“标注”的可视化之旅
论文:Just-in-Time Annotation of Clusters, Outliers, and Trends in Point-based Data Visualizations
会议:VAST 2012
作者:Eser Kandogan
大家都在如何投影、自动聚类等算法上纠结反复的时候,Eser 直截了当地在可视化的原图上做标注,也在挖掘信息上取得了不错的结果,为用户提供了明确的语义指导。
顾名思义,文章主要的集中在三种特征的标注上——聚类、异常点、趋势,同时为了达到很好的交互效果,要能及时的做出反馈,所以使用的算法时间复杂度的要求很高,一般不超过 O(n^2)。暂时这篇只在点集上做了工作,其他数据集上也可以做些尝试。
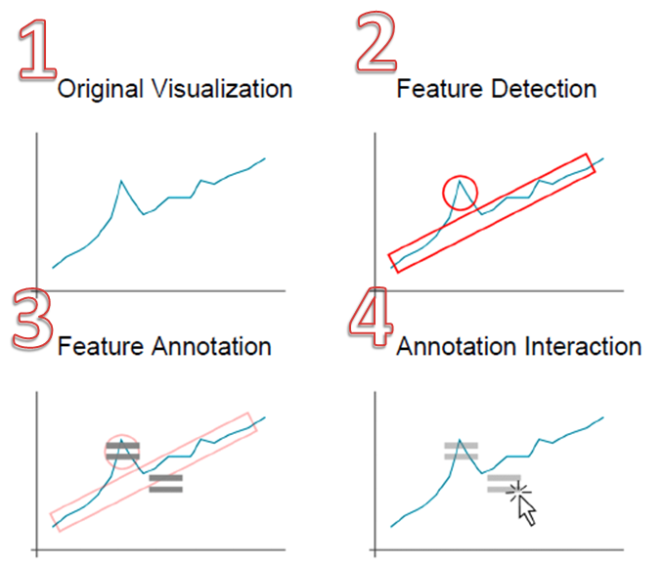
全文可视化的处理可以分为四个部分:
- 初步可视化;
- 特征检测;
- 特征标注;
- 标注交互。
针对特征检测,有三种重要特征,所以需要分别处理。
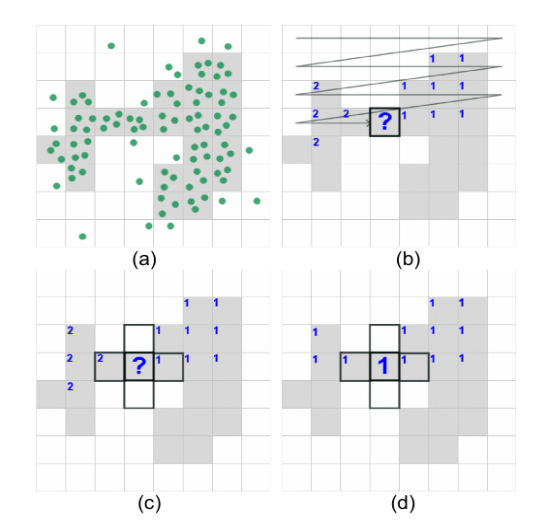
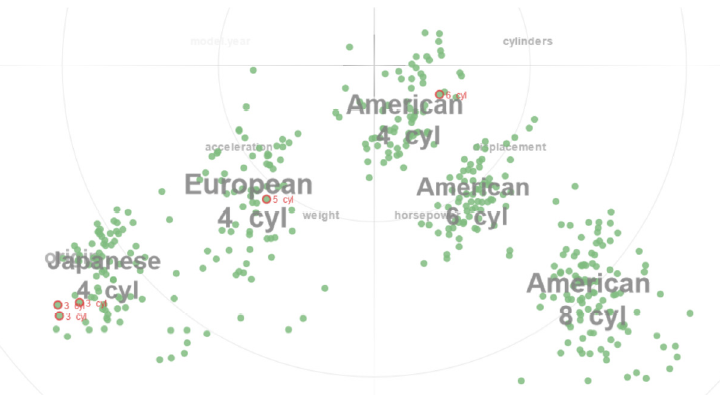
对于聚类来说,本文提出的是一种网格聚类的方法。即先把初步可视化的结果进行网格化,对于点密度比较高的网格定义个名词,叫合格的网格。然后对合格的网格进行优先的扫描,若碰到还未分类的,且四周已有分好类的网格,则把他与四周的合格网格一起归于一类;若四周也没分好,则把这些网格都分为一个新类。这样可以完成一个初步的聚类,当然这样的聚类结果不是很稳定,还需要做很多优化。
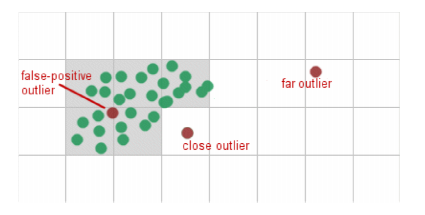
对于异常点来说,只要判断这个点与某个聚类的均值的距离是否大于一定的阈值,即可很简单的识别出异常点。
