本文基于 Eamonn Keogh 在 VLDB06 上做的 Tutorial:A Decade of Progress in Indexing and Mining Time Series Data
一直以来,时序数据分析就是可视化的一大研究热点,那么作为数据分析的另一大手段数据挖掘在分析时序数据方面又有着怎样的思路呢
相似性的使用(The Utility of Similarity Measurements)
数据挖掘在时序数据分析中的任务有聚类、分类、重复模式发掘、规则发掘、时序检索、异常发现等,归根结底,这些都能归为相似匹配的问题。
在时序数据上存在微观形状上和宏观结构上的相似性,对于这两种相似性使用方法各不相同(图一)。
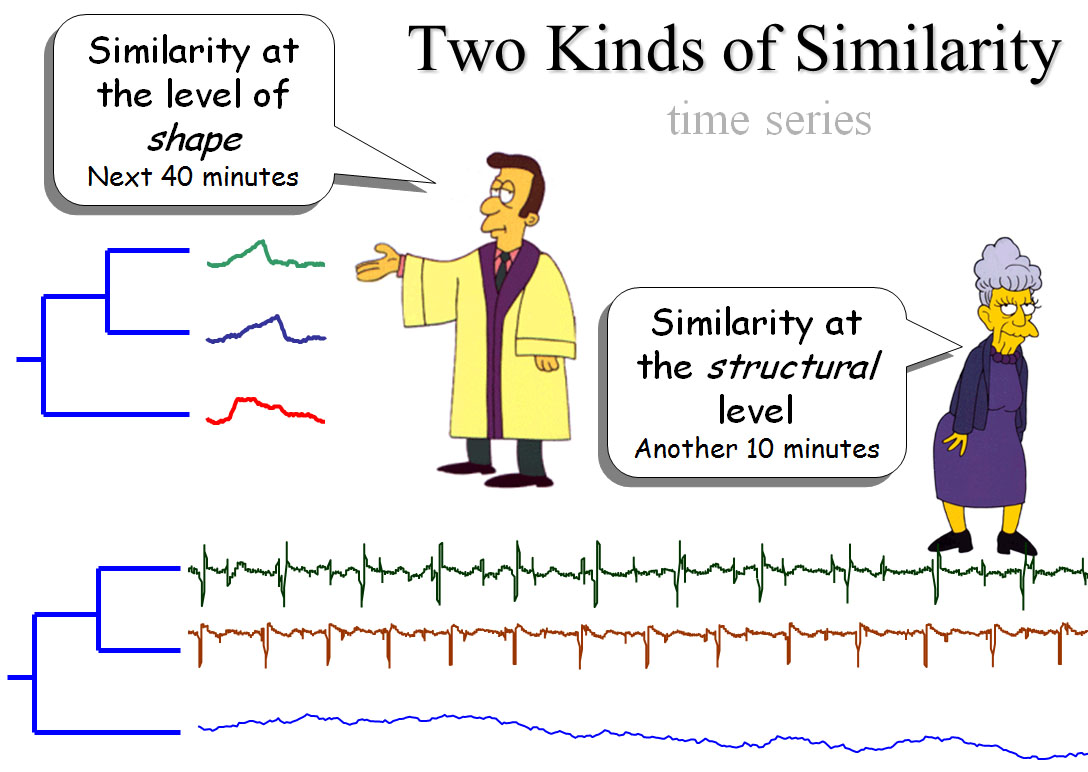
图一
先来看 the level of shape,计算两时序数据微观层次上的相似性往往需要先进行数据的预处理,以减少数据偏置、幅值缩放、线性趋势以及噪声对接下来计算造成的影响。
预处理之后需要定义一个距离尺度,如欧式距离(80%已发表的数据挖掘工作皆用欧氏距离),在两条时序数据相对应的数据点之间累计欧式距离从而定义出两条时序数据之间的相似性。
但是计算固定对位数据点之间的欧氏距离效果往往不好,因此需要引入动态时间规整(Dynamic Time Warping,DTW)的方法,动态调整对位的点,从而找到一条累计距离最小的路径,提高相似性计算的精度(图二)。
