论文:Visualizing Large-scale Parallel Communication Traces Using a Particle Animation Technique
作者:Carmen Sigovan, Chris W. Muelder, and Kwan-Liu Ma
会议:EuroVis 2013
并行计算在提升计算速度的同时,也会由于参与并行的各个节点之间的通信而带来额外的开销。这种开销通常会随着并行规模的增大而增加,而且它对于并行性能的影响也难以测量。此外,随着一些并行库(比如 ScaLAPACK)的广泛应用,底层的 MPI 细节被隐藏,使得对于并行计算中通信行为的分析更为困难。
本文提出了一种基于粒子动画的技术,用于分析并行计算中的通信行为。目的在于帮助用户看分析这些通信行为的模式,从而使用户可以发现影响并行性能的问题并加以优化。本文提出的方法可以支持多达 16,000 个处理单元的并行规模。
可视设计
下图是本文可视化的主视图,即粒子动画部分。横轴对应了处理单元(processor),按 rank 从小到大一次排列,并进行分组,组的边界上标明了处理单元的编号。纵轴是时间,由于在 MPI 的通信时间的时间跨度很大,所以采用了对数的形式。每个粒子则对应了一个 MPI 消息事件,不同类型的事件用不同的颜色进行编码。每当一个事件出现,就会在对应的处理单元的位置出现一个点,然后随着时间的推移,这个点会往上运动,这样一来就形成了动画。当事件结束的时候,对应的点就会停在最终的位置,然后慢慢淡出。当然,本文并没有将淡出的点直接舍弃,而是以一定的透明度叠加成了一张背景纹理,作为对历史事件的概览。

模式提取及分析
针对粒子动画的一些结果,作者抽象了如下 5 种模式:
- 水平线—-表示并行程序是负载平衡的,是一种理想的情况
- 不规律的—-没有特定的解释,可能由于网络拓扑、负载倾斜、任务依赖等原因
- 斜线—-文中给的例子中斜率很小,解释为受网络影响
- 对数曲线—-rank 大的处理单元中,事件会滞后,可能由局部串行的算法造成
- 部分 Processor Group 和其他的行为模式有明显差别—-由于它们被分配的计算任务差异

然后通过对一些并行算法的实验来解释这些模式出现的原因。比如说,作者发现 ScaLAPACK 中的 Cholesky decomposition 的通信行为呈现一种(d)对数曲线的模式,进一步分析发现这是由于该实现采用了一种 right-looking 的算法,每当完成一列的计算,需要对该列右边的列进行更新,所以 rank 比较大的处理单元的事件会出现一定的滞后。
细节设计
本文给笔者的一个印象深刻的地方是对可视化的细节非常重视,举三个例子:
- 颜色编码:考虑到人可以区分的颜色种类有限,所以作者将具有类似功能的 MPI 函数用色调相近的颜色去编码,使得在最终的动画中,用户可以很快地分辨出当前正在进行的通信类型。
- 纵轴 Label:可以看到在动画的纵轴上,标有一些时间刻度,作者在选择这些刻度的时候除了考虑对数增长外,还考虑到了 label 之间不能重叠,也就是说两个刻度之间的空间要足够放置一个 label。这样在保证纵轴信息丰富的同时不至造成视觉遮挡。
- 背景的透明度设定:由于通信行为十分复杂,使得有些位置的事件密度特别大,而有些位置可能只有个别事件,如果对每个事件使用统一的透明度,那么要么密度大的地方都变得不透明,要么密度小的地方由于透明度太大几乎看不见。所以作者设计了一种对数变化的透明度策略,公式如下图所示,只有当密度达到最大 Dmax 时,才变得不透明,而即便某个位置只有一个事件,它的透明度也不低于预设的最小值 Omin。
![]()
所以放开可视化的功能不谈,单单可视化效果也对这个工作有不少加分,下面是一些漂亮的结果:
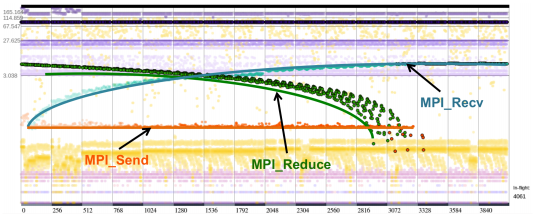
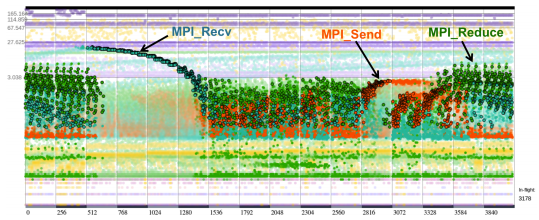
将来工作
本文方法虽然可以较清晰地看出一些并行计算中的通信模式,且支持超大的规模(16,000 核),但是由于是 per-event 的可视化,当事件过多地时候,还是会有视觉混乱,所以之后可以做一些 aggregation、zooming、filtering 的工作,已减轻视觉混乱。此外,short-event 和 long-event 的行为模式、对性能的影响差别比较大,可以考虑将两者分开分析,而不是通过对数坐标轴将两者统一可视化。
✉️ zjuvis@cad.zju.edu.cn