AT&T 的 Emden R. Gansner、胡一凡和 Stephen North 在 Graph Drawing 2012 上发表了一篇关于文本流可视化的文章,无论是文章解决的问题、采用的方法、最终结果甚至写作手法都堪称一流,因此此文被评为当年的 Best Paper。
论文的目标是如何帮助用户领会大规模文本流数据隐含的知识,作者提出了一种可视化分析方法,重点考虑三个方面的问题:如何分析并可视化流数据;通常时间相近的消息语义上更相似;用户需要浏览文本细节的工具。为此作者开发了 TwitterScope 系统,动态监测 Twitter 上发布的消息,经过实时语义分析、聚类与可视化映射、以及动态更新视图等过程,不仅为用户呈现了 Twitter 中相关话题的整体视图,而且能让用户查看历史记录和消息内容,系统界面如图 1.
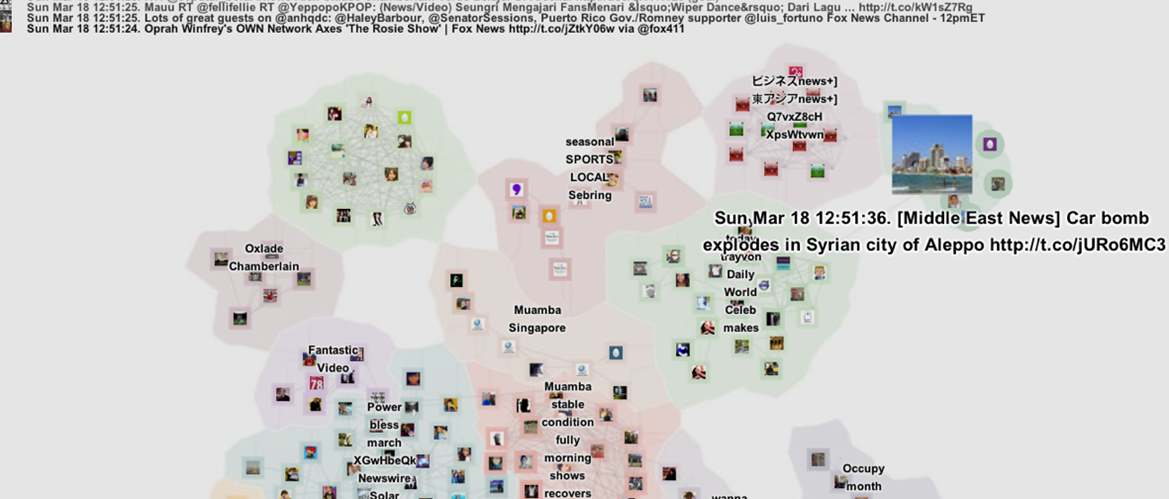
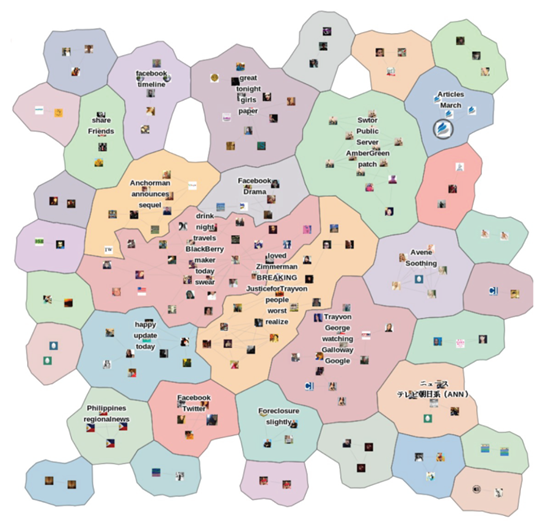
在文本分析过程中,论文比较了 LDA 和 TD/IDF 方法,发现尽管 LDA 理论上结果更准确但是在 Twitter 这种短文本的分析上效果并不理想,因此最终采用了 TD/IDF 方法。由于消息动态到达,话题中的关键词权重会动态变化。系统设计了一个时间窗 N,对当前时间之前的 N 条消息进行分析,当 N 很大时,话题的变化较小。当两条消息相似性超过一定阈值(默认 0.2)时,则用边相连,边的权重为二者相似性大小,最终分析的结果形成图结构。聚类和可视化映射都采用了经典的方法,MDS 用于高维投影,模块化聚类根据权重将相似的消息聚拢。由于 MDS 具有良好的距离保持特性,高维空间中相似的节点在平面上仍然距离更相近。图 2 显示了对各类别消息添加色调之后用地图隐喻的可视化结果,每块区域即为一个“国家”。
在动态布局上,作者下了一番功夫来保证新增加的节点不会对先前的视图造成很大的变化,即所谓 mental map perservation.作者分两步来实现,首先确定新视图中每个节点的位置,其次由于每个节点其实是图片,所以尽量保证图片有较少的形变(Procrustes 变换)。
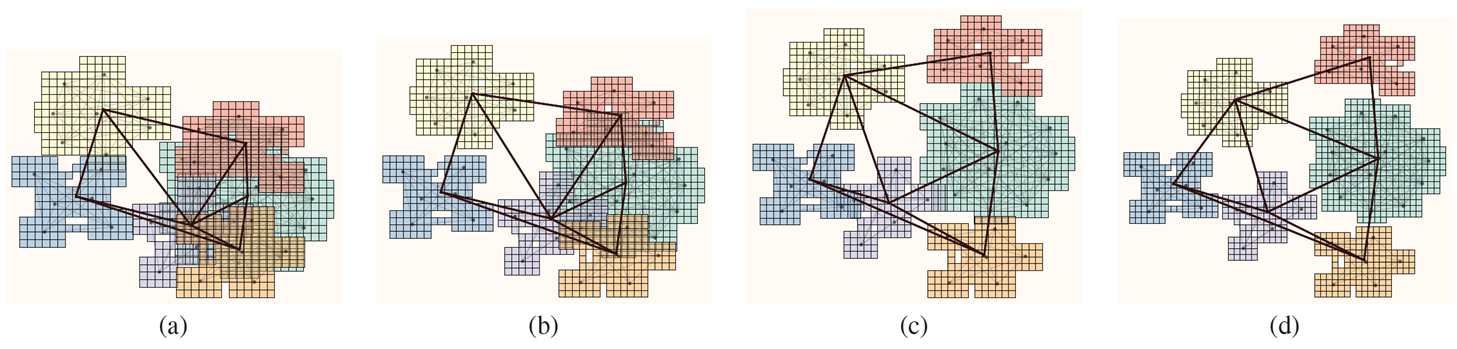
真正原创性的工作是对散落分布的图元的可视化上。由于可能存在很多话题,不同话题之间的消息并不相连(不相似),因此需要消除不同“国家”之间的重叠或拉近不同“国家”之间的距离。论文采用 polyminoes 算法检测“国家”之间是 overlap 或 underlap,并引入距离因子充分利用可视化空间,实践表明这种方法能够快速收敛。图 3 展示了初始重叠的图元经过三次迭代后的最终结果。
论文给出了很多实例表明其方法的有效性,例如图 4,从中不仅能看到历史时刻的话题主要描述的内容“Thailand”,”kill”, “Bombing”,而且点击具体的 tweet 可以引导用户进入具体的网页查看关于此话题的具体新闻。

✉️ zjuvis@cad.zju.edu.cn