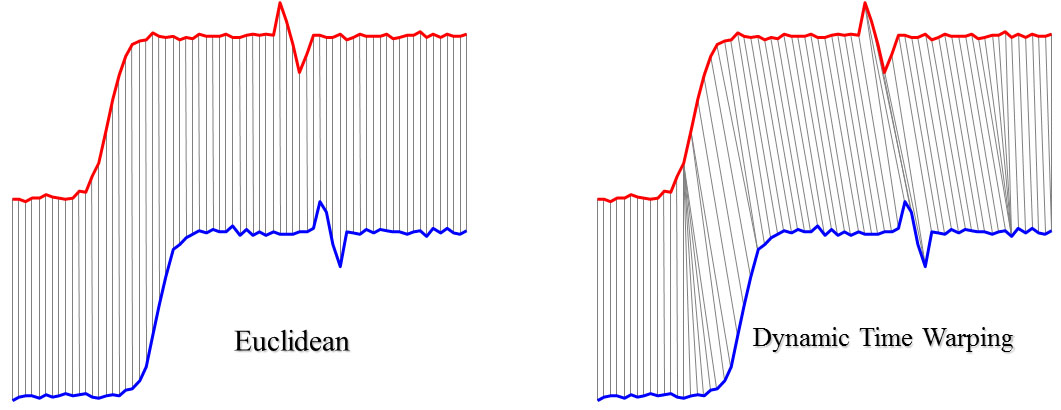
图二
虽然 DTW 计算的相似性较固定对位数据点的欧氏距离较为优越,但是在计算效率上 DTW 需要花费的时间要多很多。
提高 DTW 计算效率的方式有很多,比如降采样,设定全局限制或者设定 lower bound 等等,都能够大幅或者细微地对计算效率有所改善。
Uniform Scaling 是另一个在计算相似度上的重要工具,如图三所示,调整缩放因子(scaling factor,sf)后,相似性计算可以更加精确。
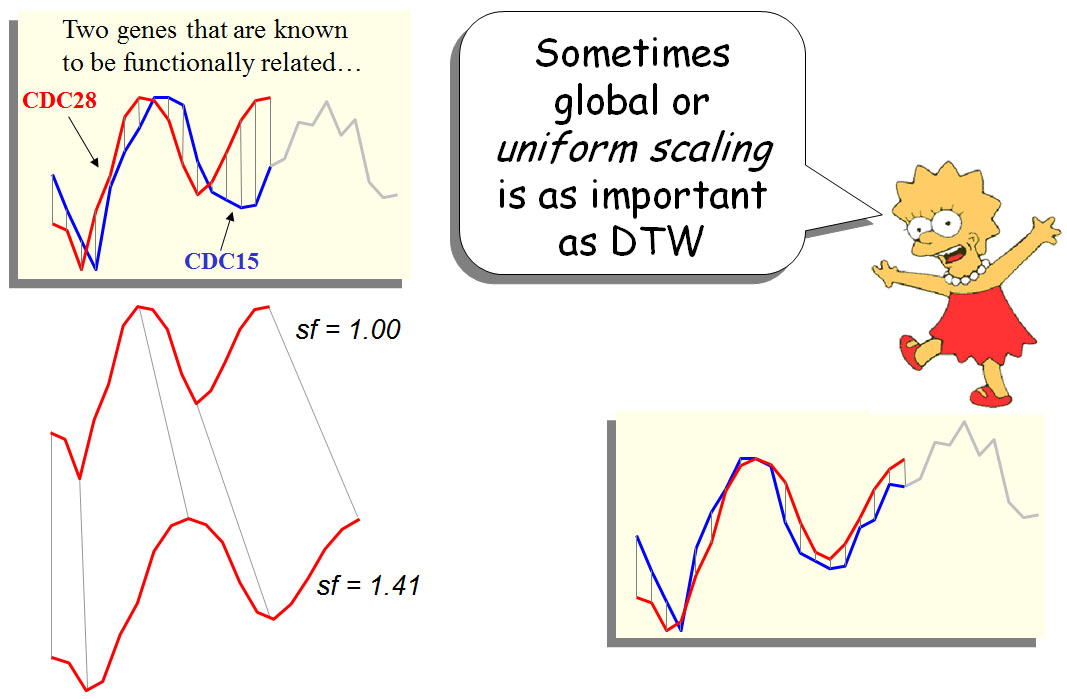
图三
除了对位的欧氏距离,以及 DTW 还有很多其他用以计算相似度的方法,但是最有用的还是前两者。
再看 structural level,最基本的思路是抽取时序的全局特征,如最大值,过零率,构建特征向量进行比对。也有利用模型如 ARMA,马尔可夫等对时序进行建模,最后比对模型的参数。
时序表达(Time Series Representations)
一般的数据挖掘过程会创建元数据的估计,以减少数据量从而更有效地在主存中进行计算。鉴于此,如何创建有效的时序重表达非常重要。
如图四,重表达的创建需要满足某些条件,即重表达后两时序之间的距离小于未做处理的距离。重表达的方法非常丰富,图五列出了其中的一部分。
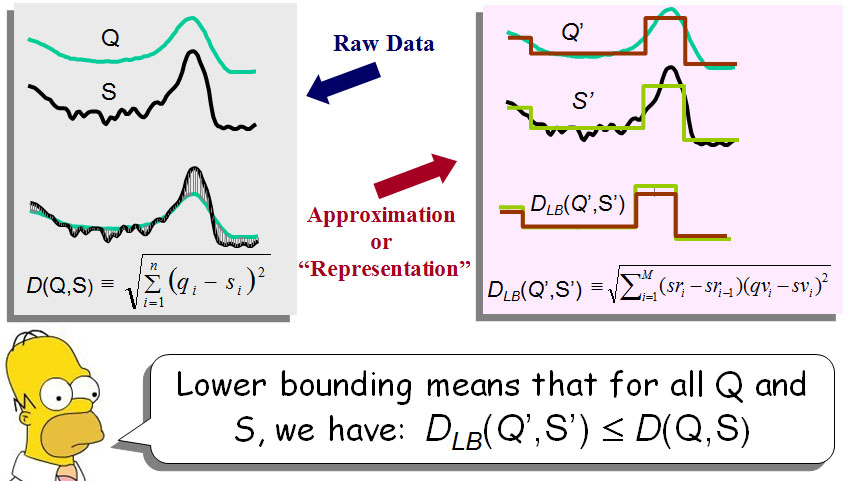
图四
