
图 4
另一个例子,如图 5 所示,图 5a 为空车在 3:00 am~ 6:00 am 的主题,图 5b 为载客在 3:00 am~ 6:00 am 的主题,明显可见空车为了寻客,游走在城区之中,而载客车辆为了快捷,往往走绕城高速。图 5c 为载客在 6:00 am~ 9:00 am 的主题,可见随着时间的推移,城区道路开始复苏,绿色道路为机场到罗湖口岸,在这个时段热度开始有所上升。图 6 为主题在一天中的演化情况,和图 5 对应。红紫两线条,对应 Luohu 和 Futian 两区,基本维持在头两位,其中在 9:00 pm~12:00 pm 红紫两圈较大,这两区都是商业和娱乐中心,说明在这个时段,这些地区夜生活比较丰富。而棕色线条对应的 Bao’an 其在各个时段变化波动较大,原因是这个地区为居民区,不似商业中心那么活跃。
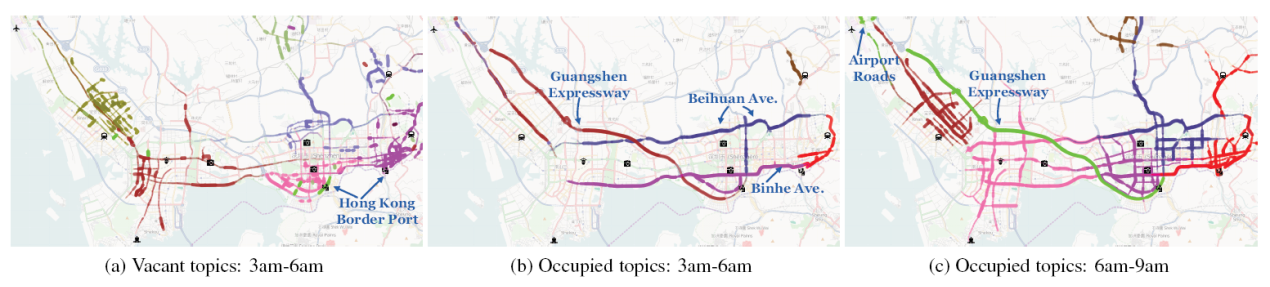
图 5

图 6
总的来说,该文使用的方法还是比较新颖的并且有一定的借鉴意义,可以发现成组轨迹的运动模式;能够容忍一定程度的错误和噪声;并且降低了分析的维度,将轨迹的坐标简化到带有语义的主题,方便了分析。
✉️ zjuvis@cad.zju.edu.cn