论文:Comparing Clusterings Using Bertin’s Idea
会议:Infovis 2012
作者:Alexander Pilhöfer, Alexander Gribov, and Antony Unwin
本文介绍了一种对多类别型(或多聚类)数据可视化结果重排布优化的度量及方法。
1981 年 J.Bertin 在《A Semiology of Graphics》一书中强调,有序概念的发现会是逻辑简化的终点。这样的思路放之可视化,则意为一个好的排序会明显改善可视化的效果。
而在多类别型数据的可视化中,类别之间的排列顺序对可视化结果的影响可以下图为例,对 ecotest 数据集进行聚类之后得到两个类别,用 fluctuation 图表进行可视化。
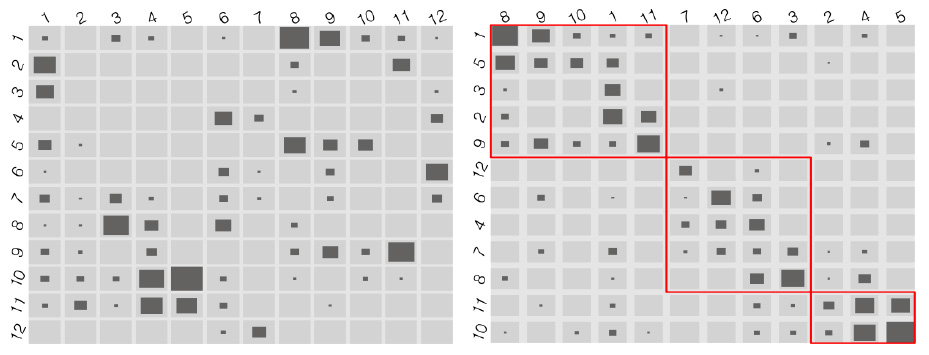
横行和纵行分别为两种聚类方法各自分出的 12 个类,每一个单元格中深色矩形的大小编码了同时属于单元格对应两个类别的数据点数目。左图中各个类别排列的顺序是随机的,而右图是经过本文方法优化过后的结果,可见通过调整行和列的排布顺序,矩阵呈现一种类似“伪对角”的状态,而根据这个结果我们就能重新审视两种聚类算法做出的结果,并将其合并成如红框标定出来的三个聚类。
通过上述的二类别数据可视化案例中可以看到,调整后的 fluctuation 图表越接近伪对角则越能反映出聚类之间的共性及特异的情况,因此作者接下来就提出 Bertin classification criterion (BCC)这个标准来度量调整后的结果的伪对角程度,并用 Bertin classification index (BCI)这个归一化成[0, 1]的值来作为可比较的度量,BCI 越小,则结果越接近伪对角,可视化效果越好。BCC 和 BCI 的求法是采用一种累计矩阵单元格相关对的方式进行的,具体可参考本文 3.1 节。
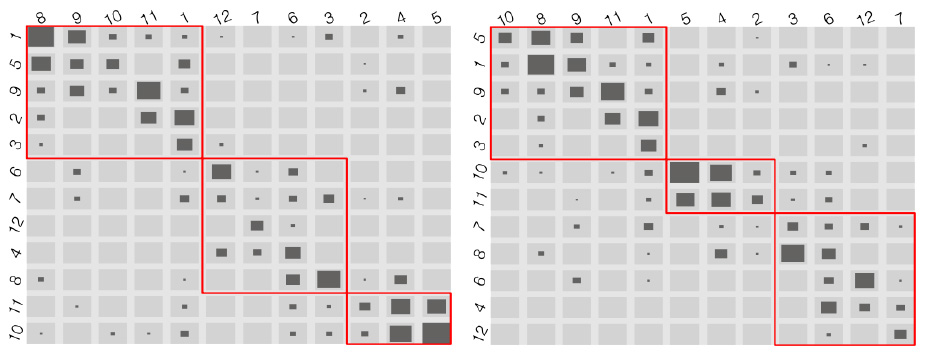
在以上的基础上,作者又提出了加权的 BCC 和 BCI 即 the weighted Bertin classification criterion (WBCC)和 the weighted Bertin classification index (WBCI)。这里的权值把 fluctuation 图表中单元格和单元格距离的因素融入度量,导致最后的结果各个单元格中值的分布更加平均。如下图所示,左图为运用 BCI 优化的结果,右图为用 WBCI 优化的结果,可见左图中最左上和最右下两个单元格内的数据点较多,而且这两个单元格分隔较远,而右图中这该两个单元格距离较近,而且整体上右图的分布也较为均匀。
对于多类别(大于两个类别)的数据,作者又给出了 BCI 的多变量版本,称之为 MBCI 和 MBCI*,分别反映了所有类别上都没有交集的数据对,和至少两个类别上有差异的数据对的情况。下图展示了对 ecotest 数据集用四种方法进行聚类后得到结果的可视化,可见在平行坐标集上用作者的方法后,左图呈现出遮挡交叠的现象在右图中都在一定程度进行了优化。

整个算法是用迭代的方式进行的,以前面所述的二类别数据为例,算法会选取两个聚类的初始排布,然后在这个初始排布上换行或换列,直到计算出一个优化的结果。
初始排布是在一定数量的随机排布中选取的,以 BCI 为指标,选择 BCI 最小的为初始排布。迭代中的换行或换列是用类似穷举的方式进行的,在 n 行 m 列的 fluctuation 图表中,计算(n-1)^2 个行操作以及(m-1)^2 个列操作中(即将第 i 行/列移至第 j 行/列的单步操作)结果最好的作为下一次迭代的初值。对于层次聚类的数据,换行或换列则要考虑到层次节点的影响,依照层次依次更换下层聚类的顺序。
前面所述可以比较完整地勾勒出度量的计算以及实现,但是在实现一个伪对角的排布之后,又如何自动地定义出如开头图片所示的红框重定义出的聚类呢。对于二类别数据,作者设计了一种自上而下的方法搜索截断点即红色矩形的交接点。参数化地定义了不同尺度的截断点,下图展示了一些结果,橙色框,实线红框,点线红框,点红框尺度由大到小截断出不同的部分。

本文本质上是一种针对类别型数据可视化结果优化的方法,以伪对角为目标,换行或换列为手段,设计了用于评价是否接近伪对角排布的度量,因此易于使用,且容易计算,也易于推广到其他类别型数据中去。
#
✉️ zjuvis@cad.zju.edu.cn