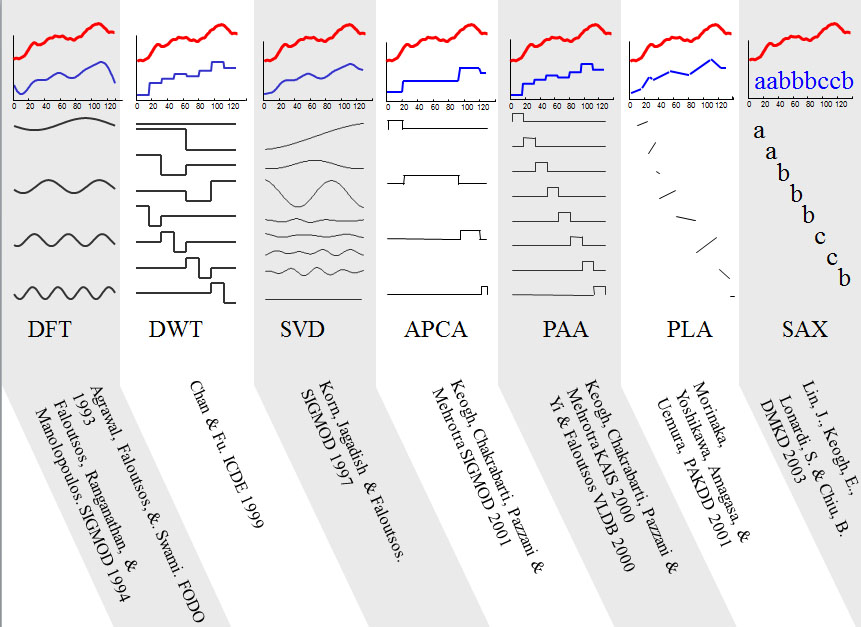
图五
时序数据挖掘(Data Mining)
时序数据王珏关注的问题有:异常/兴趣数据检测(Anomaly/Interestingness detection),以及重复模式发现(Motif (repeated pattern) discovery)。
对于前者,有非常简单的设置阈值上下限,检测过界的方法;也有类似文本挖掘的方法,利用训练数据建模,从而判断实际数据是否是异常。异常检测这个问题实际上也是相当开放的,仍然可以研究的问题包括:如何对大规模,有人为交互干预,带注释的时序数据进行检测。
在重复模式发现方面,比较热门的方式有借鉴自生物信息学,随机投影等,具体可参考原作者 ppt 中的描述。
此外,借助可视化的方法,我们也能完成时序数据重复模式发现以及多条时序的相似性聚类等等任务,如作者的两个工作:VizTree 和 Time Series Bitmaps。
时序数据挖掘仍然值得探究的问题
尽管作者认为时序数据挖掘中的相似性搜索已经做无可做,但是这个领域依然有许多悬而未决的问题:
- 摆脱参数设这去发现时序中的重复模式
- 对不断更新的流数据进行聚类
- 和具体问题相关的时序相似段落匹配
- 理解并解释时序分类和聚类的深层含义
- 时序数据可视化
- 研究比线性的 DTW 更有效的方法
- 加权的时序数据重表达
- 检索并解释突发事件
- 有关时序数据挖掘的应用程序
✉️ zjuvis@cad.zju.edu.cn