论文:UTOPIAN: User-Driven Topic Modeling Based on Interactive Nonnegative Matrix Factorization
作者:Jaegul Choo, Changhyun Lee Chandan K. Reddy, and Haesun Park
Georgia Institute of Technology
会议:IEEE VAST2013
文本主题抽取是一个很重要的话题。何谓“主题”?从字面上理解是一段文字表达的中心思想。从统计模型的角度可以用关键词的分布来刻画。这样一段文字可以理解为是从一个概率模型中生成的。
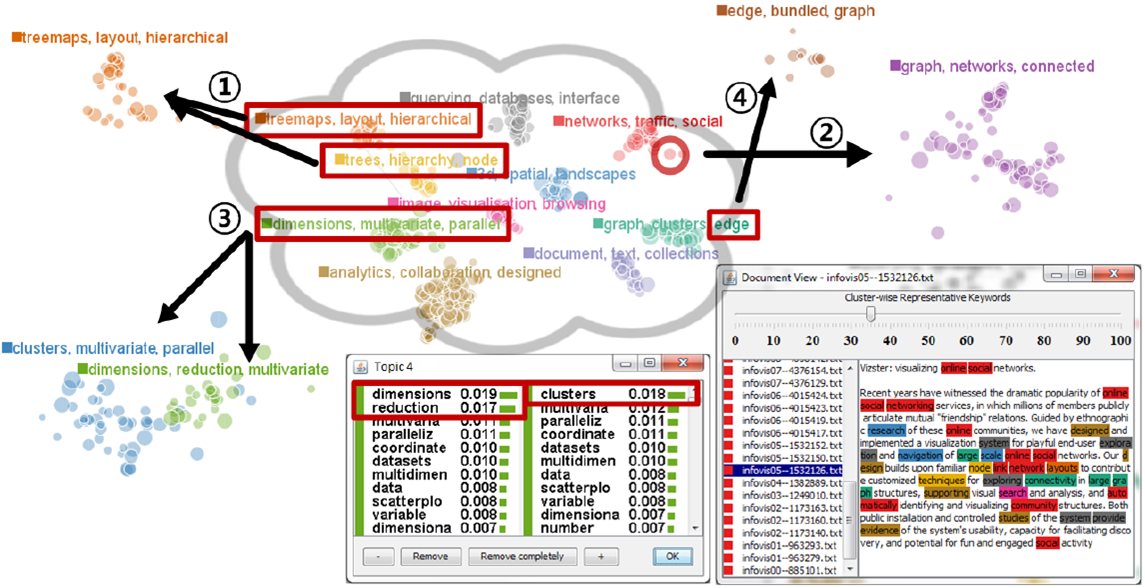
Utopian 可视界面。图中每个点代表一个文本,不同颜色编码了不同文本对应主题。用户基本操作包括了:
- 将某两个主题合并
- 以某文本生成新主题
- 对某个主题进行分裂
- 以某关键词生成新主题
传统的主题模型有 TF-IDF,LDA 等,甚至 K-means,PCA 也可以辅助分析文本。但是这些方法都存在一些问题。
以 LDA 为例, Blei 在 2003 年提出的 LDA(Latent Dirichlet Allocation)模型让主题模型火了起来。对于语料库中的每篇文档,LDA 定义了如下生成过程:
- 对每一篇文档,从主题分布中抽取一个主题;
- 上述被抽到的主题所对应的单词分布中抽取一个单词;
- 重复上述过程直至遍历文档中的每一个单词。
LDA 主要有两个问题:
- 算法多次运行,其输出的结果不一致;
- 主题抽取过程中无法结合用户的经验与反馈。
UTOPIAN 是佐治亚理工开发的交互式主题模型系统。它使用了非负矩阵分解解决了以上两个问题。
NMF,非负矩阵分解,它的目标很明确,就是将大矩阵分解成两个小矩阵,使得这两个小矩阵相乘后能够还原到大矩阵。非负矩阵在日常生活中用的很多:数字图像中的像素一般为非负数,文本分析中的单词统计也总是非负数,股票价格也总是正数。把文档-关键词的对应矩阵看做一个非负矩阵的话,其分解可以帮我们找到潜在主题。
用户可以对非负矩阵的分解进行多种操作:比如主题的合并,主题分裂,以某个文本生成主题,以某个关键词生成主题,修改关键词和主题的对应关系等等。
具体可以查看系统视频:http://www.cc.gatech.edu/~joyfull/resources/2013_tvcg_utopian.mp4
✉️ zjuvis@cad.zju.edu.cn