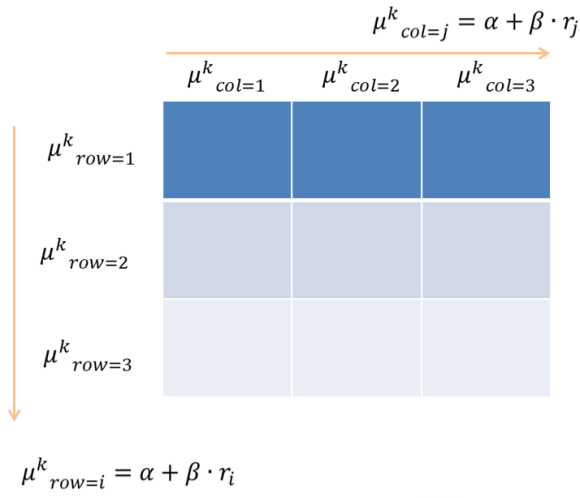
而识别趋势使用的是拟合的方法。即先把网格的每一行每一列的均值计算出来,然后对行和列的均值分别做拟合,然后通过拟合的结果与均值的标准差,来判断这是否有一定的趋势。
这几种检测方法的时间复杂度都在 O(n)和 O(n^2)之间,可以达到很好的效率。
做完特征检测,下面一个比较重要的是对于特征进行标注与交互。
文章提出了一个新的概念——标注模板。一个模板中可以含很多的属性,比如一些数值啊,一些范围,还有标注的形状,变化方式等等。
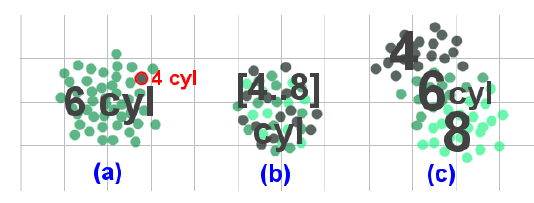
比如,把 XX 年转成 20XX 年的模板是这样的:
{single:”’20’+value”,
range:”’20’+min+’…’+’20’+max”}
对于单一的数值,只需要在前面加上 20 即可,而范围只需要在最大值和最小值前加上 20 即可。
然后以下标注的交互方式就转变成对模板进行操作,通过模板一些属性的变化,形状的变化来达到交互的目的。
目前作者对于标注的交互只支持同语义高亮、保存已有的标注、新建新的标注,之后可以继续做些工作,比如:混合多种标注、支持多层次结构的标注。
用户可以通过标注的自动提示与交互获得很多数据的语义信息,提示自己一步一步去挖掘各种自己需要的东西。整个操作都很简单易行。
接下来这篇文章还有很多工作需要继续,比如提高网格聚类的算法,当然我们也会提出疑惑,他的网格聚类算法加上算法优化的整体时间复杂度和 K-Means 相仿,复杂度只是少了一个迭代次数的系数,但是结果并不比 K-Means 出色,那么这一套检测方法是否有实际价值;之后还有提高用户体验等等工作需要继续展开。
✉️ zjuvis@cad.zju.edu.cn